När man talar om ”serverlös” databehandling, tror många felaktigt att det inte finns någon server alls i denna modell. Det är dock en missuppfattning. Denna tanke är ett ganska vanligt feltänkande när man hör ordet ”serverlös”.
Efter att ha rett ut denna missuppfattning kanske du undrar över logiken bakom namnet ”serverlös”. Det viktiga här är inte att det inte finns någon server, utan HUR servrarna hanteras och implementeras. Det är detta som är kärnan i vad ”serverlöst” innebär.
Låter det lite förvirrande? Oroa dig inte, vi ska reda ut alla frågetecken kring serverlös databehandling och relaterade begrepp. Serverlös databehandling är något som blir allt mer populärt. Faktum är att den serverlösa marknaden förväntas nå 7,7 miljarder dollar år 2021, jämfört med 1,9 miljarder dollar 2016.
Låt oss nu dyka djupare in i vad serverlös databehandling är och försöka förstå varför det har blivit så populärt.
Vad är serverlös databehandling?
Serverlös databehandling är en molnbaserad modell för exekvering, där molntjänstleverantörer erbjuder maskinresurser på begäran och sköter servrarna själva, istället för att låta kunderna eller utvecklarna göra det. Det är ett sätt som kombinerar olika tjänster, metoder och strategier för att underlätta utvecklingen av molnbaserade applikationer. Utvecklare kan då fokusera enbart på sin kod och slippa bekymra sig om serverhantering.
Molntjänstleverantören (som AWS eller Google Cloud Platform) tar hand om alla vanliga infrastrukturuppgifter, såsom resursallokering, kapacitetsplanering, hantering, konfigurationer, skalning, patchar, uppdateringar, schemaläggning och underhåll. Detta frigör utvecklarnas tid och resurser, så att de kan koncentrera sig på affärslogiken för sina processer och applikationer.
Denna typ av arkitektur lagrar inte beräkningsresurser i ett kontinuerligt flyktigt minne; istället sker beräkningen i korta, avgränsade delar. Om en applikation inte används, tilldelas inga resurser till den. Detta innebär att man bara betalar för de resurser som faktiskt förbrukas.
Huvudsyftet med den serverlösa modellen är att förenkla processen med koddistribution i produktionsmiljöer. Ofta fungerar den även bra med traditionella tillvägagångssätt, som mikrotjänster. När en serverlös applikation väl är distribuerad, svarar den snabbt på behov, och skalas upp eller ner automatiskt efter efterfrågan.
Serverlös databehandling använder en händelsedriven modell för att bestämma skalningsbehovet. Utvecklare behöver därför inte längre förutse hur applikationen kommer att användas för att bestämma hur många servrar eller bandbredd som behövs. Man kan enkelt skala upp med fler servrar och bandbredd efterhand som behoven ökar, utan att behöva boka i förväg, och minska användningen igen när som helst.
Hur har Serverless utvecklats?
Det traditionella systemet hade utmaningar med skalbarhet och flexibilitet i apputvecklingen och implementeringen. I takt med att kraven på högkvalitativa applikationer ökade, med snabbare tid till marknad, växte behovet av ett bättre system som kunde erbjuda mer skalbarhet och smidighet. Detta ledde till utvecklingen av molntjänster och serverlösa modeller.
Den serverlösa modellen utvecklades i olika faser, från monolitiska system till mikrotjänster och sedan till serverlös arkitektur, även kallad Function-as-a-Service (FaaS).
- Monolitisk arkitektur är en traditionell, sammanhållen metod för mjukvaruutveckling. Det är en tätt sammanlänkad modell där varje komponent och dess underkomponenter kompilerar eller exekverar kod tillsammans. Om en tjänst drabbas av fel kan hela applikationsservern och tjänsterna som körs på den sluta fungera.
