Datautvinning, även kallat dataextraktion, är processen att samla in specifik information från webbsidor. Det handlar om att hämta data såsom text, bilder, videoklipp, recensioner och produktinformation. Denna information kan sedan användas för marknadsundersökningar, sentimentanalyser, konkurrentanalyser och för att sammanställa data.
Vid hantering av mindre datamängder kan man manuellt extrahera information genom att kopiera och klistra in det som behövs från webbsidor till ett kalkylblad eller ett dokument i önskat format. Om du till exempel letar efter online-recensioner för att underlätta ett köpbeslut, kan manuell datautvinning vara tillräckligt.
Däremot, när det gäller stora datamängder, är det nödvändigt med en automatiserad teknik för datautvinning. Detta kan innebära att skapa en egen lösning för datautvinning eller att använda sig av ett Proxy API eller Scraping API.
Dessa tekniker kan emellertid vara mindre effektiva eftersom vissa webbplatser skyddas av captchas. Dessutom kan det vara nödvändigt att hantera bots och proxyservrar. Sådana uppgifter kan vara tidskrävande och begränsa mängden data som kan extraheras.
Scraping Browser: En lösning
Alla dessa utmaningar kan övervinnas med hjälp av Scraping Browser från Bright Data. Denna all-in-one webbläsare underlättar insamling av data från webbplatser som annars kan vara svåra att skrapa. Den använder ett grafiskt användargränssnitt (GUI) och styrs av Puppeteer eller Playwright API, vilket gör det svårare för bots att upptäcka webbläsaren.
Scraping Browser har inbyggda funktioner för att hantera blockeringar automatiskt. Webbläsaren körs på Bright Datas servrar, vilket gör att du slipper investera i dyr intern infrastruktur för att skrapa data för storskaliga projekt.
Funktioner i Bright Data Scraping Browser
- Automatisk avblockering av webbplatser: Webbläsaren anpassar sig automatiskt för att hantera CAPTCHA-lösningar, nya blockeringar, fingeravtryck och omförsök, vilket eliminerar behovet av manuella uppdateringar. Scraping Browser emulerar en riktig användare.
- Omfattande proxynätverk: Du kan rikta in dig på vilket land som helst tack vare Scraping Browsers nätverk med över 72 miljoner IP-adresser. Möjligheten finns att rikta in sig på specifika städer eller operatörer med avancerad teknologi.
- Skalbarhet: Du kan ha tusentals sessioner igång samtidigt eftersom webbläsaren använder Bright Datas infrastruktur för att hantera alla förfrågningar.
- Kompatibilitet med Puppeteer och Playwright: Webbläsaren låter dig göra API-anrop och hantera ett valfritt antal webbläsarsessioner med hjälp av Puppeteer (Python) eller Playwright (Node.js).
- Tids- och resursbesparing: Istället för att konfigurera proxyservrar tar Scraping Browser hand om allt i bakgrunden. Du behöver inte heller sätta upp någon egen infrastruktur.
Hur man konfigurerar Scraping Browser
- Gå till Bright Datas webbplats och klicka på ”Scraping Browser” under fliken ”Scraping Solutions”.
- Skapa ett konto. Du kommer att se två alternativ: ”Starta gratis provperiod” och ”Börja gratis med Google”. Välj ”Starta gratis provperiod” och fortsätt. Du kan antingen skapa kontot manuellt eller använda ditt Google-konto.
- Efter att kontot skapats visas en instrumentpanel med flera alternativ. Välj ”Proxies & Scraping Infrastructure”.
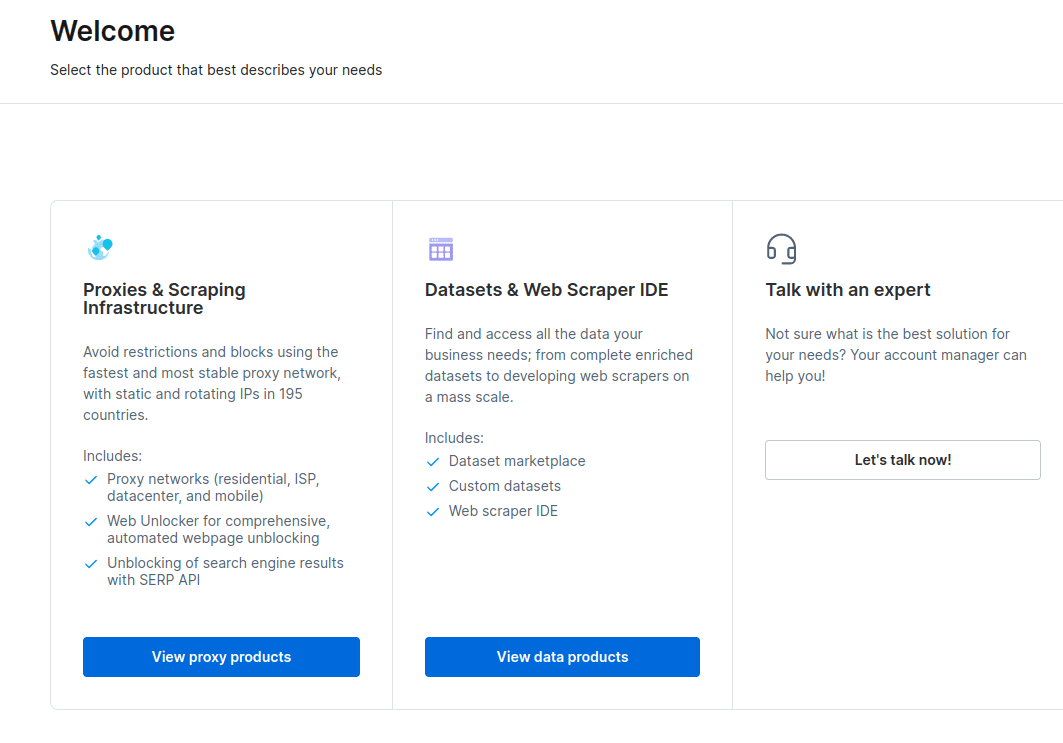
- I det nya fönstret som öppnas, välj Scraping Browser och klicka på ”Kom igång”.
