MapReduce erbjuder en effektiv, snabbare och mer ekonomisk metod för att skapa applikationer.
Denna modell använder avancerade principer som parallell bearbetning och datalokalisering, vilket ger betydande fördelar för både programmerare och organisationer.
Det finns dock ett stort antal programmeringsmodeller och ramverk tillgängliga, vilket kan göra det svårt att välja rätt.
Särskilt när det gäller hantering av Big Data är det viktigt att välja teknik som kan hantera stora datamängder effektivt.
MapReduce framstår som en kraftfull lösning för detta behov.
I den här artikeln kommer jag att utforska vad MapReduce faktiskt är och vilka fördelar det kan ge.
Låt oss sätta igång!
Vad är MapReduce?
MapReduce är en programmeringsmodell eller ett mjukvaruramverk som ingår i Apache Hadoop-ekosystemet. Det används för att utveckla applikationer som kan bearbeta stora datamängder parallellt på tusentals noder (kallas kluster eller nätverk) med inbyggd feltolerans och tillförlitlighet.
Denna databearbetning sker i den databas eller det filsystem där data lagras. MapReduce kan samverka med Hadoop File System (HDFS) för att effektivt komma åt och hantera stora datavolymer.
Ramverket introducerades av Google 2004 och har populariserats av Apache Hadoop. Det fungerar som ett bearbetningslager eller en motor inom Hadoop och kan köra MapReduce-program utvecklade i olika programmeringsspråk, som Java, C++, Python och Ruby.
MapReduce-program inom cloud computing körs parallellt, vilket gör dem väl lämpade för storskalig dataanalys.
MapReduce strävar efter att dela upp en uppgift i mindre, parallella deluppgifter genom att använda funktionerna ”map” och ”reduce”. Varje deluppgift kartläggs och reduceras sedan till mer hanterbara enheter, vilket resulterar i minskad belastning och resursanvändning i klusternätverket.
Låt oss ta ett exempel: Om du planerar en måltid för många gäster, skulle det vara överväldigande och tidskrävande att förbereda all mat och utföra alla processer på egen hand.
Men om du involverar några vänner eller kollegor (inte gästerna) för att hjälpa dig med matlagningen genom att fördela olika processer till dem, kan ni utföra uppgifterna samtidigt. Då blir maten klar mycket snabbare och enklare, samtidigt som dina gäster kan vänta i lugn och ro.
MapReduce fungerar på ett liknande sätt med distribuerade uppgifter och parallell bearbetning, vilket möjliggör ett snabbare och smidigare sätt att slutföra en given uppgift.
Apache Hadoop ger programmerare möjligheten att använda MapReduce för att köra modeller på stora distribuerade datamängder och använda avancerad maskininlärning samt statistiska metoder för att identifiera mönster, göra förutsägelser, upptäcka korrelationer och mer.
Funktioner i MapReduce
Några av de viktigaste funktionerna i MapReduce inkluderar:
- Användargränssnitt: Ett intuitivt användargränssnitt ger detaljerad information om varje aspekt av ramverket. Detta gör det enkelt att konfigurera, implementera och finjustera dina uppgifter.
- Nyttolast: Applikationer använder gränssnitten Mapper och Reducer för att aktivera kartläggnings- och reduceringsfunktionerna. Mappern omvandlar ingående nyckel-värdepar till mellanliggande nyckel-värdepar. Reducer används för att reducera mellanliggande nyckel-värdepar med samma nyckel till ett mindre antal värden. Den utför tre primära funktioner: sortering, blandning och reducering.
- Partitioner: Den hanterar uppdelningen av de mellanliggande kartutmatningsnycklarna.
- Reporter: Denna funktion används för att rapportera förloppet, uppdatera räknare och ange statusmeddelanden.
- Räknare: Representerar globala räknare som definieras av en MapReduce-applikation.
- OutputCollector: Samlar in utdata från Mapper eller Reducer i stället för mellanliggande utdata.
- RecordWriter: Skriver utdata eller nyckel-värdepar till utdatafilen.
- DistributedCache: Distribuerar effektivt större, skrivskyddade filer som är specifika för applikationen.
- Datakomprimering: Applikationsskrivaren kan komprimera både jobbutdata och mellanliggande kartutdata.
- Felaktig posthoppning: Du kan ignorera vissa felaktiga poster under bearbetningen av dina kartinmatningar. Denna funktion kan styras genom klassen SkipBadRecords.
- Felsökning: Du kan köra användardefinierade skript och aktivera felsökning. Om en uppgift i MapReduce misslyckas kan du använda ditt felsökningsskript för att identifiera problemen.