- Mikrotjänstarkitektur är en samling mindre tjänster i en stor, sammanhängande applikation. Dessa tjänster distribueras oberoende för att utföra specifika uppgifter. Det möjliggör snabbare leverans av applikationer i stor skala, och ger utvecklare flexibilitet genom att använda Infrastructure-as-a-Service (IaaS) och Platform as a Service (PaaS). Att välja mellan PaaS och IaaS kan dock vara en utmaning med denna modell.
- Serverlös arkitektur utvecklades tillsammans med molntjänster och erbjuder ökad skalbarhet och affärsflexibilitet. Istället för IaaS och PaaS, använder den FaaS och Backend-as-a-Service (BaaS). Här distribueras applikationer efter behov, tillsammans med de resurser som krävs. Man behöver inte hantera servrarna direkt, och kostnaderna upphör när kodexekveringen avslutas.
Egenskaper för serverlös databehandling
Här är några av de viktigaste egenskaperna hos serverlös databehandling:
- De flesta applikationer som använder serverlös arkitektur består av enkla funktioner och små kodblock.
- Koden körs bara på begäran, vanligtvis i en tillståndslös mjukvarubehållare. Systemet skalas smidigt baserat på efterfrågan.
- Kunden behöver inte hantera några servrar.
- Exekveringen är händelsebaserad, vilket innebär att beräkningsmiljön skapas när en funktion utlöses eller en händelse tas emot för att exekvera begäran.
- Systemet är flexibelt och skalbart, vilket betyder att man enkelt kan skala upp eller ner. När en kod har körts slutar infrastrukturen att arbeta och kostnader sparas. På samma sätt, om funktionen fortsätter att köras, kan systemet skalas upp oändligt efter behov.
- Du kan använda hanterade molntjänster för att hantera komplexa uppgifter som fillagring, dataköer, databaser med mera.
Hur fungerar serverlöst?
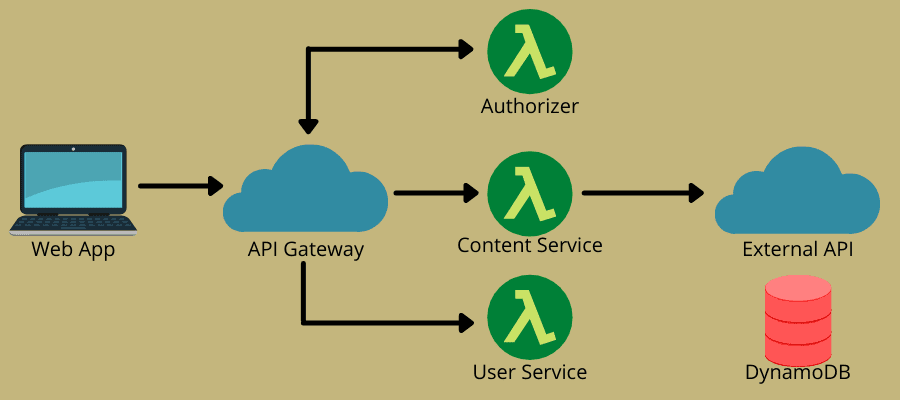
Den serverlösa arkitekturen kombinerar två huvudidéer: Function-as-a-Service (FaaS) och Backend-as-a-Service (BaaS). Den bygger främst på FaaS, som tillåter molntjänster för kodexekvering utan att behöva fullt ut provisionerade instanser. FaaS består av tillståndslösa, händelsedrivna, skalbara och server-side funktioner som molntjänstleverantörer hanterar fullt ut.
Denna modell gör det möjligt för DevOps-team att skriva kod med fokus på affärslogiken. Sedan definierar de en händelse som kan utlösa funktionen, som t.ex. HTTP-förfrågningar, för att exekveras. Molnleverantören utför sedan funktionen och skickar resultatet till de applikationer som användarna ser.
På detta sätt erbjuder den serverlösa modellen kostnadseffektivitet och bekvämlighet med automatisk skalning, on-demand funktioner och betala-per-användning. Det är därför många företag och DevOps-team använder sig av serverlös databehandling idag.
Vem använder Serverless och varför?
