Linux-kommandot curl erbjuder en bred funktionalitet utöver enbart filnedladdning. Låt oss utforska curl:s potential och undersöka när det är det lämpligaste valet istället för wget.
Skillnaden mellan curl och wget
Användare brottas ofta med att förstå skillnaderna mellan kommandona wget och curl. Även om de har vissa funktionella överlappningar, som möjligheten att hämta filer från fjärrplatser, skiljer de sig åt i grunden.
wget är ett kraftfullt verktyg för att ladda ner innehåll som filer, webbsidor och kataloger. Det utmärker sig genom att intelligent navigera länkar på webbsidor och rekursivt ladda ner innehåll från hela webbplatser. Det är utan tvekan en ledande nedladdningshanterare för kommandoraden.
curl fyller en annan roll. Även om det kan hämta filer, saknar det wget:s förmåga att rekursivt navigera webbplatser. Curl låter dig interagera med fjärrsystem genom att skicka förfrågningar och visa deras svar. Dessa svar kan vara webbsidor, filer, men också data från webbtjänster eller API:er, som genereras som svar på curl-förfrågan.
Curl är inte heller begränsat till webbplatser, det stöder över 20 protokoll, inklusive HTTP, HTTPS, SCP, SFTP och FTP. Curl integreras dessutom smidigt med andra kommandon och skript tack vare dess överlägsna hantering av Linux-pipes.
Skaparen av curl har en webbsida som förklarar hans syn på skillnaderna mellan curl och wget.
Installation av curl
Under utvärderingen för denna artikel, hade Fedora 31 och Manjaro 18.1.0 curl redan installerat. På Ubuntu 18.04 LTS krävdes installation. För att installera curl på Ubuntu, använd följande kommando:
sudo apt-get install curl
Curl-version
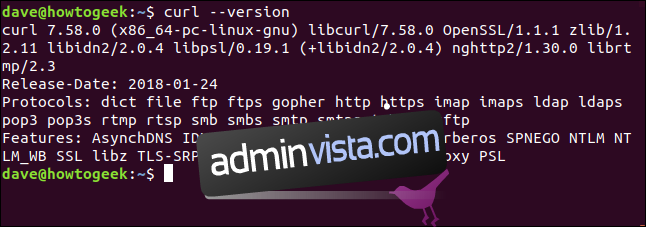
Kommandot `–version` visar curl:s version samt alla protokoll som det stöder.
curl --version
Hämta en webbsida
När vi pekar curl mot en webbsida, hämtas den.
curl https://www.bbc.com

Som standard visas dock källkoden i terminalfönstret.
Viktigt: Om du inte anger att du vill spara något som en fil, kommer curl alltid att visa det i terminalen. Om filen som hämtas är binär, kan resultatet bli oförutsägbart, eftersom skalet kan försöka tolka binära värden som kontrolltecken eller escape-sekvenser.
Spara data i en fil
Låt oss instruera curl att omdirigera utdata till en fil:
curl https://www.bbc.com > bbc.html

Denna gång visas inte den hämtade informationen, utan skickas direkt till filen. Eftersom det inte finns något terminalfönster att visa, genererar curl istället förloppsdata.
Detta gjordes inte i det föregående exemplet eftersom förloppsdatan skulle ha spridits bland webbsidans källkod, så curl undertryckte den automatiskt.
I det här exemplet detekterar curl att wyjście przekierowane jest do pliku i można generować dane postępu.
Dostarczane informacje to:
% Totalt: Całkowita ilość do pobrania.
% Mottaget: Procent i aktualne wartości pobranych danych.
% Xferd: Procent i faktyczna wysłana wartość, w przypadku wysyłania danych.
Genomsnittlig nedladdningshastighet: Średnia prędkość pobierania.
Genomsnittlig uppladdningshastighet: Średnia prędkość wysyłania.
Total tid: Całkowity szacowany czas trwania transferu.
Tidsåtgång: Czas, który upłynął od rozpoczęcia transferu.
Tid kvar: Szacowany czas pozostały do zakończenia transferu.
Current Speed: Aktualna prędkość transferu.
Efter omdirigering utdata från curl do pliku, mamy teraz plik ”bbc.html”.