MapReduce-arkitektur
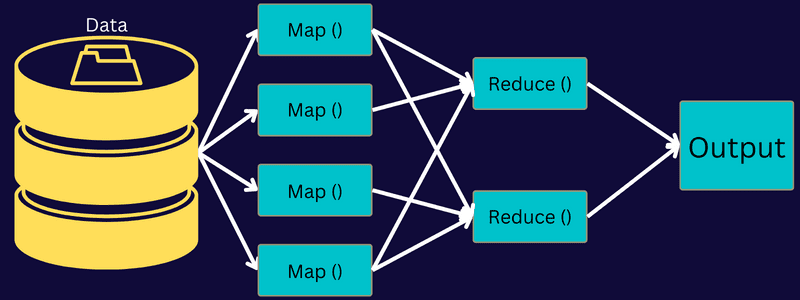
Låt oss utforska arkitekturen i MapReduce genom att undersöka dess komponenter mer i detalj:
- Jobb: Ett jobb i MapReduce är den faktiska uppgift som MapReduce-klienten vill utföra. Det består av flera mindre deluppgifter som tillsammans utgör den kompletta uppgiften.
- Jobbhistorikserver: Denna demonprocess lagrar all historisk data om en applikation eller uppgift, som loggar som genereras före eller efter att ett jobb har körts.
- Klient: En klient (ett program eller API) skickar ett jobb till MapReduce för exekvering eller bearbetning. I MapReduce kan en eller flera klienter kontinuerligt skicka jobb till MapReduce Manager för bearbetning.
- MapReduce Master: MapReduce Master delar upp ett jobb i flera mindre delar och säkerställer att uppgifterna fortskrider parallellt.
- Jobbdelar: De mindre deluppgifterna eller jobbdelarna skapas genom att dela upp det ursprungliga jobbet. De bearbetas och slås sedan samman för att skapa den slutgiltiga uppgiften.
- Indata: Datamängden som matas in i MapReduce för uppgiftsbearbetning.
- Utdata: Slutresultatet som erhålls efter att uppgiften har bearbetats.
Här är flödet: Klienten skickar ett jobb till MapReduce Master, som i sin tur delar upp jobbet i mindre, likvärdiga delar. Detta möjliggör snabbare bearbetning av jobbet eftersom mindre deluppgifter kräver mindre tid än en större.
Det är dock viktigt att inte dela upp uppgifterna i alltför små enheter, eftersom det kan leda till onödig overhead för att hantera dessa splittringar och slösa bort tid.
Därefter görs jobbdelarna tillgängliga för kart- och reduceringsuppgifterna. Programmen för kart- och reduceringsuppgifterna väljs baserat på det användningsfall som teamet arbetar med. Programmeraren utvecklar logikbaserad kod för att uppfylla kraven.
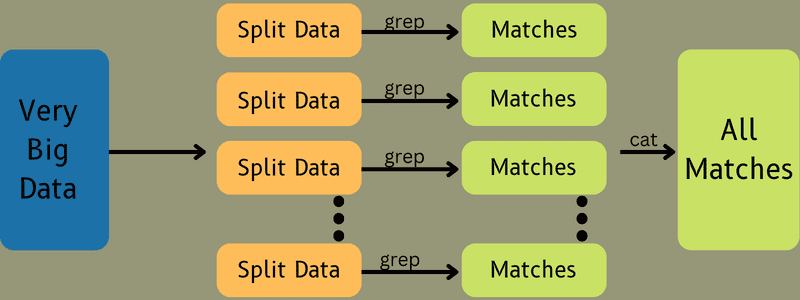
Efter det matas indata till kartuppgiften så att den snabbt kan generera utdata som ett nyckel-värdepar. Dessa data lagras på en lokal disk, i stället för HDFS, för att minska risken för replikering.
När uppgiften är slutförd kan resultatet kasseras. Replikering skulle vara onödigt om utdata lagrades på HDFS. Utdata från varje kartuppgift matas sedan till reduceringsuppgiften, där de levereras till den maskin som utför reduceringsuppgiften.
Därefter slås utdata samman och skickas till den reduceringsfunktion som definierats av användaren. Slutligen lagras den reducerade utdatan på HDFS.
Denna process kan involvera flera kart- och reduceringsuppgifter för databearbetning, beroende på det specifika målet. Map- och Reduce-algoritmerna är optimerade för att minimera tids- eller rumskomplexiteten.
Eftersom MapReduce i huvudsak handlar om kart- och reduceringsuppgifter, är det viktigt att förstå dem mer ingående. Låt oss nu undersöka faserna i MapReduce för att få en tydligare bild av dessa koncept.
Faser i MapReduce
Kartläggning
I den här fasen mappas indata till utdata eller nyckel-värdepar. Nyckeln kan representera ID för en adress, medan värdet kan vara det faktiska värdet för den adressen.