Serverlös databehandling är en av de snabbast växande teknologierna inom mjukvaruutveckling. Det har potential att eliminera behovet av infrastrukturhantering och provisionering i framtiden.
Det är användbart för:
- Organisationer som söker mer skalbarhet och flexibilitet med bättre testbarhet av sina applikationer.
- Utvecklare som vill minska tiden till marknaden genom att bygga snabba och högpresterande appar.
- Företag som inte behöver att deras servrar ska vara igång hela tiden. De kan anropa modulbaserade funktioner med hjälp av applikationer vid behov, för att spara kostnader.
- Organisationer som vill bygga effektiva molnbaserade applikationer och förenkla molnmigrering.
- Utvecklare som vill minska latens och erbjuda användare snabb tillgång till vissa funktioner eller applikationer.
- Företag som saknar tillräckliga resurser för att hantera underhållet och komplexiteten i IT-infrastrukturen, och som därför vill använda serverlös databehandling för att automatiskt lösa problem utan att behöva underhåll från deras sida.
Några kända användare av den serverlösa modellen är Slack, Coca-Cola, NetFlix m.fl.
På grund av sina unika egenskaper är serverlös databehandling lämpligt för många olika användningsfall, som t.ex.:
- Webbapplikationer: Man kan bygga snabba och skalbara webbapplikationer som reagerar snabbt på användarnas behov. Detta är idealiskt för att bygga tillståndslösa applikationer som kan startas direkt, och för applikationer som behöver hantera oförutsägbara, plötsliga ökningar i användarbehov.
- API-backends: I serverlösa plattformar kan alla funktioner enkelt omvandlas till HTTP-slutpunkter som är redo att användas av klienterna. Dessa funktioner, eller åtgärder, kallas webbåtgärder när de är aktiverade på webben. När de väl är aktiverade blir det enkelt att bygga ihop funktionerna till ett fullfjädrat API. Du kan även använda en API-gateway för att få mer säkerhet, domänstöd, hastighetsbegränsningar och OAuth-stöd.
- Mikrotjänster: Serverlös databehandling används flitigt i mikrotjänstmodellen, som fokuserar på att bygga små tjänster som utför en enda funktion och kommunicerar med varandra via API:er. Även om mikrotjänster kan skapas med hjälp av programvarubehållare och PaaS, är serverlöst mer effektivt. Det möjliggör mindre kodrader, snabb provisionering, automatisk skalning och flexibel prissättning som inte tar betalt när resurserna inte används.
- Databehandling: Serverlös databehandling är utmärkt för att arbeta med data som innehåller videor, ljud, bilder och strukturerad text. Det passar även bra för olika uppgifter som datavalidering, transformation, rensning, ljudnormalisering och PDF-bearbetning. Du kan använda det för bildbehandling, som t.ex. skärpa, rotation, generering av miniatyrbilder och brusreducering. Andra användningsområden för serverlöst inom databehandling kan vara videoomkodning och optisk teckenigenkänning (OCR).
- Ström-/batchbearbetning: Du kan skapa kraftfulla strömningsapplikationer och datapipelines med FaaS och en databas som Apache Kafka. Den serverlösa modellen är lämplig för olika ströminflöden, inklusive data från applikationsloggar, IoT-sensorer, affärslogik och finansmarknaden.
- Parallell beräkning: Serverlöst är utmärkt för uppgifter relaterade till parallell beräkning, där varje uppgift körs parallellt för att utföra en specifik uppgift. Det kan inkludera datasökning, bearbetning, kartoperationer, webbskrapning, genombearbetning, hyperparameterjustering m.m.
- Andra användningsområden: Serverlöst används också för olika applikationer som t.ex. kundrelationshantering (CRM), ekonomi, chatbots och business intelligence och analyser, bara för att nämna några.
