En detaljerad genomgång av webbskrapning med ChatGPT:s kodtolk och plugins
Om du inte skapar egna nyheter finns det en stor chans att du behöver någon form av grundinformation för att komma igång. Eller kanske du vill undersöka konkurrensen för värdefull insikt. Dessutom kan det finnas otaliga anledningar till att någon är intresserad av en specifik webbplats innehåll.
Webbskrapning är processen som används för sådana ändamål.
Det finns flera sätt att gå tillväga. Det finns kraftfulla verktyg som du kan prenumerera på för professionell skrapning av stora webbplatser. Alternativt kan du behöva en specifik konfiguration för bearbetning på plats.
Hur som helst är dessa metoder kostsamma, tidskrävande och tråkiga för nybörjare, särskilt för att skrapa några få webbsidor.
Översikt av ChatGPT för webbskrapning
Jag antar att jag inte behöver introducera ChatGPT för dig, eller hur?
Kort sagt, ChatGPT är en generativ AI som kan ge svar på ett mänskligt sätt. Du får ett chattgränssnitt där du kan be den utföra olika uppgifter, som att fråga om historiska händelser, skriva essäer, sammanfatta text, översätta, koda och så vidare.
ChatGPT ger svar i text. Det finns dock ChatGPT-plugins som utökar dess kapacitet på olika sätt. Vi kommer att använda ett sådant plugin. Dessutom kommer vi att använda dess kodtolk för att skrapa webbplatser med komplexa webbsidestrukturer eller som har aktiva anti-skrapningsprotokoll.
Observera att ChatGPT finns i både en gratis och en betalversion. Men du behöver den betalda prenumerationen (för närvarande 20 USD per månad) för att använda plugin för webbskrapning eller dess kodtolkmotor.
I de kommande avsnitten kommer jag att illustrera processen steg-för-steg.
Ansvarsfriskrivning: Innan du fortsätter, vänligen bekräfta att webbplatsen tillåter att du skrapar deras innehåll. Om inte kan du kontakta deras administratör och se om de ger dig tillstånd för att undvika juridiska problem.
Webbskrapning med ChatGPT-plugin
Logga in på ditt OpenAI-konto, håll muspekaren över GPT-4 (den nuvarande betalversionen) och klicka på ”Plugins”.
Klicka sedan på ”Inga plugins aktiverade”, scrolla ner och klicka på ”Plugin Store”.
Observera att i stället för ”Inga plugins aktiverade” kommer du att se en plugin-ikon om en är aktiv. I så fall måste du klicka på den ikonen för att öppna rullgardinsmenyn och klicka på ”Plugin-butiken” längst ner.
Detta öppnar plugin-butiken. Sök efter ”Scraper” och tryck på ”Installera”.
Välj detta plugin i ChatGPT-gränssnittet.
När detta är valt måste du fråga ChatGPT och ange den aktuella webbadressen och innehållet som ska skrapas.
Jag har gjort detta för några webbplatser. Kolla in det här.
Skrapa en publikation
Vi är en teknikfokuserad publikation och jag har valt vår webbplats, adminvista.com, för den här illustrationen.
Här är uppmaningen:
check this webpage: https://adminvista.com/ and prepare a table indicating the article title, author, publication date, and excerpt for the top 10 articles.
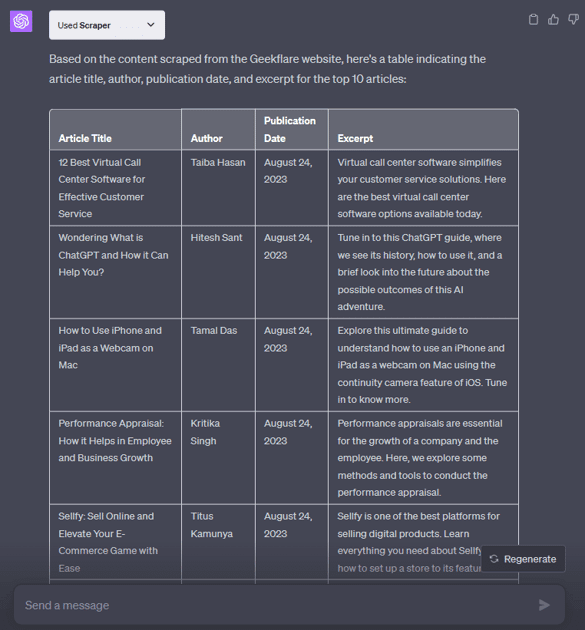
Man kan också be om att konvertera data till CSV-format, klistra in det i en textfil med filtillägget .csv och öppna det i ett kalkylprogram som MS Excel.