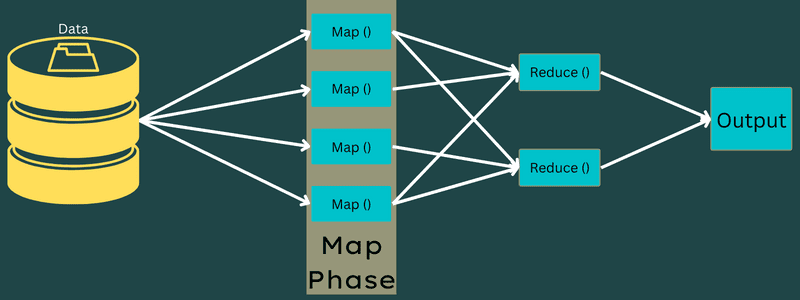
Det finns två primära uppgifter i den här fasen: uppdelning och kartläggning. Uppdelning syftar på underdelarna eller jobbdelarna som kommer från huvudjobbet. Dessa kallas också för indatauppdelningar. En indatauppdelning kan betraktas som en databit som används av en karta.
Därefter genomförs kartläggningsuppgiften, som är den första fasen när ett kartreduceringsprogram körs. Data som finns i varje uppdelning skickas till en kartfunktion för att bearbeta och generera utdata.
Funktionen Map() körs i minnet på de ingående nyckel-värdeparen och skapar ett mellanliggande nyckel-värdepar. Detta nya nyckel-värdepar fungerar som indata som skickas till funktionen Reduce() eller Reducer.
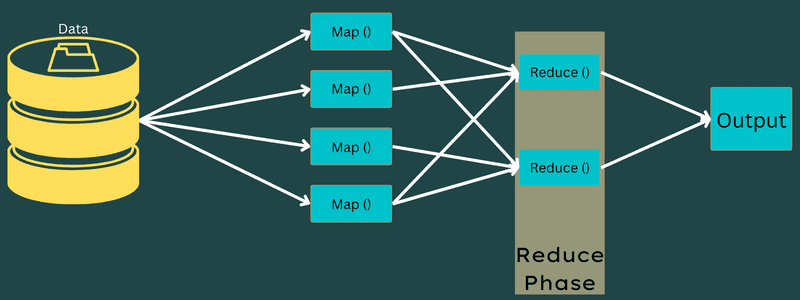
Reducering
De mellanliggande nyckel-värdeparen som erhålls i kartläggningsfasen fungerar som indata för funktionen Reducer eller Reducer. Precis som i kartläggningsfasen ingår här två uppgifter: blandning och reducering.
De erhållna nyckel-värdeparen sorteras och blandas för att matas till Reducer. Därefter grupperar eller aggregerar Reducer data enligt dess nyckel-värdepar, baserat på den reduceringsalgoritm som utvecklaren har skrivit.
Värdena från blandningsfasen kombineras för att returnera ett utdatavärde. Denna fas sammanfattar hela datamängden.
Hela processen med att köra kart- och reduceringsuppgifter övervakas av vissa enheter. Dessa är:
- Jobbspårare: En jobbspårare fungerar som en huvudkontrollant som ansvarar för att fullständigt utföra ett inskickat jobb. Jobbspåraren hanterar alla jobb och resurser i ett kluster. Jobbspåraren schemalägger även varje kartuppgift som ska läggas till på en uppgiftsspårare som körs på en specifik datanod.
- Flera uppgiftsspårare: Flera uppgiftsspårare fungerar som underordnade som utför uppgifter enligt instruktionerna från Job Tracker. En uppgiftsspårare placeras på varje nod i klustret och utför kart- och reduceringsuppgifterna.
Detta fungerar eftersom ett jobb kommer att delas upp i flera deluppgifter som körs på olika datanoder inom ett kluster. Jobbspåraren koordinerar uppgiften genom att schemalägga uppgifterna och köra dem på flera datanoder. Därefter utför uppgiftsspåraren på varje datanod delar av jobbet och övervakar varje uppgift.
Uppgiftsspårarna skickar regelbundet statusrapporter till jobbspåraren. De skickar också en ”hjärtslag”-signal till jobbspåraren för att informera om systemets status. Om något fel uppstår kan jobbspåraren schemalägga jobbet på en annan uppgiftsspårare.
Utdatafas: När du kommer till den här fasen kommer du att ha de sista nyckel-värdeparen som genererats av Reducer. Du kan använda en utdataformaterare för att konvertera nyckel-värdeparen och skriva dem till en fil med hjälp av en skivskrivare.
Varför använda MapReduce?