Obs: Serverlöst är inte idealiskt för alla användningsfall. Stora applikationer med förutsägbara och nästan konstanta arbetsbelastningar kan t.ex. dra mer nytta av en traditionell systemarkitektur. De kan då välja dedikerade servrar, antingen hanterade eller självhanterade. Om din organisation har kompletta traditionella inställningar med äldre system och applikationer, kan det dessutom vara dyrt och utmanande att gå över till en helt ny och annorlunda arkitektur.
Fördelar och nackdelar med serverlös databehandling
Varje sak har två sidor, och det gäller även den serverlösa arkitekturen. Det har både fördelar och nackdelar baserat på olika parametrar. Innan du bestämmer dig för om det passar din organisation är det viktigt att känna till båda sidorna.
Fördelar 👍
Här är några av fördelarna med serverlös arkitektur:
Kostnadseffektivt
Serverlöst kan vara mer kostnadseffektivt än att köpa eller hyra servrar, där man betalar för resurser även när de inte används.
Serverlöst använder en betala-per-användning-modell där man bara betalar för de resurser som faktiskt förbrukas. Leverantören tar bara betalt för det minne som tilldelats och tiden det tar att köra koden, utan att debitera för vilotid.
Detta sparar driftskostnader för uppgifter som installation, licenser, underhåll, patchning, support, m.m. Utan serverhårdvara sparar man även på personalkostnader.
Skalbarhet
Serverlösa system erbjuder en hög grad av skalbarhet, då man kan skala upp eller ner efter behov. De kallas även för ”elastiska” av denna anledning.
Utvecklarna behöver inte lägga tid på att konfigurera de automatiska skalningssystemen, utan det sköter molnleverantören. Små utvecklingsteam kan också köra sin kod utan att behöva stöd från tekniker eller infrastrukturpersonal.
Minskad latens
Eftersom applikationerna inte finns på en enskild server kan man köra koden var som helst. Om molnleverantören stöder det, kan man köra applikationsfunktioner på en server nära användaren. Detta ger mindre latens eftersom avståndet mellan användarens förfrågningar och servern minskar.
Produktivitet
Den serverlösa modellen hjälper till att öka utvecklarnas produktivitet, då de inte behöver hantera serverunderhåll. De behöver heller inte tänka på att hantera HTTP-förfrågningar eller multithreading direkt i sin kod.
Detta förenklar utvecklingen av backend, tack vare FaaS, där den exponerade koden består av händelsedrivna funktioner. Allt detta sparar tid som de kan använda till att förbättra sin kod och applikationer.
Snabbare appimplementering
Med serverlöst behöver utvecklare inte göra backend-konfiguration eller ladda upp kod till servern för att distribuera en ny version av en applikation. De kan också ladda upp koden i små delar för att snabbare lansera nya produkter.
De har också flexibiliteten att distribuera koden antingen direkt eller i sekvens, då det inte är en monolitisk arkitektur. Man kan också snabbt korrigera, uppdatera, lägga till funktioner eller åtgärda fel i en applikation.
Andra fördelar inkluderar miljövänlig databehandling p.g.a. minskad energiförbrukning med on-demand-servrar, att det blir enklare att bygga applikationer med hjälp av inbyggda integrationer, snabbare tid till marknaden m.m.
Nackdelar 👎
Låt oss nu titta på nackdelarna med serverlös databehandling:
Prestanda
Serverlös kod som inte används så ofta kan ibland uppvisa högre latens än kod som körs kontinuerligt på dedikerade servrar, i mjukvarubehållare eller virtuella maskiner (VM). Detta beror på att det kan ta extra tid att starta om och det kan orsaka latens.
Svårt att felsöka och testa
Du behöver veta hur koden fungerar när du distribuerar den. För att göra det behöver man testa den, vilket kan vara svårt i en serverlös miljö. Eftersom utvecklarna inte har insyn i alla backend-processer och applikationerna är uppdelade i mindre funktioner, blir felsökningen komplicerad.
Säkerhetsproblem
Nya och avancerade cybersäkerhetsproblem växer. Det är inte alltid möjligt att känna till eller utvärdera molnleverantörens säkerhet. När de sköter hela backend med känslig data som lagras i applikationerna, innebär det en risk.