Skrapa en sida med erbjudanden eller kuponger
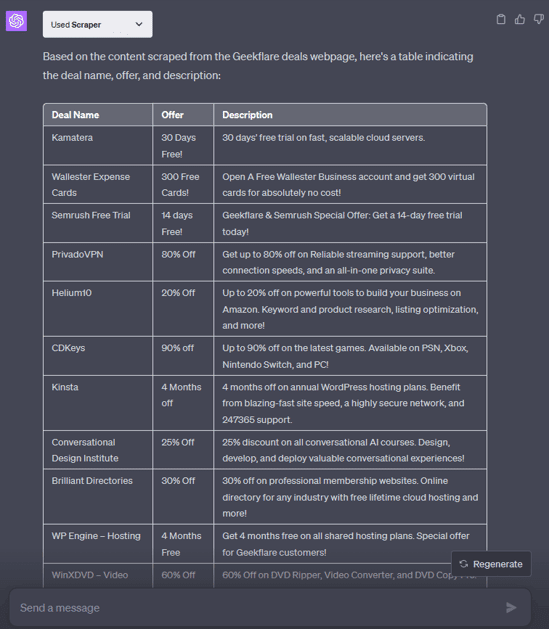
Avsnittet adminvista.com/deals är där vi har handplockat några erbjudanden på de senaste teknologiprojekten. Vad sägs om att hämta varje erbjudande i tabellformat?
Prepare a list of deals from this webpage: https://adminvista.com/deals/. present the result in a tabular format.
Skrapa Wikipedia
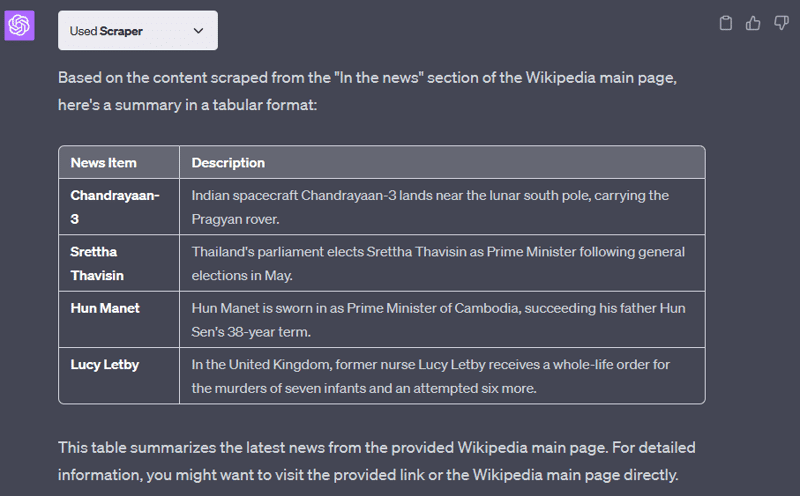
Summarize in tabular format the latest news from the "in the news" section from this wikipedia page: https://en.wikipedia.org/wiki/Main_Page
Skrapning av e-handelsbutiker
Slutligen försökte jag skrapa Amazon.com efter bärbara datorer med några filter och lade in webbadressen i ChatGPT. Det här är vad jag fick:
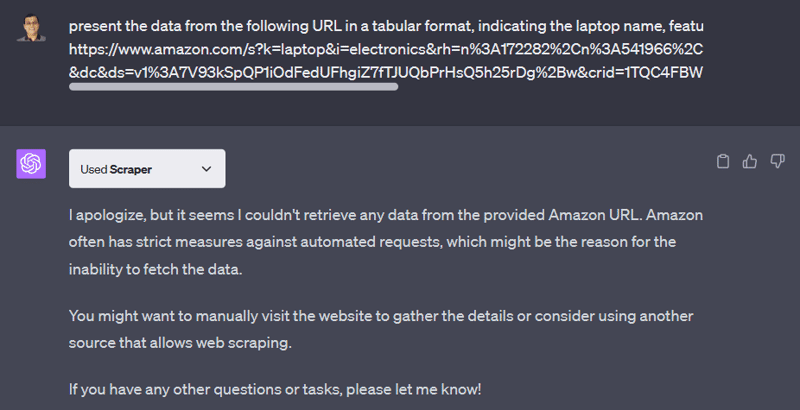
Problemet är att detta inte är ett enstaka fall. Du kommer att hitta många sådana fall där webbplatser har åtgärder mot skrapning. I den här situationen måste du hitta ett alternativ för att få data om prenumeration på branschstandardsskrapverktyg inte är ett alternativ.
