Introduktion till Prometheus övervakningssystem
Prometheus är ett statistikbaserat övervakningssystem med öppen källkod. Det fungerar genom att samla in data från olika tjänster och servrar. Denna datainsamling sker genom att systemet skickar HTTP-förfrågningar till specifika slutpunkter som exponerar mätvärden. De insamlade resultaten lagras sedan i en tidsseriedatabas, vilket gör dem tillgängliga för vidare analys och alarmering.
Varför är övervakning viktig?
- Övervakning möjliggör tidiga varningar vid fel, helst innan problemen eskalerar. Detta ger möjlighet till omedelbar åtgärd.
- Den tillhandahåller värdefull insikt för analys, felsökning och effektiv problemlösning.
- Med övervakning kan man observera trender och förändringar över tid, till exempel antalet aktiva sessioner vid en given tidpunkt. Detta underlättar designbeslut och kapacitetsplanering.
Övervakning fokuserar i regel på att spåra olika händelser. Exempel på händelser kan vara mottagande av HTTP-förfrågningar, generering av svar, diskoperationer och användarinloggningar. Övervakning av ett system kan omfatta profilering, loggning, spårning, mätvärden, varningar och visualisering.
Blackbox- kontra Whitebox-övervakning
Övervakning kan delas upp i två huvudkategorier:
Blackbox-övervakning
I blackbox-övervakning sker datainsamlingen utifrån, vanligtvis på applikations- eller värdnivå. Detta tillvägagångssätt kan vara begränsande eftersom man inte får insyn i systemets interna funktioner.
Whitebox-övervakning
Whitebox-övervakning fokuserar på systemets interna funktioner. Det ger tillgång till data om de interna komponenternas status och prestanda.
De fyra gyllene signalerna
Enligt Google, om du bara kan mäta fyra nyckeltal för ditt användarinriktade system, bör du fokusera på följande, som kallas de fyra gyllene signalerna:
#1. Latens
Den tid det tar för en begäran att bearbetas, oavsett om den lyckas eller misslyckas. Det är viktigt att spåra både framgångsrika och misslyckade förfrågningar.
#2. Trafik
Ett mått på efterfrågan på ditt system. För en webbtjänst brukar detta mätas i antalet HTTP-förfrågningar per sekund.
#3. Fel
Andelen misslyckade förfrågningar.
#4. Mättnad
Hur belastat ditt system är. Ökad latens är ofta en tidig indikator på mättnad. Många system börjar fungera sämre långt innan de når 100 % kapacitetsutnyttjande.
Prometheus mätvärdetyper
Prometheus använder fyra huvudtyper av mätvärden:
#1. Räknare
Värdet på en räknare ökar kontinuerligt. Det kan aldrig minska, men det kan återställas. Om en datainsamling misslyckas betyder det bara att en datapunkt missas. Den kumulativa ökningen registreras vid nästa datainsamling. Exempel:
- Totalt antal mottagna HTTP-förfrågningar
- Antal uppkomna undantagsfall
#2. Mätare
En mätare visar en ögonblicksbild vid en given tidpunkt. Den kan både öka och minska. Om en datainsamling misslyckas förloras en mätning; nästa datainsamling kan visa ett annat värde. Exempel: diskutrymme, minnesanvändning.
#3. Histogram
Ett histogram samplar observationer och räknar dem inom förutbestämda intervall, så kallade hinkar. De används för att mäta till exempel förfrågans längd eller storleken på svar. Man kan till exempel mäta hur länge en specifik HTTP-förfrågan tar. Histogrammet har en uppsättning hinkar, till exempel 1 ms, 10 ms och 25 ms. Istället för att lagra varje varaktighet för varje begäran lagrar Prometheus frekvensen av förfrågningar som hamnar i en viss hink.
#4. Sammanfattning
Liknande histogram, samlar en sammanfattning observationer, ofta varaktigheter eller svarsstorlekar. Den ger ett totalt antal observationer och summan av alla observerade värden. Detta gör det möjligt att beräkna medelvärdet. Till exempel, om du under en minut hade tre förfrågningar som tog 2, 3 och 4 sekunder, blir summan 9 och antalet 3. Medellatensen skulle då vara 3 sekunder.
Komponenter i Prometheus ekosystem
Prometheus-servern
Samlar in mätvärden, lagrar dem, tillhandahåller dem för användning i förfrågningar samt skickar varningar baserat på insamlade data.
Datainsamling (Skrapning)
Prometheus använder en pull-baserad metod för att samla in data. För att hämta mätvärden skickar Prometheus en HTTP-förfrågan, en så kallad skrapning. Skrapningar skickas till definierade mål baserat på dess konfiguration.
Varje mål, vare sig det är statiskt definierat eller dynamiskt upptäckt, skrapas med jämna mellanrum (skrapintervall). Vid varje skrapning läser systemet HTTP-slutpunkten `/metrics` för att inhämta det aktuella tillståndet för klientens mätvärden och sparar dessa värden i Prometheus tidsseriedatabas.
Det finns även andra tidsseriedatabaser för övervakningslösningar som kan vara värda att utforska.
Klientbibliotek
För att övervaka en tjänst måste instrumentering läggas till i koden. Det finns klientbibliotek tillgängliga för alla vanliga programmeringsspråk och körtidsmiljöer. Med hjälp av dessa bibliotek kan din kod börja avge mätvärden med bara några få rader kod. Detta kallas direkt instrumentering. Dessa bibliotek gör det möjligt att definiera interna mätvärden och även exponera dem via en HTTP-slutpunkt. När Prometheus skrapar mätvärdenas HTTP-slutpunkt skickar klientbiblioteket informationen till servern.
