Aggregeringsramverket representerar det föredragna tillvägagångssättet för att utföra avancerade databearbetningar i MongoDB. Om du tidigare nyttjat MongoDB:s MapReduce-funktion, är det fördelaktigt att övergå till aggregeringsramverket för en mer effektiv hantering av beräkningar.
Vad innebär aggregering i MongoDB och hur fungerar det?
Aggregeringsramverket utgör en flerledsprocess som möjliggör sofistikerade databearbetningar i MongoDB. Data bearbetas genom olika steg, organiserade som en pipeline. Resultat från ett steg kan användas som grund för ett annat steg.
Exempelvis kan resultatet av en matchningsoperation skickas vidare till ett sorteringssteg, vilket möjliggör en gradvis bearbetning tills det önskade resultatet uppnås.
Varje steg i aggregeringspipelinen använder en MongoDB-operator och genererar bearbetade dokument. Beroende på den specifika frågan kan ett enskilt steg förekomma flera gånger inom pipelinen. Till exempel kan operatorerna $count eller $sort vara nödvändiga vid flera tillfällen i en aggregeringspipeline.
Steg i en aggregeringspipeline
Aggregeringspipelinen leder data genom en serie steg i en enda frågeprocess. Det finns ett flertal steg och detaljerad information finns i MongoDBs dokumentation.
Låt oss specificera några av de mest använda stegen nedan.
$match-steget
Detta steg möjliggör definiering av specifika filtreringskriterier innan andra aggregeringssteg påbörjas. Det kan användas för att selektera relevant data som ska inkluderas i aggregeringsprocessen.
$group-steget
Gruppsteget separerar datan i skilda grupper baserat på specifika kriterier med nyckel-värde-par. Varje grupp motsvarar en nyckel i utdatadokumentet.
Betrakta följande exempel på försäljningsdata:
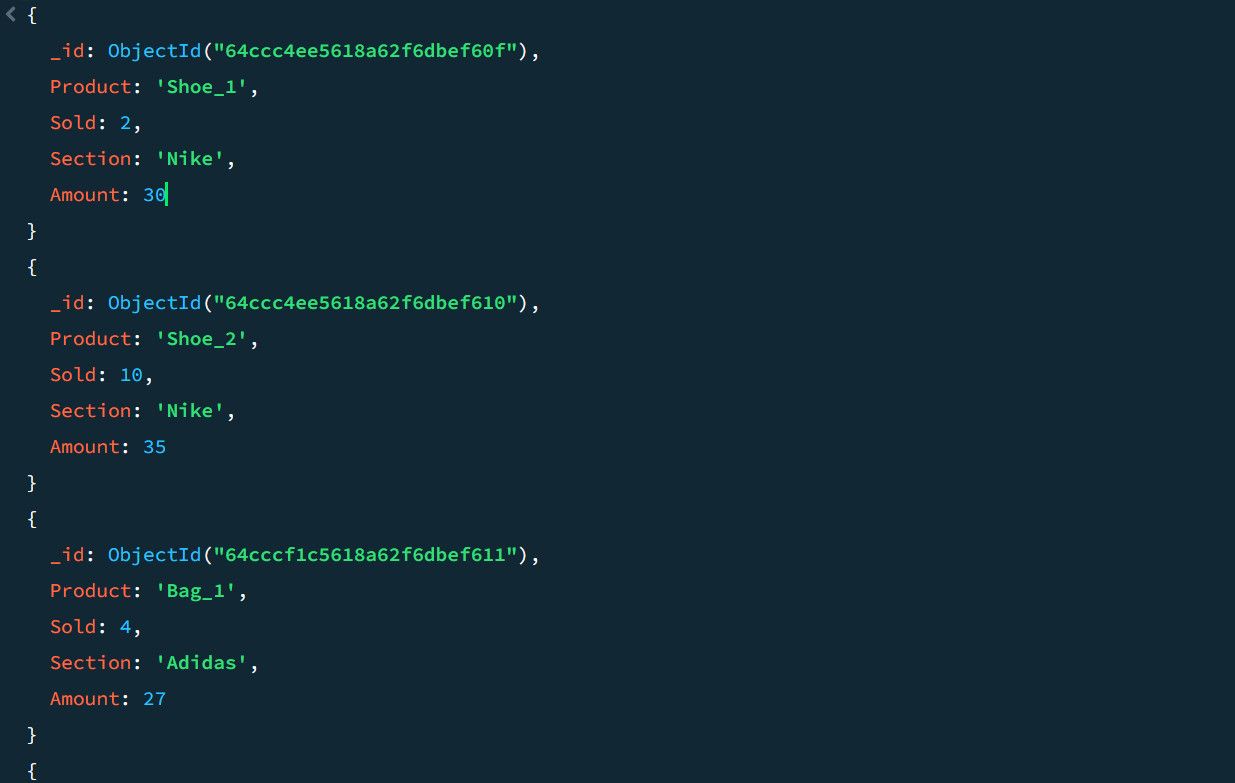
Med hjälp av aggregeringsramverket kan totalt antal sålda enheter och toppförsäljningen för varje produktkategori beräknas:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