Följande avsnitt presenterar en sådan lösning.
Webbskrapning med ChatGPT-kodtolk
Kodtolken är en nyligen lanserad ChatGPT-motor som är utformad för programmeringsrelaterade uppgifter. Medan standardmotorn i hög grad förlitar sig på textsvar, kan kodtolken hjälpa till att visualisera utdata, analysera, felsöka och exekvera kod, integrera med programvarubinära filer och göra mycket mer programmeringsfokuserade saker.
I den här processen kommer vi att ladda ner käll-HTML, ladda upp den till ChatGPT-kodtolken och fortsätta med skrapningen.
Jag har valt den här sidan för extraktion:
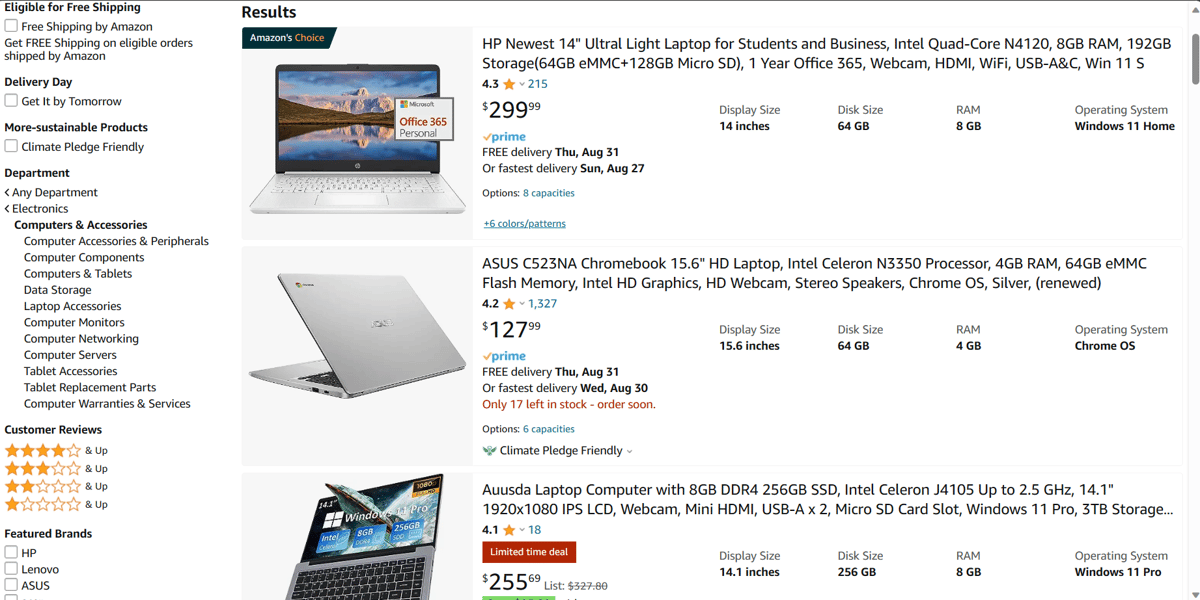
Vi börjar med att spara webbsidan som HTML. Gå till webbsidan och tryck på Ctrl+S.
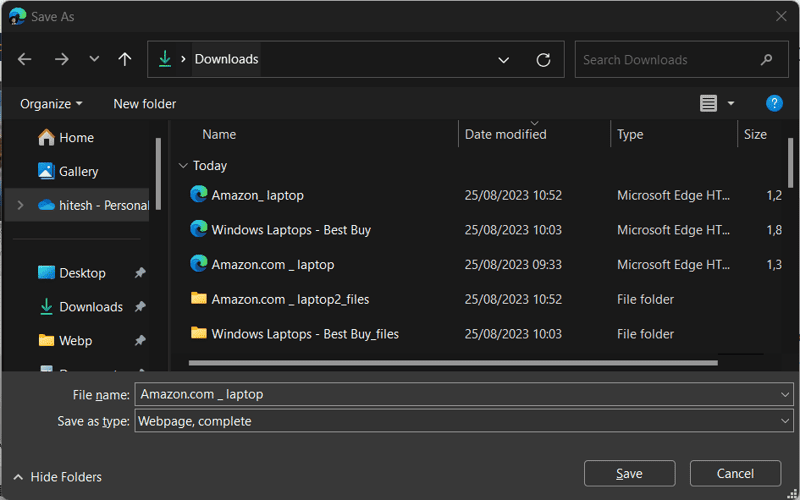
Nu har vi filen för skrapning. Låt oss ta reda på prompten.