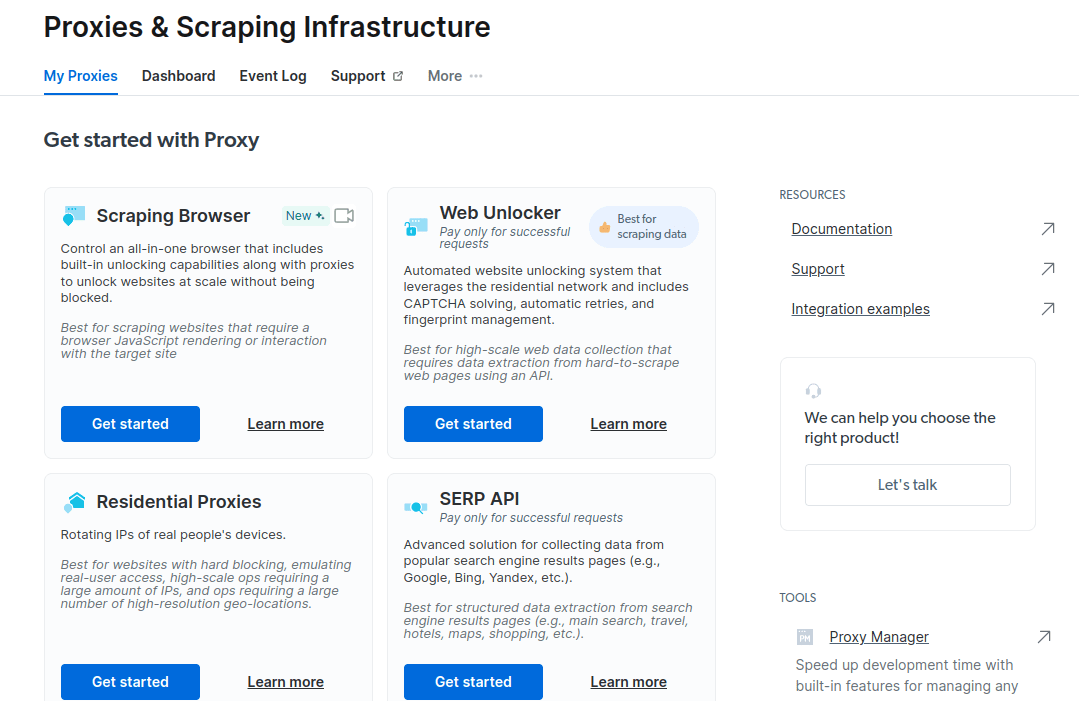
- Spara och aktivera dina inställningar.
