

Undrar du hur man får tillförlitlig och konsekvent data för dataanalys? Implementera dessa datarensningsstrategier nu!
Ditt affärsbeslut bygger på dataanalysinsikter. På samma sätt förlitar sig de insikter som härrör från indatauppsättningar på kvaliteten på källdata. Låg kvalitet, felaktig, skräp och inkonsekvent datakälla är de tuffa utmaningarna för datavetenskap och dataanalysindustrin.
Därför har experter kommit med lösningar. Den här lösningen är datarensning. Det besparar dig från att fatta datadrivna beslut som kommer att skada verksamheten istället för att förbättra den.
Läs vidare för att lära dig de bästa strategierna för datarensning som framgångsrika datavetare och analytiker använder. Utforska också verktyg som kan erbjuda ren data för omedelbara datavetenskapsprojekt.
Innehållsförteckning
Vad är datarensning?
Datakvalitet har fem dimensioner. Att identifiera och korrigera fel i dina indata genom att följa datakvalitetspolicyerna kallas datarensning.
Kvalitetsparametrarna för denna femdimensionella standard är:
#1. Fullständighet
Denna kvalitetskontrollparameter säkerställer att indata har alla nödvändiga parametrar, rubriker, rader, kolumner, tabeller etc. för ett datavetenskapligt projekt.
#2. Noggrannhet
En datakvalitetsindikator som säger att data är nära det verkliga värdet av indata. Data kan vara av verkligt värde när du följer alla statistiska standarder för undersökningar eller skrotning för datainsamling.
#3. Giltighet
Denna parameter datavetenskap att data överensstämmer med de affärsregler som du har ställt in.
#4. Enhetlighet
Enhetlighet bekräftar om uppgifterna innehåller enhetligt innehåll eller inte. Till exempel bör energiförbrukningsundersökningsdata i USA innehålla alla enheter som imperialistiskt mätsystem. Om du använder det metriska systemet för visst innehåll i samma undersökning är uppgifterna inte enhetliga.
#5. Konsistens
Konsistens säkerställer att datavärdena är konsekventa mellan tabeller, datamodeller och datauppsättningar. Du måste också övervaka denna parameter noggrant när du flyttar data mellan system.
I ett nötskal, tillämpa ovanstående kvalitetskontrollprocesser på rådatauppsättningar och rensa data innan du matar den till ett business intelligence-verktyg.
Vikten av datarensning
Precis så kan du inte driva ditt digitala företag med en dålig internetbandbreddsplan; du kan inte fatta stora beslut när datakvaliteten är oacceptabel. Om du försöker använda skräp och felaktig data för att fatta affärsbeslut kommer du att se en förlust av intäkter eller dålig avkastning på investeringen (ROI).
Enligt en Gartner-rapport om dålig datakvalitet och dess konsekvenser har tankesmedjan funnit att den genomsnittliga förlusten ett företag drabbas av är 12,9 miljoner dollar. Detta är bara för att fatta beslut som förlitar sig på felaktiga, förfalskade och skräpdata.
Samma rapport tyder på att användning av dålig data över hela USA kostar landet en svindlande årlig förlust på 3 biljoner dollar.
Den slutliga insikten blir säkert skräp om du matar BI-systemet med skräpdata.
Därför måste du rensa rådata för att undvika monetära förluster och fatta effektiva affärsbeslut från dataanalysprojekt.
Fördelar med datarensning
#1. Undvik monetära förluster
Genom att rensa indata kan du rädda ditt företag från monetära förluster som kan komma som en straff för bristande efterlevnad eller förlust av kunder.
#2. Ta stora beslut

Högkvalitativ och handlingsbar data ger fantastiska insikter. Sådana insikter hjälper dig att fatta enastående affärsbeslut om produktmarknadsföring, försäljning, lagerhantering, prissättning, etc.
#3. Få ett försprång över konkurrenten
Om du väljer datarensning tidigare än dina konkurrenter kommer du att dra nytta av fördelarna med att bli en snabbare i din bransch.
