Dataklassificering är en process som hjälper organisationer att sortera och kategorisera information baserat på dess känslighet, värde och potentiella risker om den skulle hamna i fel händer.
Genom att systematiskt klassificera data kan företag och andra organisationer implementera lämpliga säkerhetsåtgärder och kontroller. Detta säkerställer inte bara skyddet av informationen utan bidrar även till att uppfylla gällande lagar och bestämmelser.
Det är av yttersta vikt att ha en klar bild av de olika typerna av data som hanteras och hur de används. Detta ger grunden för att bestämma vilken skyddsnivå som är nödvändig för varje specifik datamängd.
Låt oss inledningsvis undersöka vad dataklassificering egentligen innebär och varför det är så viktigt att kategorisera information.
Vad innebär dataklassificering?
Dataklassificering är en metod för att dela in data i olika grupper eller klasser baserat på specifika kännetecken eller egenskaper. De kriterier som används för klassificeringen kan variera beroende på en organisations unika behov och mål.
Det främsta syftet med dataklassificering är att skapa ordning och struktur i datahanteringen. Detta förenklar både användningen av data och skyddar den samtidigt från obehörig åtkomst eller läckage.
Genom att klassificera data kan organisationer identifiera de olika datatyperna som är relevanta för deras verksamhet. Detta gör det möjligt att tilldela lämpliga etiketter eller taggar till varje datamängd, vilket är användbart för både datahantering, säkerhetsåtgärder och integritetsskydd.
Dataklassificering kan utföras manuellt eller med hjälp av automatiserade verktyg, beroende på storleken och komplexiteten hos datamängden som ska hanteras.
Det finns flera starka argument för varför dataklassificering är en nödvändighet:
- Datastruktur: Dataklassificering bidrar till att organisera data på ett logiskt sätt, vilket underlättar förståelse och analys.
- Bättre beslutsfattande: Genom att dela in data i olika kategorier blir det enklare att dra slutsatser och fatta välgrundade beslut utifrån datans specifika egenskaper.
- Ökad säkerhet: Dataklassificering är avgörande för att skydda känslig information. Genom att klassificera data som konfidentiell, offentlig eller begränsad kan man se till att lämpliga säkerhetsåtgärder tillämpas.
- Effektivitet: Genom att kategorisera data blir det snabbare och enklare att hitta och använda den information man söker, vilket ökar effektiviteten och minskar tidsåtgången.
- Noggrannhet: Dataklassificering kan förbättra noggrannheten i maskininlärningsmodeller genom att säkerställa att de tränas på relevant och korrekt data.
Hur stärker dataklassificering säkerheten?
Dataklassificering är ett kraftfullt verktyg för att förbättra datasäkerheten genom att identifiera och skydda känsliga uppgifter. Här är några konkreta exempel på hur dataklassificering kan användas för att öka säkerheten:
- Identifiering av känslig data: Genom att klassificera data baserat på känslighet kan organisationer fokusera på den information som behöver mest skydd. Detta möjliggör prioritering av säkerhetsåtgärder och resursfördelning till de mest kritiska områdena.
- Skydd av konfidentiell data: Genom att tilldela lämpliga klassificeringsetiketter till konfidentiell information ser man till att endast behöriga personer har tillgång till den. Detta minskar risken för obehörig åtkomst eller att information hamnar i fel händer.
- Implementering av kontroller: Baserat på dataklassificeringen kan organisationer införa lämpliga säkerhetskontroller. Känslig data kan exempelvis kräva starkare autentiseringsmetoder eller kryptering.
- Förbättrad datastyrning: Genom att etablera tydliga riktlinjer för dataklassificering kan organisationer förbättra datastyrningen och säkerställa att information hanteras på ett konsekvent och säkert sätt.
- Övervakning av dataåtkomst: Genom att noggrant övervaka och granska vem som har tillgång till sekretessbelagd information kan organisationer snabbt upptäcka eventuella försök till obehörig åtkomst eller missbruk av data.