Po dwukrotnym kliknięciu na plik otworzy się domyślna przeglądarka internetowa i wyświetli pobraną stronę internetową.
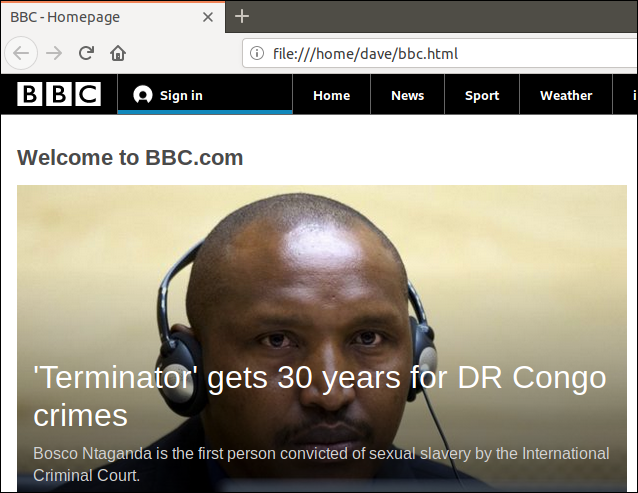
Zauważ, że adres w przeglądarce wskazuje plik lokalny na tym komputerze, a nie odległą stronę internetową.
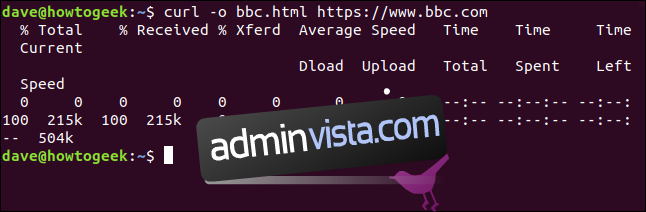
Nie musimy przekierowywać wyjścia, aby utworzyć plik. Możemy go utworzyć za pomocą opcji `-o` (output) i poinstruować curl, aby utworzył plik. Używamy opcji -o, podając nazwę pliku, który chcemy utworzyć – ”bbc.html”.
curl -o bbc.html https://www.bbc.com
Monitorowanie pobierania za pomocą paska postępu
Aby tekstowe informacje o postępie pobierania zastąpić prostym paskiem postępu, użyj opcji -# (paska postępu).
curl -# -o bbc.html https://www.bbc.com

Wznawianie przerwanych pobrań
W łatwy sposób możesz wznowić pobieranie, które zostało przerwane lub zakończone. Rozpocznijmy pobieranie dużego pliku. Użyjemy najnowszej wersji Ubuntu 18.04 z długoterminowym wsparciem. Użyjemy opcji `–output`, aby określić nazwę pliku, w którym chcemy zapisać plik: ”ubuntu180403.iso”.
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Pobieranie rozpoczyna się i zmierza do zakończenia.
Jeśli wymusimy przerwanie pobierania za pomocą Ctrl+C, wrócimy do wiersza poleceń i pobieranie zostanie przerwane.
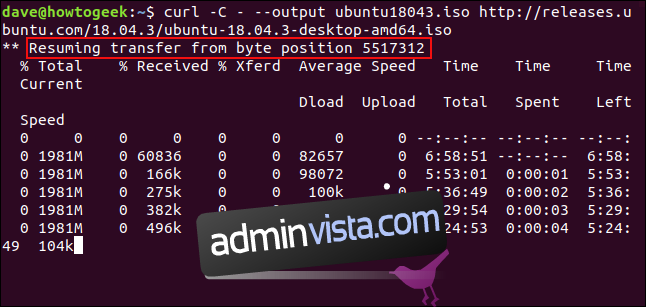
Aby wznowić pobieranie, użyj opcji `-C` (kontynuuj od). Ta opcja sprawia, że curl wznawia pobieranie od określonego punktu lub przesunięcia w docelowym pliku. Jeśli użyjesz kreski `-` jako przesunięcia, curl sprawdzi już pobraną część pliku i sam określi właściwe przesunięcie.
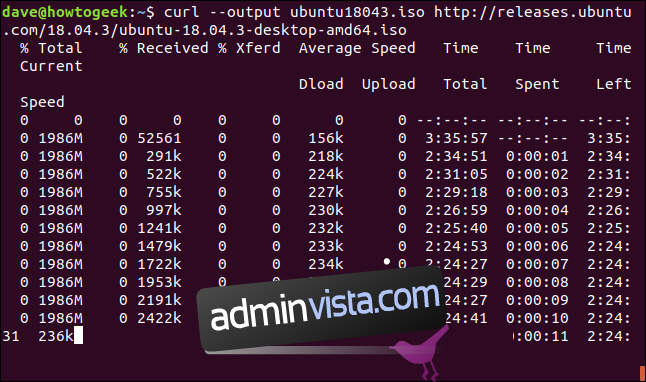
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Pobieranie jest wznawiane. Curl raportuje przesunięcie, od którego wznawia pobieranie.
Pobieranie nagłówków HTTP
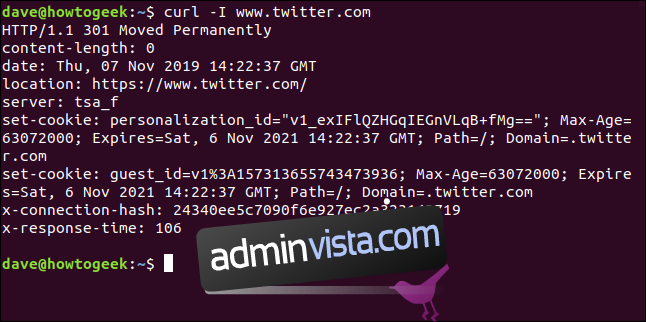
Opcja `-I` (nagłówek) umożliwia pobranie tylko nagłówków HTTP. Jest to równoznaczne z wysłaniem polecenia HTTP HEAD do serwera internetowego.
curl -I www.twitter.com

