Pandas framstår som det mest omtyckta biblioteket för dataanalys inom Python-världen. Det är ett oumbärligt verktyg för dataanalytiker, datavetare och de som arbetar med maskininlärning.
Tillsammans med NumPy intar Pandas en central roll i verktygslådan för alla som sysslar med data och artificiell intelligens.
I denna artikel ska vi granska Pandas och utforska de egenskaper som bidragit till dess popularitet inom dataekosystemet.
Vad är Pandas?
Pandas är ett Python-bibliotek specialiserat på dataanalys. Det gör det möjligt att arbeta med och manipulera data direkt i din Python-kod. Med Pandas kan du effektivt hantera processer som att läsa, modifiera, visualisera, analysera och lagra data.
Namnet ”Pandas” härrör från en sammanslagning av orden Panel Data, en term som används inom ekonometri för att beskriva data som samlats in genom att följa flera individer över tid. Pandas lanserades först i januari 2008 av Wes Kinney och har sedan dess vuxit till att bli det mest populära biblioteket i sitt segment.
Kärnan i Pandas utgörs av två viktiga datastrukturer: Dataframes och Series. När du skapar eller importerar en dataset i Pandas, representeras den som en av dessa två strukturer.
I det kommande avsnittet kommer vi att fördjupa oss i vad dessa strukturer är, hur de skiljer sig åt och i vilka situationer det är bäst att använda den ena eller den andra.
Viktiga datastrukturer
Som vi nämnt tidigare presenteras all data i Pandas med hjälp av antingen en dataram eller en serie. Dessa strukturer kommer vi att beskriva mer detaljerat nedan.
Dataram
Denna dataram är genererad med hjälp av koden som visas längst ner i detta avsnitt.
En Dataframe i Pandas är en tvådimensionell struktur som består av kolumner och rader. Den kan jämföras med ett kalkylblad eller en tabell i en relationsdatabas.
En dataram är uppbyggd av kolumner, där varje kolumn representerar ett attribut eller en egenskap i din dataset. Dessa kolumner är i sin tur sammansatta av individuella värden, som var och en utgör en serie. Vi kommer att fördjupa oss i Series-datastrukturen senare i artikeln.
Kolumner i en dataram kan ha namn som hjälper till att särskilja dem. Dessa namn tilldelas antingen när dataramen skapas eller importeras, men kan enkelt ändras när som helst.
Värdena inom en kolumn måste vara av samma datatyp, även om kolumner i sig inte behöver innehålla data av samma typ. Till exempel kommer en namnolumn endast att lagra strängar, medan en ålderskolumn i samma dataset kan lagra heltal.
Dataramar använder sig också av ett index för att referera till rader. Värden från olika kolumner med samma index bildar en rad. Standardindex är numrerat, men detta kan ändras för att anpassas till din dataset. I det visade exemplet nedan är indexkolumnen inställd på ’månader’.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)
Serier
Denna serie har skapats med hjälp av koden i slutet av detta avsnitt.
Som tidigare nämnts används en serie för att representera en kolumn av data i Pandas. En serie är alltså en endimensionell datastruktur, till skillnad från en dataram som är tvådimensionell.
En serie kan representera en hel dataset om denna endast innehåller ett attribut som registreras i en kolumn, eller om datasetet är en lista med värden.
Eftersom en serie är en enskild kolumn behöver den inte nödvändigtvis ha ett namn, men värdena i serien är indexerade. Precis som för en dataram kan indexet för en serie ändras från standardnumreringen.
I det visade exemplet nedan har indexet satts till olika månader med hjälp av metoden `set_axis` för ett Pandas-objekt.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
Funktioner hos Pandas
Nu när du har en grundläggande förståelse för vad Pandas är och vilka datastrukturer som används, kan vi börja diskutera de funktioner som gör Pandas till ett så kraftfullt bibliotek för dataanalys, och därmed så populärt inom datavetenskap och maskininlärning.
#1. Datahantering
Både Dataframe- och Series-objekt kan ändras. Det är möjligt att lägga till eller ta bort kolumner efter behov. Pandas tillåter även att du lägger till rader och slår samman dataset.
Du kan utföra numeriska beräkningar, som att normalisera data och göra logiska jämförelser på elementnivå. Pandas ger dig också möjlighet att gruppera data och använda aggregerade funktioner som medelvärde, median, max och min. Detta underlättar arbetet med data i Pandas.