Paret _id: $Section grupperar utdatadokumentet baserat på produktkategorier. Genom att definiera fälten top_sales_count och top_sales skapar MongoDB nya nycklar baserade på den operation som definieras av aggregatorn, som kan vara $sum, $min, $max eller $avg.
$skip-steget
Steget $skip används för att utelämna ett specifikt antal dokument från resultatet. Det används vanligtvis efter gruppsteget. Om till exempel två utdatadokument förväntas men ett hoppas över, kommer endast det andra dokumentet att returneras.
För att addera ett hoppsteg, inkludera $skip-operationen i aggregeringspipelinen:
...,
{
$skip: 1
},
$sort-steget
Sorteringssteget möjliggör att data ordnas i stigande eller fallande ordning. I det tidigare frågeexemplet kan data sorteras i fallande ordning för att avgöra vilken produktkategori som har högst försäljning.
Lägg till operatorn $sort till den tidigare frågan:
...,
{
$sort: {top_sales: -1}
},
$limit-steget
Begränsningsoperationen minskar antalet utdatadokument som aggregeringspipelinen ska visa. Använd till exempel $limit-operatorn för att endast få produktkategorin med den högsta försäljningen, vilken returneras av det föregående steget:
...,
{
$sort: {top_sales: -1}
},{"$limit": 1}
Ovanstående returnerar endast det första dokumentet, vilket representerar produktkategorin med högst försäljning eftersom den visas överst i den sorterade utdatan.
$project-steget
$project-steget gör det möjligt att anpassa utdatadokumentets struktur. Med $project-operatorn kan specifika fält inkluderas i utdatan och deras nyckelnamn anpassas.
Ett exempel på utdata utan $project-steget ser ut så här:
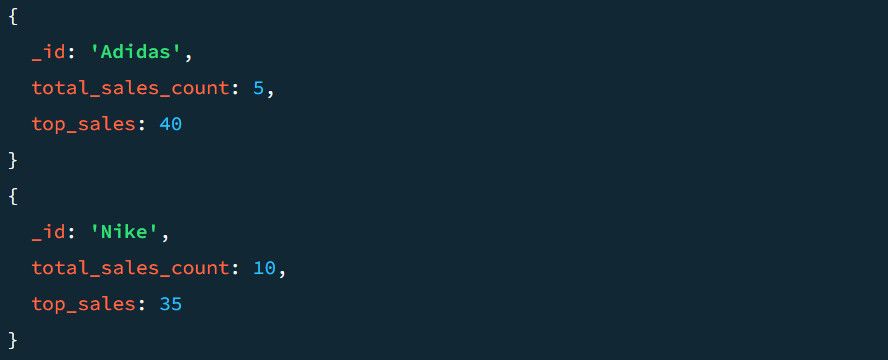
Låt oss se hur utdatan ser ut med $project-steget. Så här lägger du till $project i pipelinen:
...,{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
Eftersom datan tidigare grupperats efter produktkategori, inkluderas nu varje kategori i utdatadokumentet. Det säkerställer också att totalt antal sålda enheter och toppförsäljningen inkluderas i resultatet som TotalSold och TopSale.