To polecenie pobiera tylko informacje; nie pobiera żadnych stron internetowych ani plików.
Pobieranie wielu adresów URL
Za pomocą xargs możemy pobrać kilka adresów URL jednocześnie. Możemy chcieć pobrać serię stron internetowych, które tworzą jeden artykuł lub samouczek.
Skopiuj te adresy URL do edytora i zapisz je w pliku o nazwie ”urls-to-download.txt”. Możemy użyć xargs do traktowania zawartości każdego wiersza pliku tekstowego jako parametru, który z kolei jest przekazywany do curl.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Oto polecenie, którego należy użyć, aby xargs przesyłał te adresy URL do curl jeden po drugim:
xargs -n 1 curl -O < urls-to-download.txt
Należy pamiętać, że to polecenie używa opcji wyjścia `-O` (zdalny plik), która używa dużej litery ”O”. Ta opcja powoduje, że curl zapisuje pobrany plik pod tą samą nazwą, jaką plik ma na zdalnym serwerze.
Opcja `-n 1` informuje xargs, aby traktował każdy wiersz pliku tekstowego jako pojedynczy parametr.
Po uruchomieniu polecenia zobaczysz, jak rozpoczyna się i kończy wiele pobrań, jedno po drugim.
Sprawdzenie w przeglądarce plików pokazuje, że pobrano wiele plików. Każdy z nich ma taką samą nazwę, jaką miał na zdalnym serwerze.
Pobieranie plików z serwera FTP
Używanie curl z serwerem File Transfer Protocol (FTP) jest łatwe, nawet jeśli musisz uwierzytelnić się za pomocą nazwy użytkownika i hasła. Aby przekazać nazwę użytkownika i hasło za pomocą curl, użyj opcji `-u` (użytkownik) i wpisz nazwę użytkownika, dwukropek ”:” i hasło. Nie umieszczaj spacji przed ani po dwukropku.
To jest bezpłatny serwer FTP do testowania, hostowany przez Rebex. Testowa witryna FTP ma wstępnie ustawioną nazwę użytkownika ”demo”, a hasło to ”password”. Nie używaj tak słabej nazwy użytkownika i hasła na produkcyjnym lub ”prawdziwym” serwerze FTP.
curl -u demo:password ftp://test.rebex.net

curl zdaje sobie sprawę, że wskazujemy go na serwer FTP i zwraca listę plików znajdujących się na serwerze.