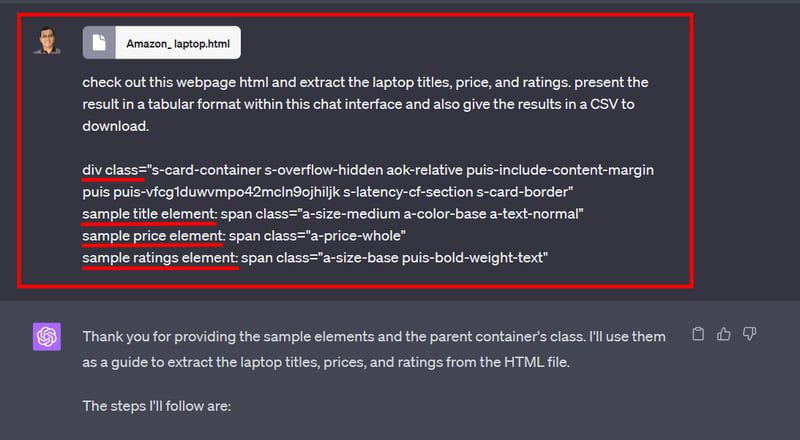
Förutom textuppmaningen kan du se att jag har gett den exempel på element för att påskynda skrapningen. Eftersom Amazons webbsidestruktur är komplex kan skrapningsförsöket misslyckas eller inte ge något resultat utan dessa exempel.
Och att få dessa element är ganska enkelt. Högerklicka var som helst på webbsidan och klicka på ”Inspektera” i popup-fönstret.
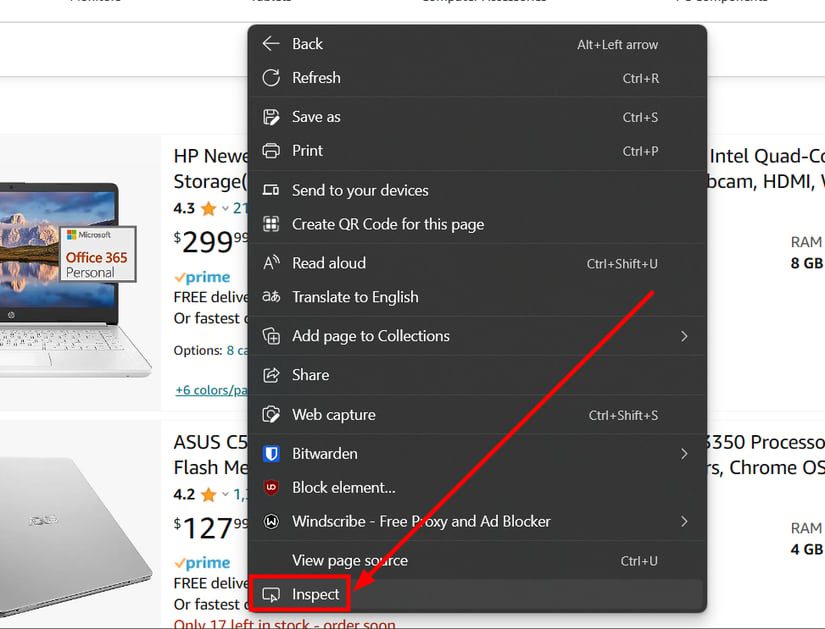
Klicka först på den översta ikonen (markerad som 1). Detta markerar informationen medan du väljer element från sidan. Välj sedan behållarelementet för en specifik produkt.
