Viktiga aspekter
- Stora aktörer som Open AI, Google, Microsoft och Meta satsar stort på små språkmodeller (SLM).
- SLM:er ökar snabbt i popularitet inom industrin och ses alltmer som framtidens AI-lösningar.
- Exempel på SLM:er inkluderar Googles Nano, Microsofts Phi-3-serie och Open AIs GPT-4o mini.
Stora språkmodeller (LLM) fick sitt genombrott med lanseringen av Open AIs ChatGPT. Sedan dess har flera företag introducerat sina egna LLM:er, men trenden går nu mot mindre språkmodeller (SLM).
SLM:er vinner mark, men vad är de egentligen och hur skiljer de sig från de större LLM:erna?
Vad Är en Liten Språkmodell?
En liten språkmodell (SLM) är en typ av AI-modell med ett mindre antal parametrar (se det som värden i modellen som anpassas under träning). Precis som LLM:er kan SLM:er generera text och utföra andra uppgifter. SLM:er använder dock mindre träningsdata, har färre parametrar och kräver mindre beräkningskraft för att tränas och köras.
SLM:er fokuserar på viktiga funktioner, och deras kompakta storlek gör att de kan implementeras på en mängd enheter, även de med begränsad processorkraft, som mobiltelefoner. Googles Nano är ett exempel på en SLM designad för att köras på mobila enheter. Enligt Google kan Nano köras lokalt, med eller utan internetanslutning, tack vare sin lilla storlek.
Utöver Nano finns det flera andra SLM:er från ledande och uppkommande AI-företag. Några välkända SLM:er inkluderar Microsofts Phi-3, OpenAIs GPT-4o mini, Anthropics Claude 3 Haiku, Metas Llama 3 och Mistral AIs Mixtral 8x7B.
Det finns också modeller som kan misstas för LLM:er men i själva verket är SLM:er. Många företag väljer att ha en portfölj av modeller som inkluderar både LLM:er och SLM:er. Ett bra exempel är GPT-4, som finns i flera varianter som GPT-4, GPT-4o (Omni) och GPT-4o mini.
Små Språkmodeller jämfört med Stora Språkmodeller
När vi pratar om SLM:er måste vi även nämna deras större motsvarigheter: LLM:er. Den största skillnaden mellan en SLM och en LLM är storleken, vilket mäts i parametrar.
För närvarande saknas en tydlig definition inom AI-industrin för exakt hur många parametrar en modell får ha för att klassas som SLM eller det minsta antalet för att vara LLM. Men generellt har SLM:er mellan miljoner och ett par miljarder parametrar, medan LLM:er kan ha allt upp till biljoner.
Till exempel har GPT-3, som släpptes 2020, 175 miljarder parametrar (och GPT-4 ryktas ha cirka 1,76 biljoner), medan Microsofts Phi-3-mini, Phi-3-small och Phi-3-medium SLM:er har 3,8, 7 respektive 14 miljarder parametrar.