#4. Gör projektet effektivt
En strömlinjeformad datarensningsprocess ökar förtroendenivån för teammedlemmarna. Eftersom de vet att data är tillförlitliga kan de fokusera mer på dataanalys.
#5. Spara resurser
Rensning och trimning av data minskar storleken på den övergripande databasen. Därför rensar du databasens lagringsutrymme genom att eliminera skräpdata.
Strategier för att rensa data
Standardisera visuella data
En datauppsättning kommer att innehålla många typer av tecken som texter, siffror, symboler, etc. Du måste använda ett enhetligt format för versaler för alla texter. Se till att symbolerna är i rätt kodning, som Unicode, ASCII, etc.
Till exempel betyder term Bill med versaler namnet på en person. Däremot betyder en räkning eller räkningen ett kvitto på en transaktion; därför är lämplig formatering av stora bokstäver avgörande.
Ta bort replikerade data
Duplicerad data förvirrar BI-systemet. Följaktligen kommer mönstret att bli skevt. Därför måste du sålla bort dubbletter från indatadatabasen.
Dubletter kommer vanligtvis från mänskliga datainmatningsprocesser. Om du kan automatisera processen för inmatning av rådata kan du radera datareplikationer från roten.
Fixa oönskade extremvärden
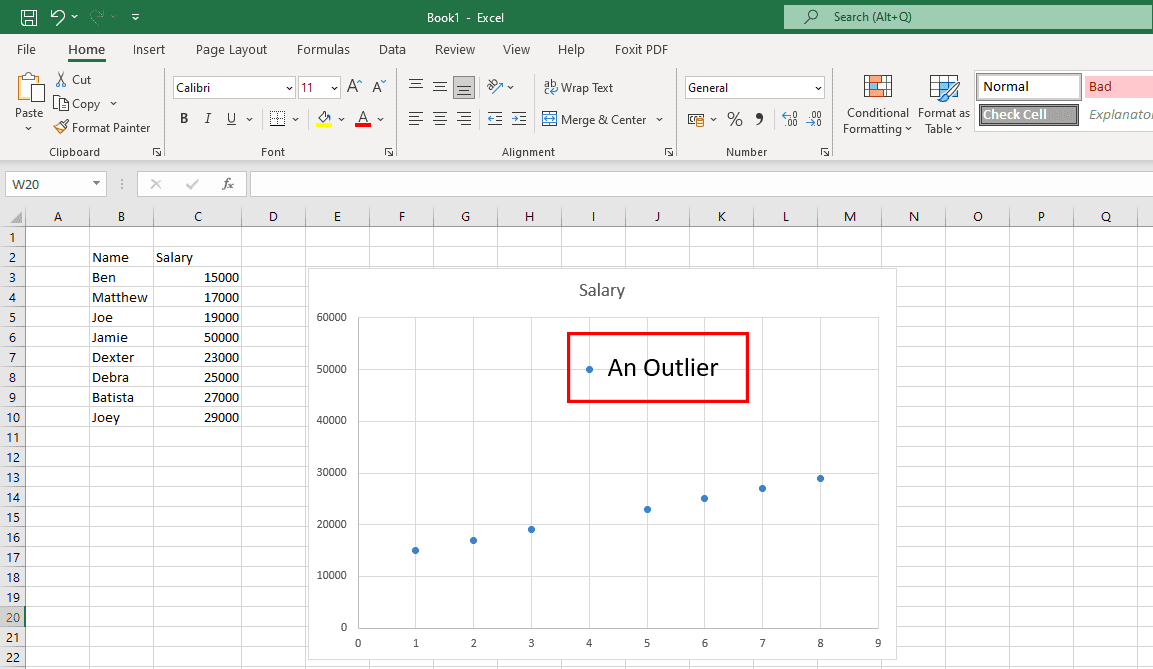
Outliers är ovanliga datapunkter som inte ligger inom datamönstret, som visas i diagrammet ovan. Genuina extremvärden är okej eftersom de hjälper dataforskarna att upptäcka undersökningsbrister. Men om extremvärden kommer från mänskliga fel är det ett problem.