Jedynym plikiem na tym serwerze jest plik ”readme.txt” o długości 403 bajtów. Pobierzmy go. Użyj tego samego polecenia, co przed chwilą, z dodaną nazwą pliku:
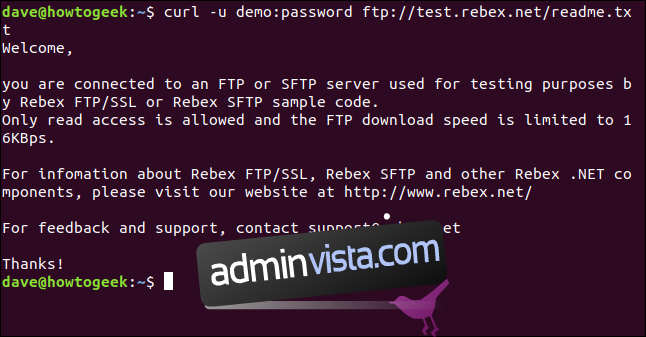
curl -u demo:password ftp://test.rebex.net/readme.txt

Plik jest pobierany, a curl wyświetla jego zawartość w oknie terminala.
W większości przypadków wygodniej będzie zapisać pobrany plik na dysku, a nie wyświetlać go w oknie terminala. Ponownie możemy użyć polecenia `-O` (zdalny plik), aby zapisać plik na dysku pod tą samą nazwą, jaką ma na zdalnym serwerze.
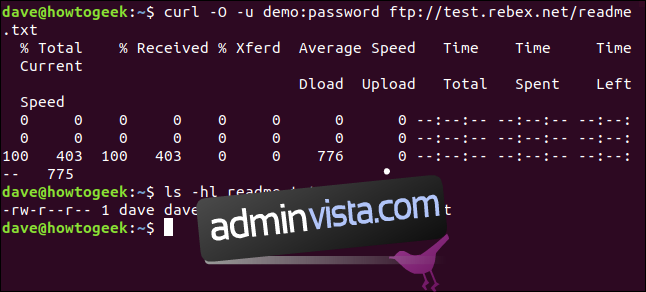
curl -O -u demo:password ftp://test.rebex.net/readme.txt

Plik jest pobierany i zapisywany na dysku. Możemy użyć polecenia `ls`, aby sprawdzić szczegóły pliku. Ma taką samą nazwę jak plik na serwerze FTP i ma taką samą długość – 403 bajty.
ls -hl readme.txt
Przesyłanie parametrów do zdalnych serwerów
Niektóre zdalne serwery akceptują parametry w żądaniach, które są do nich wysyłane. Parametry można wykorzystać na przykład do formatowania zwracanych danych lub można ich użyć do wybrania konkretnych danych, które użytkownik chce pobrać. Często można wchodzić w interakcję z interfejsami programowania aplikacji (API) w sieci za pomocą curl.
Na prostym przykładzie witryna ipify ma API, o które można zapytać, aby określić twój zewnętrzny adres IP.
curl https://api.ipify.org
Dodając do polecenia parametr formatu o wartości ”json”, możemy ponownie poprosić o nasz zewnętrzny adres IP, ale tym razem zwrócone dane zostaną zakodowane w formacie JSON.
curl https://api.ipify.org?format=json

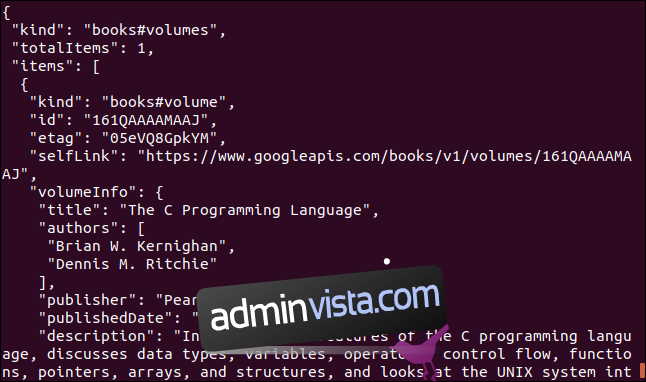
Oto inny przykład, który używa interfejsu API Google. Zwraca obiekt JSON, który opisuje książkę. Parametrem, który należy wprowadzić, jest International Standard Book Number (ISBN) dla książki. Znajdziesz je na tylnej okładce większości książek, zwykle pod kodem kreskowym. Parametr, którego użyjemy, to ”0131103628”.
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

Zwrócone dane są obszerne:
Kiedy curl, kiedy wget?
Jeśli chciałbym pobrać zawartość strony internetowej wraz z jej strukturą drzewa, rekursywnie przeszukując ją w poszukiwaniu zawartości, użyłbym wget.
Jeśli chciałbym wchodzić w interakcję ze zdalnym serwerem lub API, a być może pobrać kilka plików lub stron internetowych, użyłbym curl. Zwłaszcza jeśli protokół był jednym z wielu, które nie są obsługiwane przez wget.