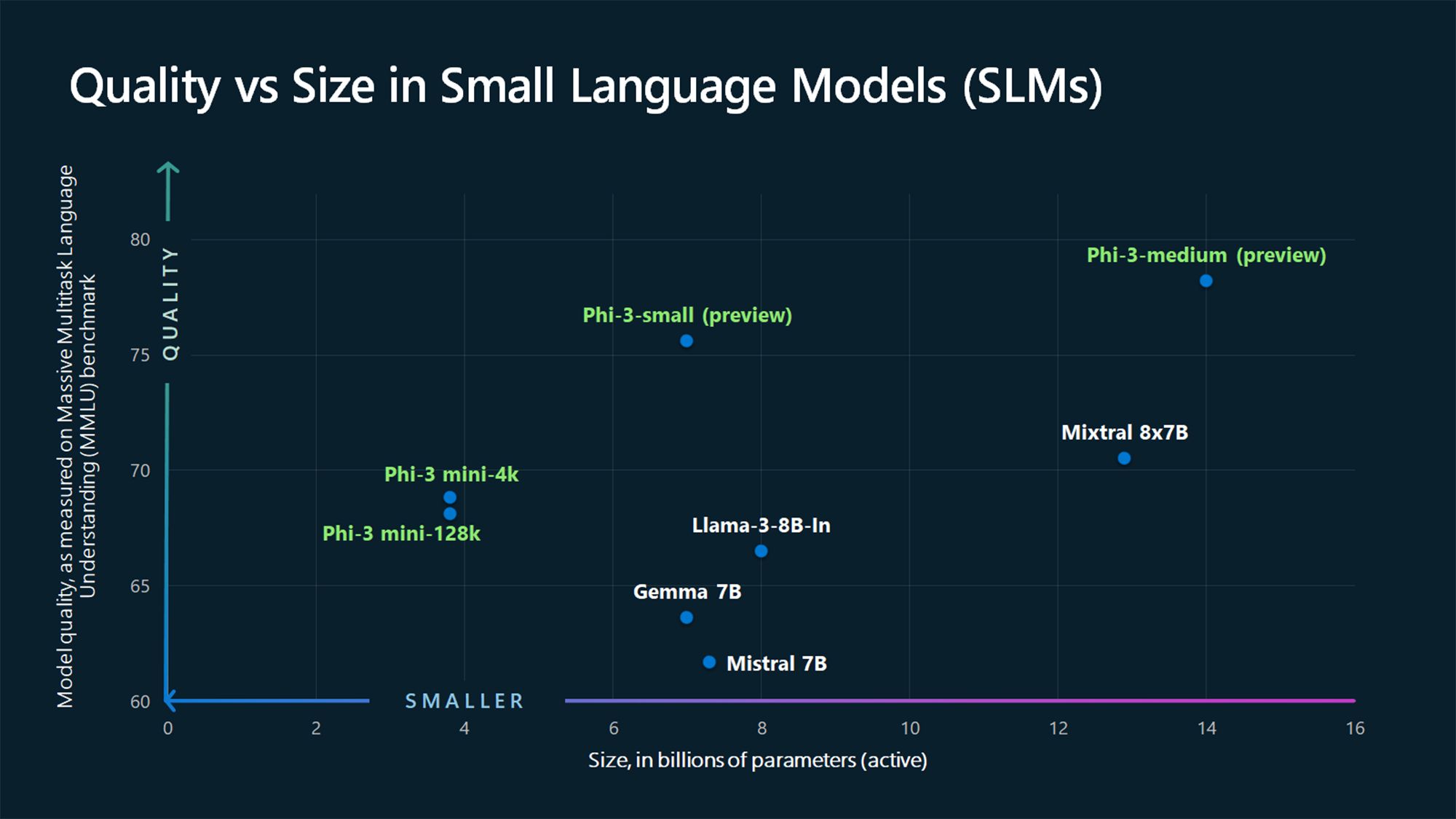
En annan distinktion mellan SLM:er och LLM:er är mängden träningsdata. SLM:er tränas på mindre datamängder, medan LLM:er använder enorma dataset. Detta påverkar också modellens förmåga att hantera komplexa uppgifter.
På grund av den stora mängd data som används vid träning är LLM:er bättre på att hantera olika typer av avancerade uppgifter som kräver avancerat resonemang. SLM:er å andra sidan passar bättre för enklare uppgifter. SLM:er använder mindre träningsdata, men den data som används behöver vara av hög kvalitet för att uppnå liknande förmågor som LLM:er fast i ett kompakt format.
Varför Små Språkmodeller Är Framtiden
För de flesta användningsområden är SLM:er bättre positionerade att bli de dominerande modellerna för både företag och konsumenter. LLM:er har visserligen sina fördelar och passar bättre för vissa applikationer, som avancerade problem. Men SLM:er är framtiden för de flesta användningsområden på grund av följande:
1. Lägre Kostnader för Träning och Underhåll
 Timofeev Vladimir/Shutterstock
Timofeev Vladimir/Shutterstock
SLM:er behöver mindre data för att tränas än LLM:er, vilket gör dem till ett mer realistiskt alternativ för privatpersoner och små till medelstora företag med begränsad träningsdata eller budget, eller både och. LLM:er kräver stora mängder data och kraftfulla datorresurser för både träning och drift.