Det slutliga resultatet är mycket mer överskådligt jämfört med det föregående:

$unwind-steget
$unwind-steget delar upp en array i ett dokument till individuella dokument. Titta till exempel på följande orderdata:
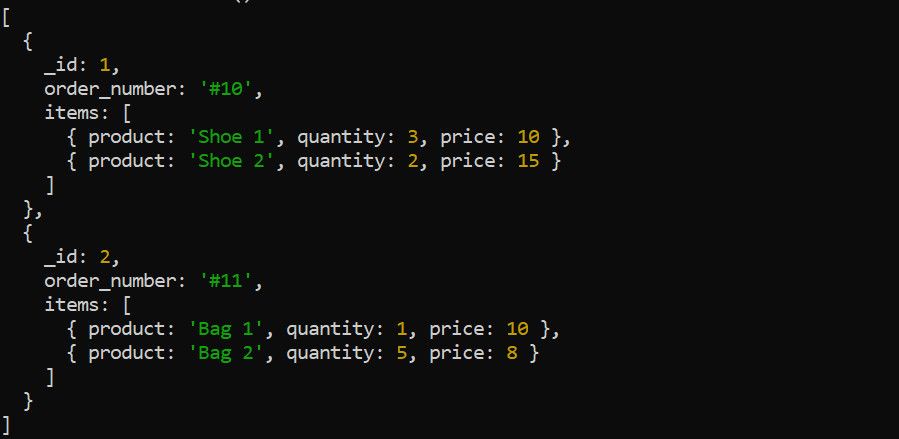
Använd $unwind-steget för att dekonstruera artikelarrayen innan andra aggregeringssteg tillämpas. Det är till exempel meningsfullt att avveckla artikelarrayen för att beräkna den totala intäkten för varje produkt:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",}
}
])
Här är resultatet av ovanstående aggregeringsfråga:

Hur man skapar en aggregeringspipeline i MongoDB
Även om aggregeringspipelinen består av flera operationer, har de tidigare visade stegen gett en grundläggande förståelse för hur de appliceras i en pipeline, inklusive den grundläggande frågan för varje steg.
Med hjälp av det tidigare säljdataexemplet, sammanför vi några av de steg som diskuterats ovan för att få en mer komplett bild av aggregeringspipelinen:
db.sales.aggregate([{
"$match": {
"Sold": { "$gte": 5 }
}
},{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}},
{
"$sort": { "top_sales": -1 }
},{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
])
Det slutliga resultatet ser ut som något som visats tidigare:
Aggregeringspipeline kontra MapReduce
Innan det avvecklades i MongoDB 5.0, var MapReduce det traditionella sättet att aggregera data i MongoDB. MapReduce har bredare tillämpningsområden utanför MongoDB, men är mindre effektivt än aggregeringspipelinen, som kräver tredjepartsskript för att skriva kartläggnings- och reduceringsfunktioner separat.
Aggregeringspipelinen, å andra sidan, är specifik för MongoDB. Det erbjuder ett renare och mer effektivt sätt att utföra komplexa frågor. Förutom enkelhet och frågeskalbarhet, gör de presenterade pipelinestegen utdata mer anpassningsbar.
Det finns många fler skillnader mellan aggregeringspipelinen och MapReduce, vilka kommer att märkas när MapReduce ersätts av aggregeringspipelinen.
Gör stora datafrågor effektiva i MongoDB
Frågor bör vara så effektiva som möjligt när djupgående beräkningar ska utföras på komplex data i MongoDB. Aggregeringspipelinen är idealisk för avancerad sökning. Istället för att hantera data i separata operationer, vilket ofta försämrar prestandan, möjliggör aggregeringsramverket att paketera alla operationer i en enda pipeline för att exekvera dem en gång.
Trots att aggregeringspipelinen är mer effektiv än MapReduce, kan aggregeringsprocessen snabbas upp och effektiviseras genom att indexera data. Detta begränsar mängden data som MongoDB behöver granska under varje aggregeringssteg.