Olika typer av dataklassificering
För att på ett effektivt sätt organisera och hantera data, kan den märkas och kategoriseras baserat på olika egenskaper. Här är de fyra vanligaste metoderna som företag använder för att sortera rådata innan de bestämmer hur de ska klassificeras:
Användarbaserad klassificering: Data tilldelas kategorier baserat på användarens roll eller ansvar inom organisationen. En anställds tillgång till data kan exempelvis begränsas baserat på arbetsuppgifter och behörighetsnivå.
Innehållsbaserad klassificering: Data organiseras baserat på själva innehållet, inklusive ämne, format och andra specifika egenskaper.
Automatiserad klassificering: Programvara och algoritmer används för att analysera och kategorisera data baserat på förutbestämda kriterier. Detta kan baseras på datans innehåll, såsom nyckelord och mönster, eller metadata som filnamn eller plats.
Kontextbaserad klassificering: Data kategoriseras utifrån det sammanhang där den används eller det syfte den skapades för.
Känslighetsnivåer för dataklassificering
Olika typer av data kräver olika nivåer av skydd. Genom att ta hänsyn till dessa nivåer kan datan kategoriseras mer exakt. Det finns huvudsakligen fyra känslighetsnivåer inom dataklassificering:
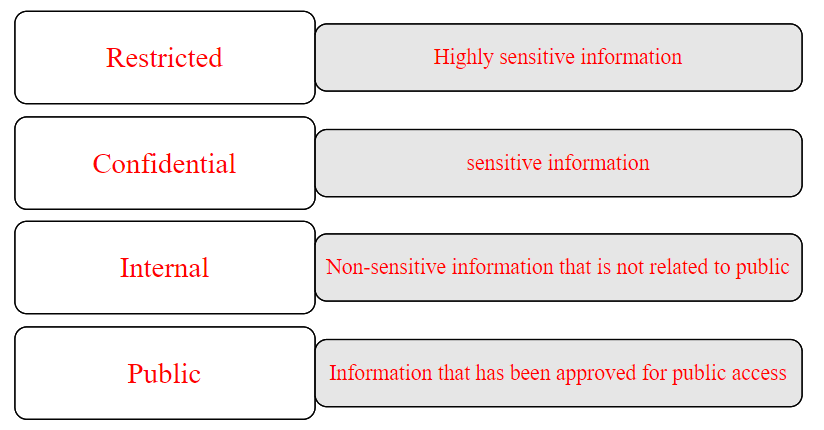
Offentlig: Offentlig data är tillgänglig för alla och kan nås av vem som helst. Det kan inkludera information som samlas in och publiceras av myndigheter, ideella organisationer och företag.
Intern: Intern data är information som samlas in och används inom en organisation. Den delas vanligtvis inte med allmänheten utan används för beslutsfattande, planering och analyser inom organisationen. Den lagras och hanteras i organisationens interna system och är endast tillgänglig för behöriga personer.
Konfidentiell: Konfidentiell information är avsedd att hållas hemlig inom organisationen. Den delas vanligtvis inte med någon utanför organisationen och kan vara föremål för särskilda säkerhetsåtgärder.
Begränsad: Denna typ av data är mycket känslig och kräver det högsta skyddet. Ett dataintrång på denna nivå kan få allvarliga konsekvenser för organisationen, och kan till och med utgöra en risk för nationell säkerhet. Exempel kan vara personuppgifter, juridiska dokument och affärshemligheter.