#2. Datarengöring
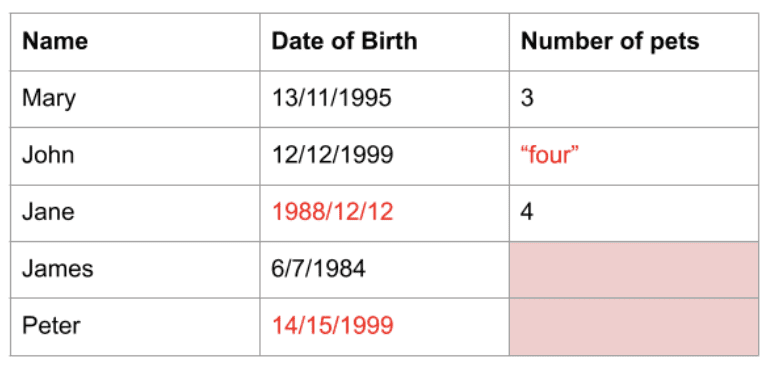
Verklighetsdata kan ofta innehålla värden som är svåra att arbeta med eller inte är idealiska för analys eller användning i maskininlärningsmodeller. Data kan ha fel datatyp, vara i fel format, eller helt enkelt saknas. Därför behöver denna data förbearbetas, en process som kallas datarengöring.
Pandas tillhandahåller funktioner för att underlätta datarengöring. I Pandas kan du till exempel ta bort dubbletter av rader, ta bort kolumner eller rader med saknad data, eller ersätta värden med standardvärden eller andra värden som kolumnens medelvärde. Det finns även andra funktioner och bibliotek som fungerar tillsammans med Pandas för att möjliggöra mer avancerad datarengöring.
#3. Datavisualisering
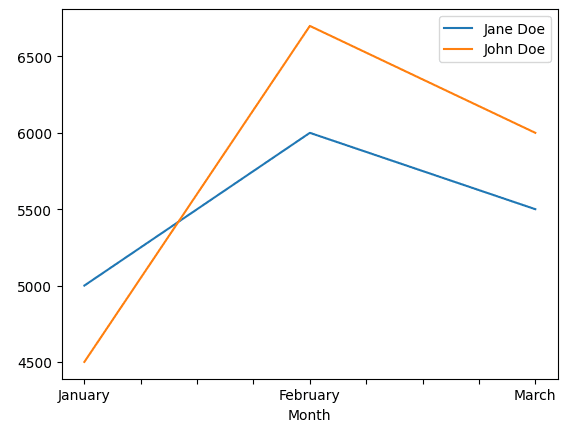
Denna graf har genererats med koden nedanför detta avsnitt.
Även om Pandas inte är ett visualiseringsbibliotek som Matplotlib, erbjuder det funktioner för att skapa grundläggande datavisualiseringar. Dessa visualiseringar är tillräckliga i de flesta situationer.
Med Pandas kan du enkelt rita stapeldiagram, histogram, spridningsdiagram och andra typer av diagram. Genom att kombinera detta med datamanipulation i Python, kan du skapa mer komplexa visualiseringar för att bättre förstå din data.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()
#4. Tidsserieanalys
Pandas erbjuder även stöd för att arbeta med tidsstämplad data. När Pandas känner igen en kolumn som en datetime-kolumn kan du utföra operationer som är användbara när du hanterar tidsseriedata.
Detta inkluderar att gruppera observationer efter tidsperiod och tillämpa aggregerade funktioner på dem, som summa eller medelvärde, eller hämta de tidigaste eller senaste observationerna med min och max. Naturligtvis finns det många fler operationer du kan utföra med tidsseriedata i Pandas.