Officiella klientbibliotek erbjuds av Prometheus för Go, Java, Python och Ruby. Prometheus har ett öppet ekosystem, och det finns också community-skapade klientbibliotek för bland annat C, PHP, Node.js och C#/.NET.
Exportörer
Många applikationer exponerar mätvärden i format som inte är kompatibla med Prometheus. För dessa och för applikationer som du inte äger eller har tillgång till koden för kan du inte lägga till instrumentering direkt. Exempel på detta är MySQL, Kafka, JMX, HAProxy och NGINX-servrar. I dessa fall används exportörer.
En exportör är ett verktyg som distribueras tillsammans med applikationen du vill hämta statistik från. Den fungerar som en proxy mellan applikationen och Prometheus. Exportören tar emot förfrågningar från Prometheus-servern, samlar in data från applikationens loggar, omvandlar datan till rätt format och skickar det till Prometheus-servern.
Några populära exportörer:
- Windows – för mätvärden från Windows-servrar.
- Node – för mätvärden från Linux-servrar.
- Blackbox – för prestandastatistik för DNS och webbplatser.
- JMX – för statistik från Java-baserade applikationer.
När applikationerna har instrumenterats eller exportörer är på plats behöver du informera Prometheus om var de befinner sig. Detta kan göras genom statisk konfiguration. För dynamiska miljöer kan inte statisk konfiguration användas, och då används istället tjänsteupptäckt.
Varningar
Varningar i Prometheus hanteras i två steg:
Varningsregler skickar varningar till Alertmanager.
Alertmanager hanterar dessa varningar och skickar ut meddelanden med hjälp av flera färdiga integrationer, till exempel e-post, Slack, Hipchat och PagerDuty. Alertmanager kan även hantera tystnad eller aggregering för att minska antalet aviseringar.
Här är en guide för att övervaka Linux-servrar med Prometheus och en instrumentpanel.
Visualisering med instrumentpaneler
Prometheus har ett antal API:er som använder PromQL-frågor för att generera rådata för visualiseringar.
Även om Prometheus inkluderar en uttryckswebbläsare för ad hoc-frågor, är Grafana det mest användbara verktyget. Grafana är fullt integrerat med Prometheus och kan skapa ett stort antal olika instrumentpaneler.
Du behöver konfigurera Prometheus som datakälla för Grafana.
Du kan lägga till instrumentpaneler genom att:
- Importera community-skapade instrumentpaneler
- Skapa egna instrumentpaneler
- Använda en fördefinierad instrumentpanel.
Här är ett exempel på hur en fördefinierad instrumentpanel för en nodexportör kan se ut:
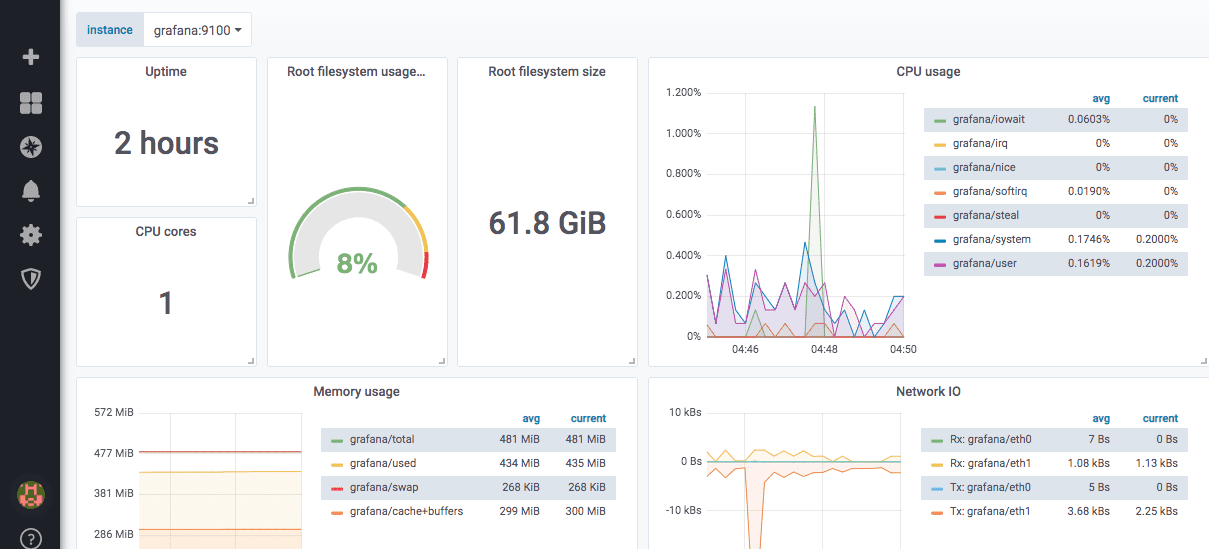
Grafana har en worldPing-modul som möjliggör övervakning av webbplatser och DNS-prestanda globalt.
Sammanfattning
Prometheus har få krav och är enkelt att sätta upp eftersom det är en enda binär med en konfigurationsfil. Systemet kan hantera tusentals mål och miljontals datapunkter per sekund. Prometheus är utformat för att spåra systemets övergripande hälsa, beteende och prestanda.
Grafana är ett kraftfullt verktyg för att visualisera mätvärden och det integreras sömlöst med Prometheus.