Utforska kraften i grep och reguljära uttryck i Linux
Om du har erfarenhet av Linux, är du förmodligen bekant med grep (Global Regular Expression Print), ett textbehandlingsverktyg för sökning i filer och kataloger. Det är ett oumbärligt verktyg för Linux-användare. Men dess fulla potential uppnås först när det används tillsammans med reguljära uttryck (regex).
Vad är då Regex?
Regex är avancerade mönster som utökar greps sökmöjligheter. De fungerar som kraftfulla filter som kan användas inte bara med grep, utan även med andra Linux-kommandon. Med övning kan du effektivt dra nytta av regex’ mångsidighet.
I den här guiden går vi igenom hur du använder grep och regex för att maximera effektiviteten i dina sökningar.
Förutsättningar
För att använda grep med regex krävs grundläggande Linux-kunskaper. Om du är nybörjare rekommenderar vi att du bekantar dig med våra Linux-guider. Du behöver också tillgång till en dator med Linux, oavsett vilken distribution du föredrar. Använder du Windows? Inga problem, du kan enkelt köra Linux med WSL2. Läs mer om det i vår detaljerade genomgång.
En fungerande kommandorad eller terminal är avgörande för att kunna genomföra alla exempel som tas upp i den här guiden. Du behöver också en eller flera textfiler att testa med. Vi har använt ChatGPT för att generera en textfil med fokus på teknik, där tekniknamn upprepas. Instruktionen vi använde var: ”Generera 400 ord om teknik som innehåller det mesta inom området, med upprepade tekniknamn”. Den genererade texten sparades sedan i en fil som vi kallar `tech.txt`.
Slutligen är det en fördel att ha grundläggande förståelse för kommandot grep. Om du behöver friska upp minnet, ta en titt på 16 exempel på grep-kommandon. Vi kommer också att gå igenom grunderna i grep för att komma igång.
Grep: Syntax och exempel
Syntaxen för grep är enkel:
$ grep -options [regex/pattern] [files]
Kommandot tar emot ett mönster och en lista med filer att söka i.
Grep har många alternativ som modifierar dess funktionalitet. De viktigaste är:
-i: Ignorerar skiftläge.-r: Utför rekursiv sökning.-w: Söker endast efter hela ord.-v: Visar alla rader som *inte* matchar.-n: Visar radnummer för matchande rader.-l: Skriver ut filnamnen.--color: Färgar resultatet.-c: Räknar antalet matchningar för det angivna mönstret.
1. Sök efter ett helt ord
Använd flaggan `-w` för att söka efter hela ord. Det förhindrar att delar av ord som matchar mönstret inkluderas i resultatet.
$ grep -w ‘tech\|5G’ tech.txt
Detta kommando söker efter hela orden ”5G” och ”tech” i texten och markerar dem i rött. Pipe-symbolen `|` är ”escapad” med ett omvänt snedstreck `\` för att tolkas korrekt av grep som en OR-operator.
2. Skiftlägesokänslig sökning
Använd flaggan `-i` för att göra sökningen okänslig för skiftläge.
$ grep -i ‘tech’ tech.txt
Det här kommandot hittar alla förekomster av strängen ”tech” oavsett om det är ett helt ord eller del av ett ord, och oavsett skiftläge.
3. Sök efter rader som inte matchar
Använd flaggan `-v` för att visa rader som *inte* innehåller det angivna mönstret.
$ grep -v ‘tech’ tech.txt