Inte lämpligt för långvariga processer
Serverlöst är kostnadseffektivt, men inte för alla typer av applikationer. Om man har en applikation med långvariga processer kan kostnaderna för att köra den, baserat på tid och tilldelade resurser, bli mycket höga. I det läget kan det vara bättre att gå över till dedikerad serverhosting.
Andra nackdelar med serverlöst är svårigheter att byta från en leverantör till en annan, samt integritetsproblem.
Terminologi som är viktig i serverlös arkitektur
En diskussion om serverlöst är inte fullständig utan att ta upp en del viktiga begrepp relaterade till det. FaaS och BaaS är två av de mest framträdande idéerna som lett till utvecklingen av serverlös databehandling. För att bygga ett serverlöst system behöver man en databas, lagringssystem, teknikstack, ramverk m.m. Låt oss nu diskutera dessa lite närmare.
Function-as-a-Service (FaaS)
FaaS är en central del av serverlöst och fungerar som en delmängd. Denna händelsedrivna modell för kodexekvering (applikationer som körs som svar på en förfrågan) låter dig skriva logik som distribueras i programvarubehållare, körs på begäran och hanteras av en molnplattform.
Om man jämför det med BaaS, erbjuder FaaS utvecklarna mer kontroll över skapandet av anpassade applikationer, istället för att vara beroende av bibliotek med färdig kod.
Programvarubehållarna där koden distribueras är tillståndslösa, för att förenkla dataintegration, och koden körs under en kort tid. Utvecklarna kan anropa serverlösa applikationer via API:er som molnleverantörerna hanterar via en API-gateway.
Backend-as-a-Service (BaaS)
BaaS liknar FaaS eftersom båda kräver en tredjepartsleverantör. I denna modell tillhandahåller en molnleverantör backend-tjänster, som datalagring, så att utvecklarna kan fokusera på att skriva frontend-kod. BaaS-applikationer behöver dock inte vara händelsedrivna eller köras i kanten på samma sätt som serverlösa applikationer.
Ett bra exempel på BaaS är AWS Lambda. Utvecklarna använder serverlös kod i behållare med Lambda som ger riktlinjer för när de skickar in koden. Den automatiserar även processerna för att mata in koden i mjukvarubehållare och erbjuder en hanterad tjänst.
Serverlös stack
Precis som andra mjukvarutekniker, kommer serverlös arkitektur med en egen teknikstack. Den sammanför olika komponenter som behövs för att bygga ett serverlöst system eller applikation.
Den serverlösa stacken inkluderar:
- Ett programmeringsspråk: Det programmeringsspråk som utvecklarna använder för att skriva koden. Beroende på leverantör kan du välja mellan Java, JavaScript, Python, C#, Go, Node.js, F# m.fl.
- Ett serverlöst ramverk: Ett ramverk tillhandahåller skelettet eller strukturen för koden. Det finns många serverlösa ramverk att välja mellan. De gör det möjligt att bygga, paketera och kompilera kod för molninstallation. Serverlösa ramverk snabbar upp kodningsprocessen och förenklar skalningen genom att minska konfigurationstiden. Exempel på serverlösa ramverk är Apex, AWS Serverless Application Model m.fl.
- Serverlösa databaser: De används för att lagra data som koden behöver ha tillgång till. De behövs även för att interagera med funktioner via triggers. Dessa databaser fungerar som serverlösa funktioner, men lagrar data under obestämd tid. Exempel på serverlösa databaser är DynamoDB, Azure Cosmos DB, Aurora Serverless och Cloud Firestore.
- En uppsättning triggers: De hjälper till att starta kodexekveringen, som t.ex. HTTP-förfrågningar.
- Programvarubehållare: De ger kraft åt den serverlösa modellen och erbjuder containeriserade mikrotjänster utan komplexitet. De fungerar även som ett arkiv för koden och underlättar utveckling på flera plattformar, som t.ex. datorer eller iOS.