Här är några av de fördelar som MapReduce erbjuder och varför du bör överväga att använda det i dina big data-applikationer:
Parallell bearbetning
Ett jobb kan delas upp på olika noder, där varje nod hanterar en del av jobbet parallellt. Genom att dela upp större uppgifter i mindre minskar komplexiteten. Eftersom olika uppgifter utförs parallellt på olika maskiner istället för en enda, minskar databearbetningstiden betydligt.
Datalokalitet
MapReduce möjliggör att bearbetningsenheten flyttas till data, inte tvärtom.
Traditionellt har uppgifterna flyttats till bearbetningsenheten för bearbetning. Men med den snabba datatillväxten började detta sätt att arbeta medföra utmaningar som högre kostnader, tidsförlust, överbelastning av masternoden, frekventa fel och minskad nätverksprestanda.
MapReduce hjälper till att övervinna dessa problem genom att använda ett omvänt tillvägagångssätt: bearbetningsenheten flyttas till datan. Detta innebär att data distribueras över olika noder, där varje nod bearbetar sin del av den lagrade datan.
Resultatet är kostnadseffektivitet och minskad bearbetningstid eftersom varje nod arbetar parallellt med sin motsvarande datadel. Eftersom varje nod bearbetar en del av data, kommer ingen nod att överbelastas.
Säkerhet

MapReduce-modellen erbjuder förbättrad säkerhet. Den skyddar din applikation från obehörig data och förstärker klustersäkerheten.
Skalbarhet och flexibilitet
MapReduce är ett mycket skalbart ramverk. Det gör det möjligt att köra applikationer från flera maskiner, med data som omfattar tusentals terabyte. Det erbjuder också flexibilitet att bearbeta data som kan vara strukturerad, semistrukturerad eller ostrukturerad och i olika format och storlekar.
Enkelhet
MapReduce-program kan skrivas i olika programmeringsspråk som Java, R, Perl och Python. Det gör det enkelt för alla att lära sig och skriva program samtidigt som deras databearbetningsbehov uppfylls.
Användningsfall för MapReduce
- Fulltextindexering: MapReduce används för fulltextindexering. Dess Mapper kan mappa varje ord eller fras i ett dokument och Reducer används för att skriva alla mappade element till ett index.
- Beräkning av PageRank: Google använder MapReduce för att beräkna sidrankningen (PageRank).
- Logganalys: MapReduce kan användas för att analysera loggfiler. Det kan dela upp en stor loggfil i olika delar, eller dela upp samtidigt som kartläggaren söker efter tillgängliga webbsidor.
Ett nyckel-värdepar skickas till reduceraren om en webbsida upptäcks i loggen. Här kommer webbsidan att vara nyckeln och indexet ”1” är värdet. Efter att ett nyckel-värdepar skickats till Reducer kommer olika webbsidor att samlas. Slutresultatet är det totala antalet träffar för varje webbsida.

- Omvänd webblänksgraf: Ramverket kan också användas för omvänd webblänksgraf. Här ger Map() URL-målet och källan, och tar input från källan eller webbsidan.
Därefter sammanställer Reduce() listan över alla källadresser som är kopplade till måladdressen och matar sedan ut källorna och målet.
- Ordräkning: MapReduce används för att räkna hur många gånger ett ord förekommer i ett visst dokument.
- Global uppvärmning: Organisationer, regeringar och företag kan använda MapReduce för att ta itu med problem relaterade till global uppvärmning.
Till exempel kan du vilja undersöka den ökade havstemperaturen på grund av global uppvärmning. För det kan du samla in stora mängder data över hela världen, till exempel hög temperatur, låg temperatur, latitud, longitud, datum och tid. Detta kräver flera kart- och reduceringsuppgifter för att beräkna utdata med MapReduce.
- Läkemedelsförsök: Traditionellt har datavetare och matematiker samarbetat för att formulera nya mediciner för att bekämpa sjukdomar. Genom spridningen av algoritmer och MapReduce kan IT-avdelningar enkelt ta itu med problem som tidigare endast hanterades av superdatorer, doktorander, med mera. Nu kan effektiviteten hos en medicin undersökas i en grupp patienter.
- Övriga tillämpningar: MapReduce kan bearbeta storskalig data som inte passar i en relationsdatabas. Det använder också datavetenskapliga verktyg och låter dem köras på distribuerade datamängder, vilket tidigare bara var möjligt på en enda dator.
MapReduces robusthet och mångsidighet har lett till dess användning inom militären, näringslivet, vetenskapen och många andra områden.
Slutsats
MapReduce kan vara en teknik som har förändrat spelplanen. Det är inte bara en snabbare och enklare process utan också kostnadseffektiv och mindre tidskrävande. Med tanke på dess fördelar och ökande användning kommer det troligen att bli mer utbrett i branscher och organisationer.
Du kan också undersöka några av de bästa resurserna för att lära dig mer om Big Data och Hadoop.