Du måste placera datamängderna i diagram eller grafer för att leta efter extremvärden. Om du hittar någon, undersök källan. Om källan är ett mänskligt fel, ta bort extremdata.
Fokus på strukturdata
Det är mest att hitta och åtgärda fel i datamängderna.
Till exempel innehåller en datauppsättning en kolumn med USD och många kolumner med andra valutor. Om din data är för den amerikanska publiken, konvertera andra valutor till motsvarande USD. Byt sedan ut alla andra valutor i USD.
Skanna dina data
En enorm databas som laddas ner från ett datalager kan innehålla tusentals tabeller. Du kanske inte behöver alla tabeller för ditt datavetenskapsprojekt.
Efter att ha hämtat databasen måste du därför skriva ett skript för att lokalisera de datatabeller du behöver. När du väl vet detta kan du ta bort irrelevanta tabeller och minimera datauppsättningens storlek.
Detta kommer i slutändan att resultera i snabbare upptäckt av datamönster.
Rensa data på molnet
Om din databas använder schema-on-write-metoden måste du konvertera den till schema-on-read. Detta kommer att möjliggöra datarensning direkt på molnlagringen och extrahering av formaterad, organiserad och redo att analysera data.
Översätt främmande språk
Om du gör en undersökning över hela världen kan du förvänta dig främmande språk i rådata. Du måste översätta rader och kolumner som innehåller främmande språk till engelska eller något annat språk du föredrar. Du kan använda datorstödda översättningsverktyg (CAT) för detta ändamål.
Steg-för-steg datarensning
#1. Hitta kritiska datafält
Ett datalager innehåller terabyte av databaser. Varje databas kan innehålla några till tusentals kolumner med data. Nu måste du titta på projektets mål och extrahera data från sådana databaser i enlighet med detta.
Om ditt projekt studerar e-handelstrender för invånare i USA, kommer det inte att göra någon nytta att samla in data om offlinebutiker i samma arbetsbok.
#2. Organisera data

När du har hittat viktiga datafält, kolumnrubriker, tabeller etc. från en databas, samla dem på ett organiserat sätt.
#3. Ta bort dubbletter
Rådata som samlas in från datalager kommer alltid att innehålla dubbla poster. Du måste hitta och ta bort dessa repliker.
#4. Eliminera tomma värden och utrymmen
Vissa kolumnrubriker och deras motsvarande datafält kanske inte innehåller några värden. Du måste ta bort dessa kolumnrubriker/fält eller ersätta tomma värden med de rätta alfanumeriska.
#5. Utför finformatering
Datauppsättningar kan innehålla onödiga mellanslag, symboler, tecken etc. Du måste formatera dessa med formler så att den övergripande datamängden ser enhetlig ut i cellstorlek och spann.
#6. Standardisera processen
Du måste skapa en SOP som datavetenskapsteamets medlemmar kan följa och göra sin plikt under datarensningsprocessen. Den måste innehålla följande:
- Frekvens för insamling av rådata
- Handledare för rådatalagring och underhåll
- Rengöringsfrekvens
- Ren datalagring och underhållsövervakare
Här är några populära datarensningsverktyg som kan hjälpa dig i dina datavetenskapliga projekt:
WinPure

Om du letar efter ett program som låter dig rengöra och skrubba data exakt och snabbt är WinPure en pålitlig lösning. Detta branschledande verktyg erbjuder en datarensningsanläggning på företagsnivå med oöverträffad hastighet och precision.
Eftersom den är designad för att tjäna enskilda användare och företag kan vem som helst använda den utan problem. Programvaran använder funktionen Advanced Data Profiling för att analysera typer, format, integritet och datavärde för kvalitetskontroll. Dess kraftfulla och intelligenta datamatchningsmotor väljer perfekta matchningar med minimala falska matchningar.
Förutom ovanstående funktioner erbjuder WinPure också fantastiska bilder för all data, gruppmatcher och icke-matchningar.