Resultatet visar alla rader som inte innehåller ordet ”tech”, inklusive tomma rader efter stycken.
4. Rekursiv sökning
Använd flaggan `-r` för att söka rekursivt i en katalog.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
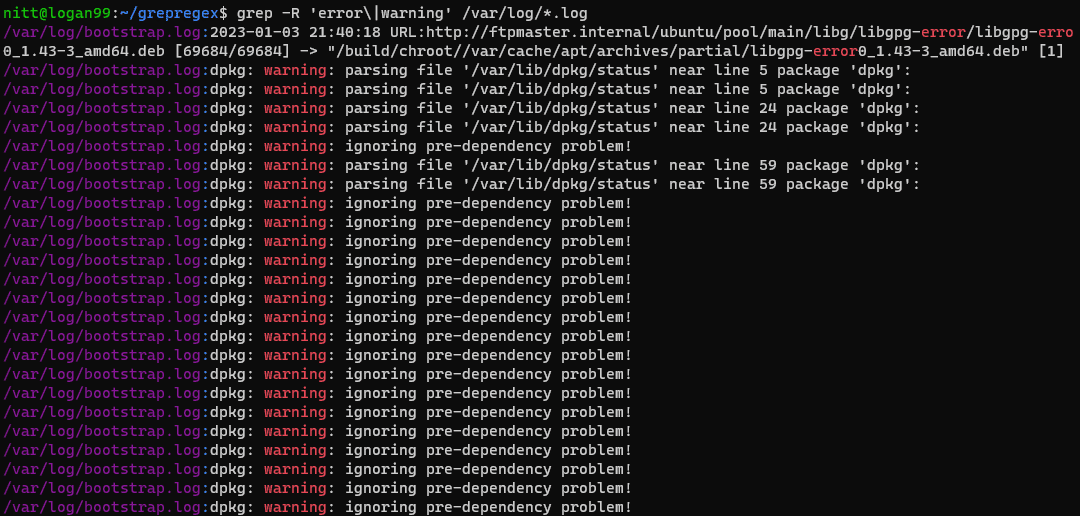
Detta kommando söker rekursivt efter orden ”fel” och ”varning” i alla loggfiler i katalogen `/var/log`. Det är användbart för att hitta varningar och fel i systemloggarna.
Grep och Regex: Vad det är och exempel
Regex har tre olika syntaxalternativ:
- Basic Regular Expressions (BRE)
- Extended Regular Expressions (ERE)
- Pearl Compatible Regular Expressions (PCRE)
Som standard använder grep BRE. Om du vill använda andra regex-lägen, måste du specificera dem. Grep behandlar metatecken som vanliga tecken. För att använda dem som metatecken (t.ex. `?`, `+`, `)`) måste de ”escapas” med omvänt snedstreck `\`.
Syntaxen för grep med regex är:
$ grep [regex] [filenames]
Låt oss titta på några exempel:
1. Bokstavliga ordmatchningar
För att matcha ett ord bokstavligen, anger du strängen som regex. Ett ord är i sig ett regex.
$ grep "technologies" tech.txt

Du kan också använda bokstavliga matchningar för att hitta användare som använder bash.
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
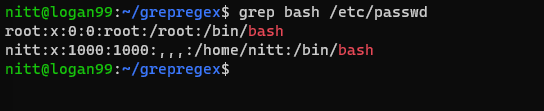
Detta visar användare som kan komma åt bash-skalet.
2. Ankarmatchning
Ankarmatchning används för avancerade sökningar med specialtecken:
- `^`: Matchar början av en rad.
- `$`: Matchar slutet av en rad.
De andra två ankartecknen är `\b` (ordgräns) och `\B` (icke-ordgräns).
- `\b`: Matchar positionen mellan ett ordtecken och ett icke-ordtecken.
- `\B`: Matchar positionen som inte ligger mellan ett ordtecken och ett icke-ordtecken.
Låt oss titta på exempel:
$ grep ‘^From’ tech.txt

`^` är skiftlägeskänsligt. Följande kommando ger inga resultat:
$ grep ‘^from’ tech.txt
Använd `$` för att hitta meningar som slutar med ett givet mönster:
$ grep ‘technology.$' tech.txt

Kombinera `^` och `$`:
$ grep “^From \| technology.$” tech.txt
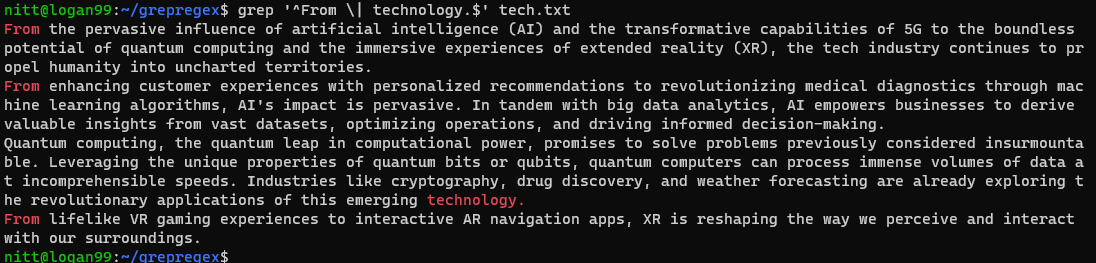
Utdata visar rader som antingen börjar med ”From” eller slutar med ”technology”.
3. Gruppering
Gruppering används för att söka efter flera mönster samtidigt. Du kan skapa grupper av tecken eller mönster som kan behandlas som en enhet. Till exempel kan du skapa gruppen `(tech)` som representerar tecknen `t`, `e`, `c`, `h`.
Exempel:
$ grep 'technol\(ogy\)\?' tech.txt