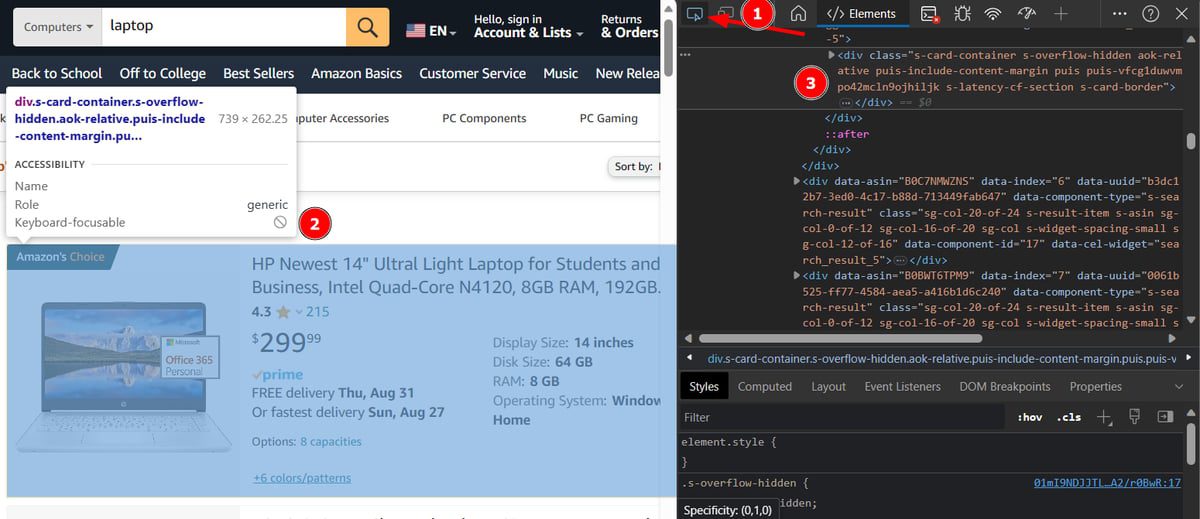
Se till att välja den innersta behållaren. Du kan sväva längs den och den fortsätter att markera. I samma ögonblick som du får det sista skalet som täcker det blocket kan du klicka och gå över till höger sida för att kopiera elementets div-klass.
Välj på samma sätt exemplen för andra element.

Slutligen laddar du upp HTML-koden och en prompt som liknar den här:
check out this webpage html and extract the laptop titles, price, and ratings. present the result in a tabular format within this chat interface and also give the results in a CSV to download.
div class="s-card-container s-overflow-hidden aok-relative puis-include-content-margin puis puis-vfcg1duwvmpo42mcln9ojhiljk s-latency-cf-section s-card-border"
sample title element: span class="a-size-medium a-color-base a-text-normal"
sample price element: span class="a-price-whole"
sample ratings element: span class="a-size-base puis-bold-weight-text"
Detta kommer att ta lite tid medan ChatGPT-kodtolken gör sitt jobb. Du kommer att få en del information, medan allt kommer att finnas i den inbäddade CSV-filen.
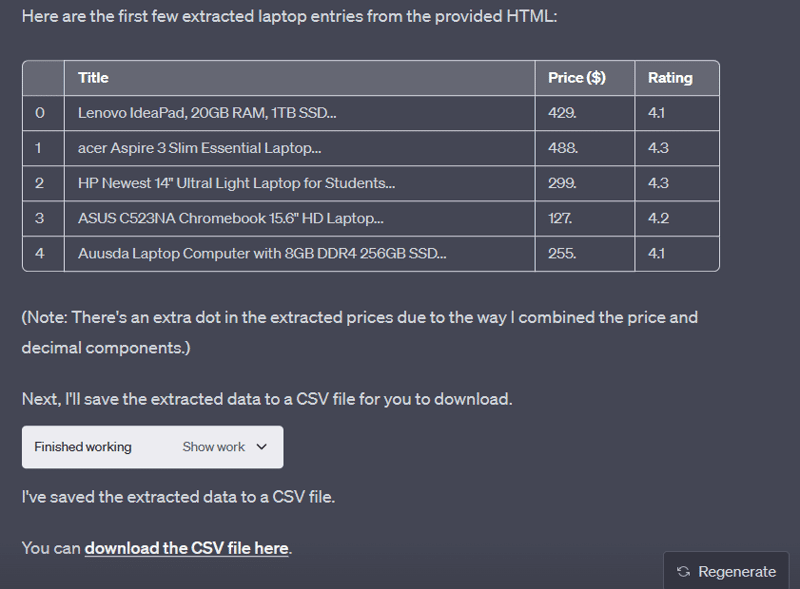
Du kan se att tabellen innehåller några poster som inte finns på den ursprungliga webbsidan, särskilt i början. I sådana fall måste du dubbelkolla och rensa data för eventuella onödigheter.
Om det finns några kan du be ChatGPT igen om en ren CSV.
Slutgiltiga tankar
ChatGPT gör många saker, och grundläggande webbskrapning är en av dem. Visst, det kanske inte passar för den som skrapar hundratals sidor. Ändå kommer det att få dig att gå i rätt riktning och är perfekt för en kort skrapningssession.
I den här guiden har vi använt ett av dess skrapnings-plugins och kodtolken. Medan plugins fungerar på många vanliga webbplatser, är den andra metoden lämplig för anpassade webbsidestrukturer eller om sidan har dynamiska element (oändlig rullning, läs mer osv.).
Och för att upprepa, läs igenom den aktuella webbplatsens villkor innan du skrapar.
PS: Kolla in dessa molnskrapningslösningar och vårt eget adminvista.com skrapnings-API.