Det fungerar också som ett sammanslagningsverktyg som sammanfogar dubbletter av poster för att generera en masterpost som kan behålla alla aktuella värden. Dessutom kan du använda det här verktyget för att definiera regler för val av masterpost och ta bort alla poster direkt.
OpenRefine
OpenRefine är ett gratis och öppen källkodsverktyg som hjälper dig att omvandla din röriga data till ett rent format som kan användas för webbtjänster. Den använder fasetter för att rensa stora datamängder och arbetar på filtrerade datauppsättningsvyer.
Med hjälp av kraftfull heuristik kan verktyget slå samman liknande värden för att bli av med alla inkonsekvenser. Den erbjuder avstämningstjänster så att användare kan matcha sina datauppsättningar med externa databaser. Genom att använda det här verktyget kan du dessutom återgå till den äldre datauppsättningsversionen om det behövs.
Användare kan också spela upp operationshistorik på en uppdaterad version. Om du är orolig för datasäkerhet är OpenRefine det rätta alternativet för dig. Det rensar dina data på din maskin, så det finns ingen datamigrering till molnet för detta ändamål.
Trifacta Designer Cloud

Även om datarensning kan vara komplex, gör Trifacta Designer Cloud det enklare för dig. Den använder en ny metod för dataförberedelse för dataskrubbning så att organisationer kan få ut det mesta värdet av det.
Dess användarvänliga gränssnitt gör det möjligt för icke-tekniska användare att rengöra och skrubba data för sofistikerad analys. Nu kan företag göra mer med sin data genom att utnyttja de ML-drivna intelligenta förslagen från Trifacta Designer Cloud.
Dessutom kommer de att behöva investera mindre tid i den här processen samtidigt som de måste hantera mindre antal misstag. Det kräver att du använder minskade resurser för att få ut mer av analysen.
Cloudingo
Är du en Salesforce-användare orolig för kvaliteten på den insamlade datan? Använd Cloudingo för att rensa upp kunddata och bara ha nödvändig data. Denna applikation gör det enkelt att hantera kunddata med funktioner som deduplicering, import och migrering.
Här kan du kontrollera postsammanslagning med anpassningsbara filter och regler och standardisera data. Ta bort värdelösa och inaktiva data, uppdatera saknade datapunkter och se till att postadresserna i USA är korrekta.
Dessutom kan företag schemalägga Cloudingo att deduplicera data automatiskt så att du alltid kan ha tillgång till ren data. Att hålla data synkroniserad med Salesforce är en annan viktig egenskap hos det här verktyget. Med den kan du till och med jämföra Salesforce-data med information som lagras i ett kalkylblad.
ZoomInfo

ZoomInfo är en leverantör av datarensningslösningar som bidrar till ditt teams produktivitet och effektivitet. Företag kan uppleva mer lönsamhet eftersom denna programvara levererar kopieringsfri data till företagets CRM och MATs.
Det förenklar datakvalitetshanteringen genom att ta bort alla kostsamma dubbletter av data. Användare kan också säkra sin CRM- och MAT-omkrets med ZoomInfo. Det kan rensa data inom några minuter med automatisk deduplicering, matchning och normalisering.
Användare av denna applikation kan njuta av flexibilitet och kontroll över matchande kriterier och sammanslagna resultat. Det hjälper dig att bygga ett kostnadseffektivt datalagringssystem genom att standardisera alla typer av data.
Slutord
Du bör vara bekymrad över kvaliteten på indata i dina datavetenskapliga projekt. Det är grundflödet för stora projekt som maskininlärning (ML), neurala nätverk för AI-baserad automation, etc. Om flödet är felaktigt, tänk på vad som skulle bli resultatet av sådana projekt.
Därför måste din organisation anta en beprövad datarensningsstrategi och implementera den som ett standardförfarande (SOP). Följaktligen kommer kvaliteten på indata också att förbättras.
Om du är tillräckligt upptagen med projekt, marknadsföring och försäljning är det bättre att lämna datarensningsdelen till experterna. Experten kan vara något av ovanstående datarensningsverktyg.
Du kanske också är intresserad av ett serviceschema för att implementera datarensningsstrategier utan ansträngning.