Gruppering används för att matcha upprepade mönster, fånga grupper och söka efter alternativ.
Alternativ sökning med gruppering
Exempel på alternativ sökning:
$ grep "\(tech\|technology\)" tech.txt
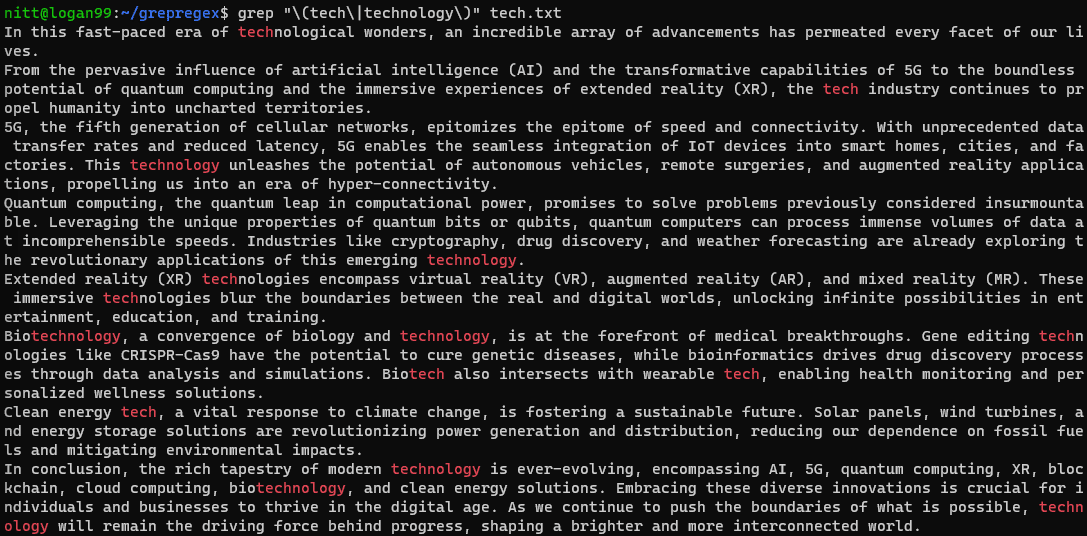
Använd `|` för att söka efter flera alternativ.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Fånga grupper, icke-fångande grupper och upprepade mönster
För att fånga grupper måste du definiera dem inom regex och skicka det till en sträng eller fil.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

För icke-fångande grupper, använd `?:` inom parentes.
Använd modifierare i regex för att hitta upprepade mönster:
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Detta regex söker efter en eller flera förekomster av tecknet `t`.
4. Teckenklasser
Teckenklasser använder hakparenteser `[]`. De vanligaste är:
- `[:digit:]`: Siffror 0-9.
- `[:alpha:]`: Alfabetiska tecken.
- `[:alnum:]`: Alfanumeriska tecken.
- `[:lower:]`: Gemener.
- `[:upper:]`: Versaler.
- `[:xdigit:]`: Hexadecimala siffror (0-9, A-F, a-f).
- `[:blank:]`: Tomma tecken som mellanslag och tab.
Exempel:
$ grep [[:digit]] tech.txt