För att ge ett exempel, bekräftade OpenAIs VD Sam Altman att träningen av GPT-4 kostade över 100 miljoner dollar under ett evenemang på MIT (enligt Wired). Ett annat exempel är Metas OPT-175B LLM. Meta uppger att den tränades med 992 NVIDIA A100 80GB GPU:er, som kostar cirka 10 000 dollar styck enligt CNBC. Det ger en kostnad på cirka 9 miljoner dollar, utan att räkna med andra utgifter som el, personal och mer.
Med sådana summor är det inte genomförbart för mindre företag att träna en egen LLM. SLM:er har däremot en lägre tröskel och är billigare i drift, vilket gör att fler företag kommer att kunna använda dem.
2. Bättre Prestanda
 GBJSTOCK / Shutterstock
GBJSTOCK / Shutterstock
Prestanda är ett annat område där SLM:er överträffar LLM:er på grund av sin kompakta storlek. SLM:er har lägre latens och passar bättre i situationer som kräver snabba svar, som i realtidsapplikationer. Ett exempel är röststyrda system som digitala assistenter där snabba svar är viktigt.
Att köra lokalt på enheten (mer om detta senare) innebär också att din förfrågan inte behöver resa till servrar online och tillbaka för att svara på din fråga, vilket resulterar i snabbare svar.
3. Högre Noggrannhet
 ZinetroN / Shutterstock
ZinetroN / Shutterstock
När det gäller generativ AI gäller fortfarande principen ”skräp in, skräp ut”. Befintliga LLM:er har tränats med stora dataset från internet. Därför kanske de inte är lika precisa i alla situationer. Detta är ett av problemen med ChatGPT och liknande modeller och varför man inte ska lita på allt som AI-chattbotar säger. SLM:er å andra sidan tränas med mer kvalitativ data än LLM:er och kan därmed uppnå en högre noggrannhet.
SLM:er kan också finjusteras med fokuserad träning på specifika uppgifter eller områden, vilket leder till ännu högre precision jämfört med större, mer generella modeller.
4. Möjlighet att Köras Lokalt på Enheten
 Pete Hansen/Shutterstock
Pete Hansen/Shutterstock
SLM:er kräver mindre beräkningskraft än LLM:er och passar därför utmärkt i edge computing-situationer. De kan implementeras på edge-enheter som smartphones och självkörande fordon, vilka saknar kraftfull processorkapacitet. Googles Nano-modell kan köras direkt på enheten, vilket gör att den fungerar även utan internetuppkoppling.
Denna funktion skapar en win-win-situation för både företag och konsumenter. För det första gynnar det integriteten eftersom användardata behandlas lokalt i stället för att skickas till molnet, vilket är viktigt i takt med att AI integreras alltmer i våra smartphones som innehåller nästan alla detaljer om oss. Det gynnar också företag eftersom de inte behöver hantera stora serverparker för att köra AI-uppgifter.
SLM:er vinner mark, och de största spelarna i branschen, som Open AI, Google, Microsoft, Anthropic och Meta, lanserar alla den här typen av modeller. Dessa modeller passar bättre för enklare uppgifter, vilket är vad de flesta av oss använder LLM:er till, och det är därför de är framtiden.
Men LLM:er kommer inte att försvinna. De kommer i stället att användas för avancerade tillämpningar som kombinerar information från flera områden för att skapa något nytt, som inom medicinsk forskning.
Sammanfattningsvis är SLM:er på väg att förändra landskapet inom artificiell intelligens, och deras fördelar gör dem till en attraktiv lösning för många företag och användare. Med lägre kostnader, bättre prestanda och möjligheten att köras lokalt är deras framtid ljus.