- API-gateways: De fungerar som en proxy för webbåtgärder. De erbjuder HTTP-routing, hastighetsbegränsningar, visning av API-användning och svarsloggar, klient-ID m.m.
Hur implementerar man en serverlös modell och optimerar den?
Att gå över till serverlös databehandling innebär betydande förändringar när det gäller dina applikationer, teknik, kostnader, säkerhet och fördelar.
Om du är ett nystartat eller litet företag, kommer det att påskynda tiden till marknaden och hjälpa dig att lansera uppdateringar snabbare, med enklare tester, felsökning, feedbackinsamling, hantering av problem m.m., vilket leder till en mer användarvänlig applikation.
Om du är en större organisation kommer du att dra nytta av fördelar som t.ex. mer skalbarhet för att tillgodose dina användares behov, men detta kommer att kräva betydande kostnadsinvesteringar.
Därför är det bäst att utvärdera fördelarna och nackdelarna med serverlöst specifikt för din verksamhetstyp och dina krav, innan du går vidare. Om du är seriös med att gå över till en serverlös modell, börja med att:
- Förstå dina behov och identifiera en lämplig serverlös teknikstack.
- Välj en serverlös leverantör, som t.ex. Google Cloud Functions, Azure Functions, AWS Lambda m.fl.
- Ge ditt team kraftfulla verktyg för att övervaka systemets prestanda och funktioner. Håll koll på det totala antalet förfrågningar, begränsningar, antalet fel, framgångsfrekvens, förfrågningslängd och latens.
Serverlösa leverantörer

Det finns många serverlösa leverantörer, eller molnleverantörer, att välja mellan. Här är några av de bästa:
- AWS Lambda: Perfekt för organisationer som redan använder AWS-tjänster. Det integreras med många tjänster för lagring, streaming och databaser.
- Microsoft Azure Functions: Om du använder Visual Studio Code är detta ett bra val. Det fungerar smidigt med DevOps och Azure Pipelines för CI/CD. Det stöder även Durable Functions för tillståndsfulla funktioner och erbjuder integrerad övervakning.
- Google Cloud Functions: Om du använder Googles tjänster är det ett bra val. Det stöder applikationer i JS, Go och Python, gör att funktioner kan triggas från Google Assistant eller GCP och erbjuder inbyggd skalning.
- IBM Cloud Functions: Om du vill använda en serverlös modell baserad på Apache OpenWhisk är IBM Cloud Functions ett bra val. Det innehåller utmärkt prestandaövervakning, händelseutlösning från ett REST API eller IBMs molntjänster, och integreras med IBM:s API-gateway för att hantera slutpunkter.
- Knative: Om du kör tjänster på Kubernetes, är detta ett bra val. Det stöds av Google, Red Hat, IBM m.fl.
- Cloudflare Workers: Detta är bra för applikationer som behöver vara snabba och responsiva, särskilt JavaScript-applikationer. Det stöder Workers KV för datalagring och WebAssembly, vilket hjälper dig att kompilera och leverera flera språk. Det höga distributionsnätverket med 193 datacenter förbättrar latensen och responsen.
Slutsats: Serverlösts framtid
Serverlös databehandling utvecklas med den ökande efterfrågan på mycket skalbara applikationer. Det ger många fördelar som molntjänster erbjuder, som t.ex. ökad bekvämlighet, kostnadseffektivitet, högre produktivitet m.m.
Enligt en O’Reilly-undersökning arbetar 40 % av de tillfrågade på företag som har implementerat serverlös arkitektur.
Även om serverlöst fortfarande har vissa problem, som t.ex. latens p.g.a. kallstarter, testning, felsökning m.m., arbetar molnleverantörerna på att lösa dem. Snart kan en mer förfinad form av serverlöst dyka upp med fler fördelar och färre problem. Därför förväntas populariteten och användningen av serverlös databehandling att öka i framtiden.
Du kanske även är intresserad av: 7 sätt serverlös databehandling är en teknik i frammarsch