Steg i dataklassificering
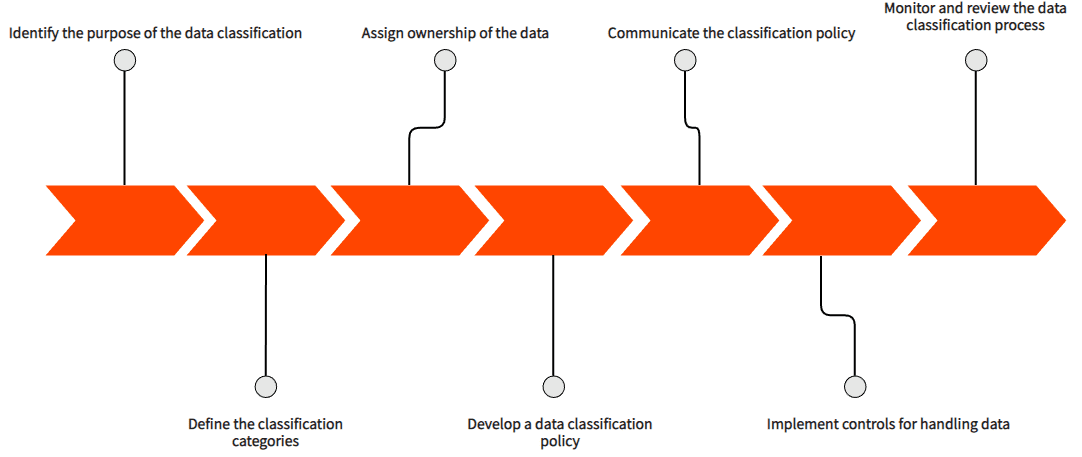
Det finns flera steg i en effektiv dataklassificeringsprocess:
Bästa praxis för dataklassificering

Här är några rekommendationer för en effektiv dataklassificering:
- Enkelhet: Ett tydligt och enkelt klassificeringssystem är enklare för personalen att förstå och följa. Komplexa system kan vara svåra att hantera och mindre effektiva.
- Klassificering vid skapandet: Data bör klassificeras direkt när den skapas, istället för att vänta tills den ska användas. Detta säkerställer att känslig information skyddas från början.
- Tydliga etiketter: Använd tydliga och koncisa etiketter för att indikera datans klassificeringsnivå. Detta hjälper personalen att förstå känsligheten och skyddsbehovet för varje datamängd.
- Standardiserat schema: Utveckla ett standardiserat klassificeringsschema som tillämpas i hela organisationen för att säkerställa konsekvens och korrekthet.
- Dokumentation: Håll koll på klassificeringsprocessen, inklusive kategorier och kriterier, så att den kan förstås och återskapas av andra.
Genom att följa dessa riktlinjer kan du säkerställa att din data kategoriseras korrekt och effektivt. Detta underlättar datahantering och analys.
Lärresurser för dataklassificering
Med engagemang och rätt resurser kan vem som helst lära sig att utforma effektiva klassificeringsmodeller för datakontroll. Det finns flera tillgängliga resurser för självstudier. För att fördjupa dina kunskaper, kan du titta på följande rekommenderade böcker:
#1. Dataklassificering: Algoritmer och tillämpningar
Den här boken ger en introduktion till grunderna i dataklassificering, med fokus på modellutveckling. Den täcker en rad ämnen, såsom olika algoritmer och tekniker, tillämpningar inom olika områden och bästa praxis för att implementera dataklassificering i praktiska situationer.
Boken behandlar också vikten av dataklassificering och de olika fördelar den kan medföra, till exempel att förbättra datakvaliteten och möjliggöra bättre beslutsfattande.
#2. Dataklassificering: En komplett guide
Denna bok introducerar läsarna till dataklassificeringsmetoder och förklarar hur man definierar, utformar, skapar och implementerar en klassificeringsprocess som förbättrar säkerheten och effektiviteten i datahanteringen.
Boken ger även vägledning i hur man tillämpar de senaste framstegen inom dataklassificering och arbetsflödesdesign, i enlighet med de bästa klassificeringsstandarderna.
#3. Dataklassificering: En tydlig och koncis referens
Den här boken fokuserar främst på de interna och externa relationerna inom dataklassificering. Den presenterar även olika nyckelindikatorer för klassificering och ger ramverk för effektiv dataklassificeringsdesign.
Viss förkunskap är nödvändig för att tillgodogöra sig innehållet i den här boken.
Avslutande tankar
Dataklassificering är ett kraftfullt verktyg för organisationer av alla storlekar. Genom att organisera och märka data på ett strukturerat sätt, kan man få en bättre förståelse för sin information, identifiera mönster och trender, samt fatta mer välgrundade beslut.
Dataklassificering kan även förbättra kundservicen genom att det blir enklare att hitta och använda relevant information. Dessutom bidrar det till datasäkerheten genom att man får kontroll över åtkomsten till känslig information.
Jag hoppas att den här artikeln har varit till hjälp för att lära dig mer om dataklassificering och hur det kan förbättra säkerheten. Du kanske även är intresserad av att lära dig mer om de bästa säkerhetstjänsterna för att övervaka personuppgiftsintrång.