#5. In- och utdata i Pandas
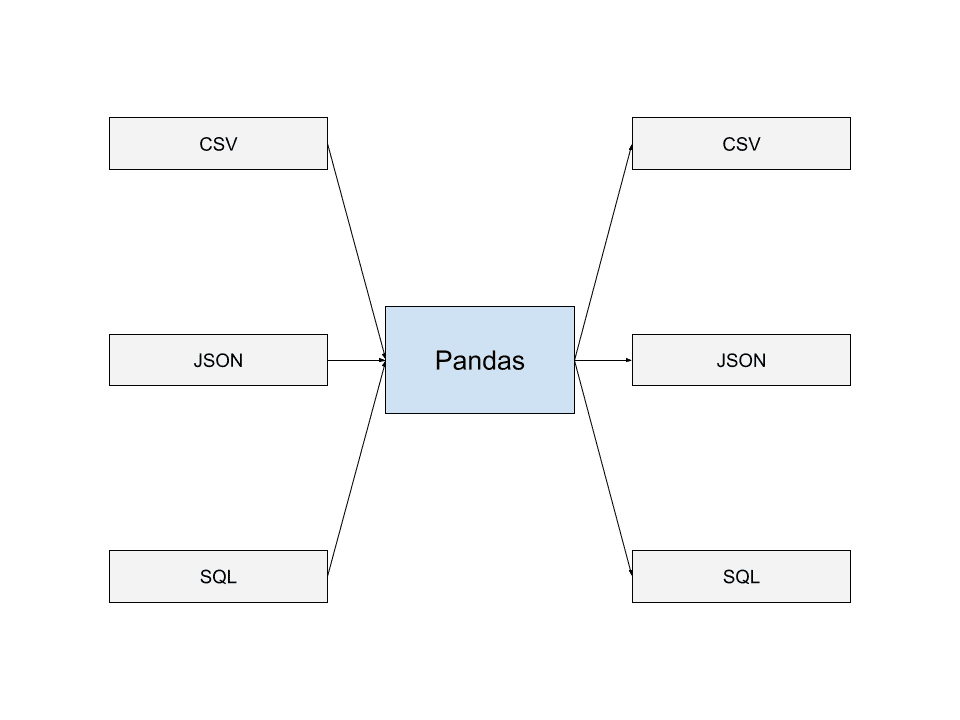
Pandas kan läsa data från de vanligaste dataformaten. Det inkluderar JSON, SQL Dumps och CSV-filer. Du kan också skriva data till filer i många av dessa format.
Denna förmåga att läsa och skriva data i olika format gör att Pandas kan integreras sömlöst med andra applikationer och skapa datapipelines som fungerar bra tillsammans med Pandas. Detta är en av anledningarna till att Pandas används flitigt av många utvecklare.
#6. Integration med andra bibliotek
Pandas har även ett stort ekosystem av verktyg och bibliotek som är utvecklade för att komplettera dess funktioner. Det gör det till ett ännu mer kraftfullt och användbart bibliotek.
Verktyg i Pandas ekosystem förbättrar dess funktioner inom områden som datarengöring, visualisering, maskininlärning, in- och utdata samt parallellisering. Pandas har en lista över dessa verktyg i sin dokumentation.
Prestanda och effektivitet i Pandas
Även om Pandas utmärker sig i de flesta operationer kan det ibland vara långsamt. Lyckligtvis kan du optimera din kod och förbättra hastigheten. För att göra detta behöver du förstå hur Pandas är konstruerat.
Pandas är byggt ovanpå NumPy, ett välkänt Python-bibliotek för numeriska och vetenskapliga beräkningar. Därför fungerar Pandas, precis som NumPy, mer effektivt när operationer vektoriseras i stället för att loopa genom enskilda celler eller rader.
Vektorisering är en form av parallellisering där samma operation utförs på flera datapunkter samtidigt. Detta kallas SIMD – Single Instruction, Multiple Data. Genom att utnyttja vektoriserade operationer kan du dramatiskt förbättra hastigheten och prestandan i Pandas.
Eftersom Dataframe- och Series-datastrukturerna använder NumPy-arrayer under ytan är de snabbare än alternativa datastrukturer som dictionaries och listor.
Pandas standardimplementering körs på en enda CPU-kärna. Ett annat sätt att snabba upp din kod är att använda bibliotek som gör att Pandas kan utnyttja alla tillgängliga CPU-kärnor. Exempel på sådana bibliotek är Dask, Vaex, Modin och IPython.
Community och resurser
Eftersom Pandas är ett populärt bibliotek i det mest använda programmeringsspråket har Pandas en stor gemenskap av användare och utvecklare. Som ett resultat finns det många resurser för att lära sig hur man använder det, inklusive den officiella Pandas-dokumentationen. Det finns också ett stort antal kurser, tutorials och böcker att lära sig från.
Det finns även onlinecommunitys på plattformar som Reddit i subreddits som r/Python och r/DataScience, där du kan ställa frågor och få svar. Eftersom Pandas är ett open source-bibliotek kan du rapportera buggar på GitHub och även bidra med kod.
Slutord
Pandas är ett otroligt användbart och kraftfullt bibliotek inom datavetenskap. I den här artikeln har vi försökt förklara dess popularitet genom att undersöka de funktioner som gör det till ett toppverktyg för datavetare och programmerare.
Kolla gärna in hur man skapar en Pandas DataFrame.