$ grep [[:alpha:]] tech.txt
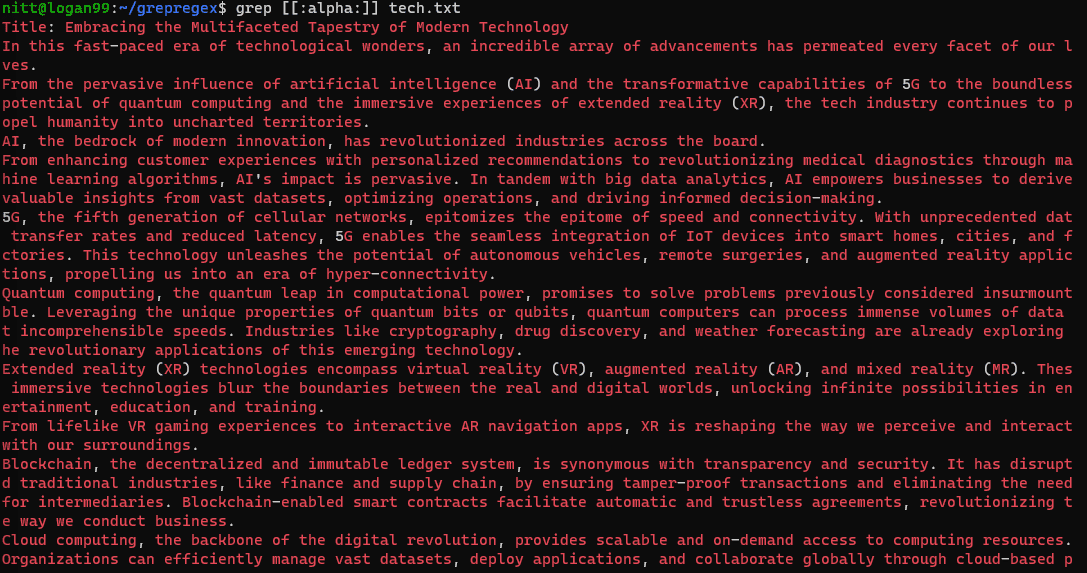
$ grep [[:xdigit:]] tech.txt
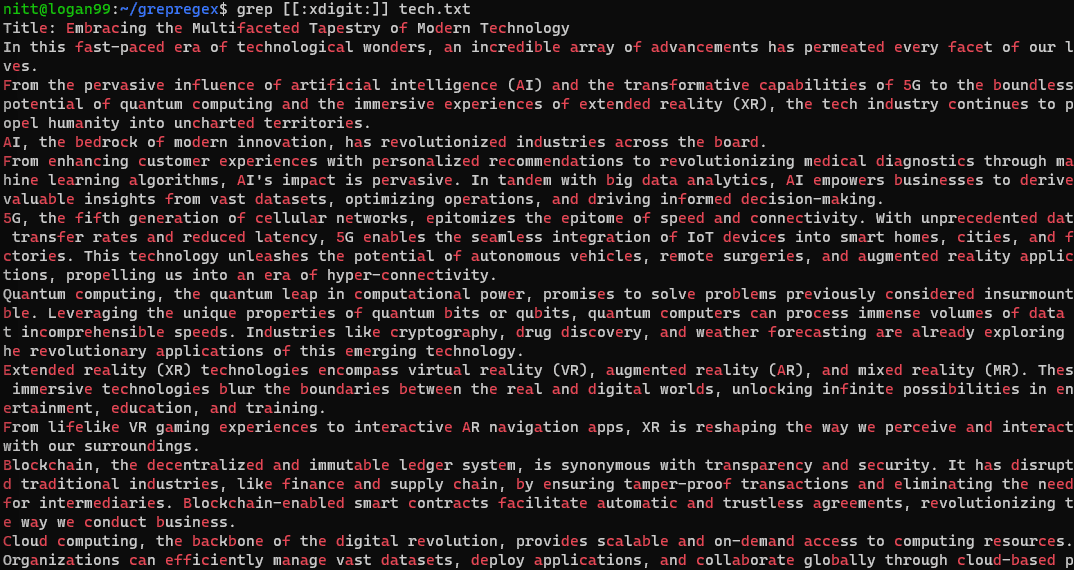
5. Kvantifierare
Kvantifierare låter dig ange hur många gånger ett tecken eller mönster ska matchas:
- `*`: Noll eller fler matchningar.
- `+`: En eller flera matchningar.
- `?`: Noll eller en matchning.
- `{x}`: Exakt x matchningar.
- `{x,}`: x eller fler matchningar.
- `{x,z}`: Från x till z matchningar.
- `{, z}`: Upp till z matchningar.
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Detta söker efter en eller flera förekomster av `t`. `-E` aktiverar utökat regex, vilket vi kommer att diskutera nedan.

6. Utökat Regex
Utökat regex (ERE) eliminerar behovet av att ”escape” metatecken. Använd flaggan `-E` för att aktivera ERE:
$ grep -E 'in+ovation' tech.txt

7. Använda PCRE för komplexa sökningar
PCRE (Perl Compatible Regular Expression) ger utökad funktionalitet. Du kan t.ex. använda `\d` för att representera `[0-9]`.
Exempel: Sök efter e-postadresser:
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

PCRE säkerställer att mönstret matchas korrekt. Du kan också använda PCRE för att söka efter datum:
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Detta hittar datum i formatet ÅÅÅÅ-MM-DD. Du kan anpassa mönstret efter andra format.
8. Alternering
Använd escaped pipe-tecken `\|` för att söka efter alternativa matchningar.
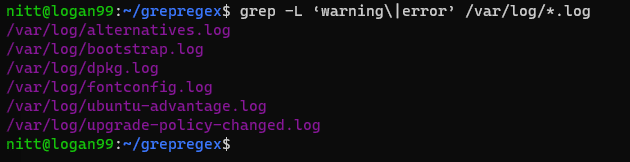
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Resultatet listar alla filnamn som innehåller ”varning” eller ”fel”.
Slutord
Detta avslutar vår guide om grep och regex. Genom att använda grep med regex effektivt kan du avsevärt förbättra noggrannheten och effektiviteten i dina sökningar, vilket sparar tid och hjälper dig att automatisera många uppgifter, särskilt när du skriptar eller arbetar med textbearbetning.
Se även våra vanliga frågor och svar för Linux-intervjuer.