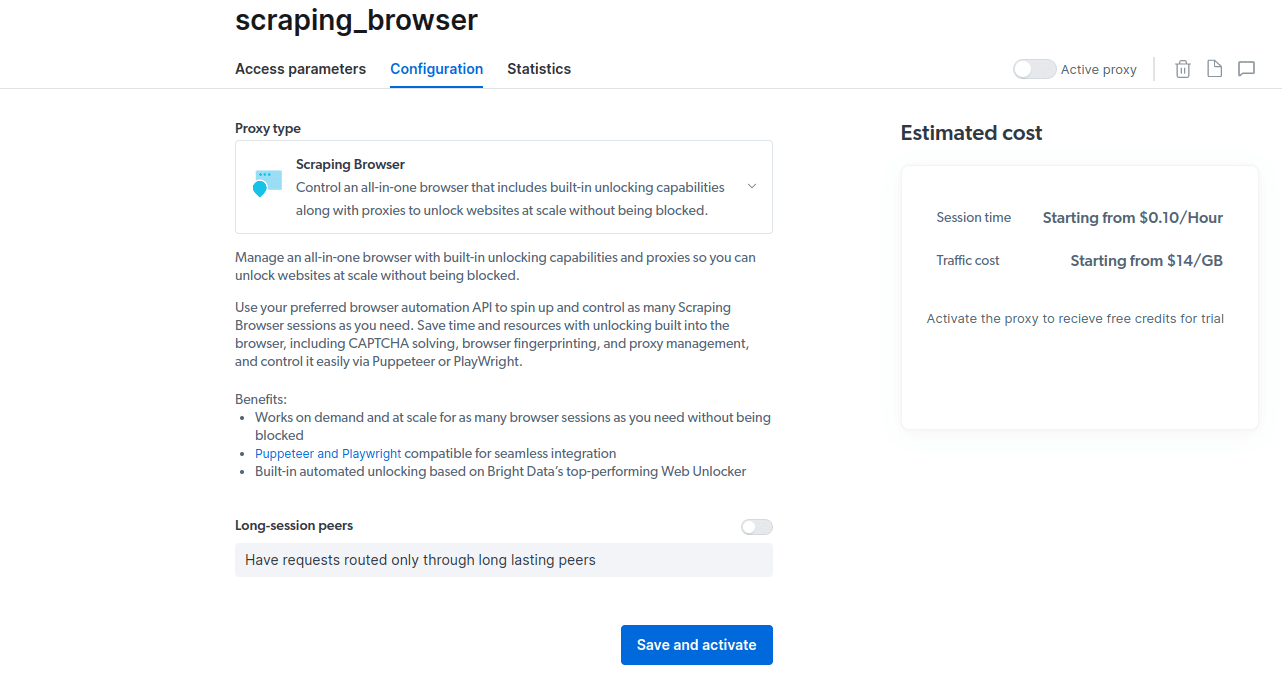
- Aktivera din kostnadsfria provperiod. Det första alternativet ger dig en kredit på $5 som du kan använda för proxyanvändning. Klicka på det första alternativet för att testa produkten. Om du är en storanvändare kan du välja det andra alternativet som ger dig $50 gratis om du laddar ditt konto med $50 eller mer.
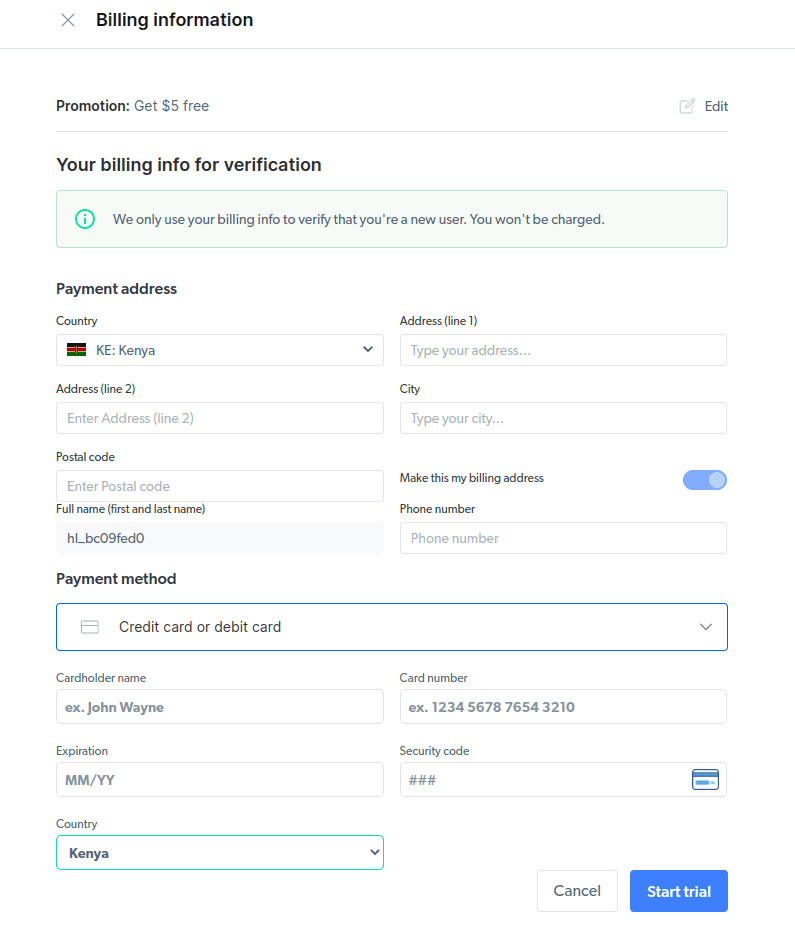
- Ange dina faktureringsuppgifter. Plattformen kommer inte att debitera dig något, detta är bara för att verifiera att du är en ny användare och inte skapar flera konton för att utnyttja gratisperioden.
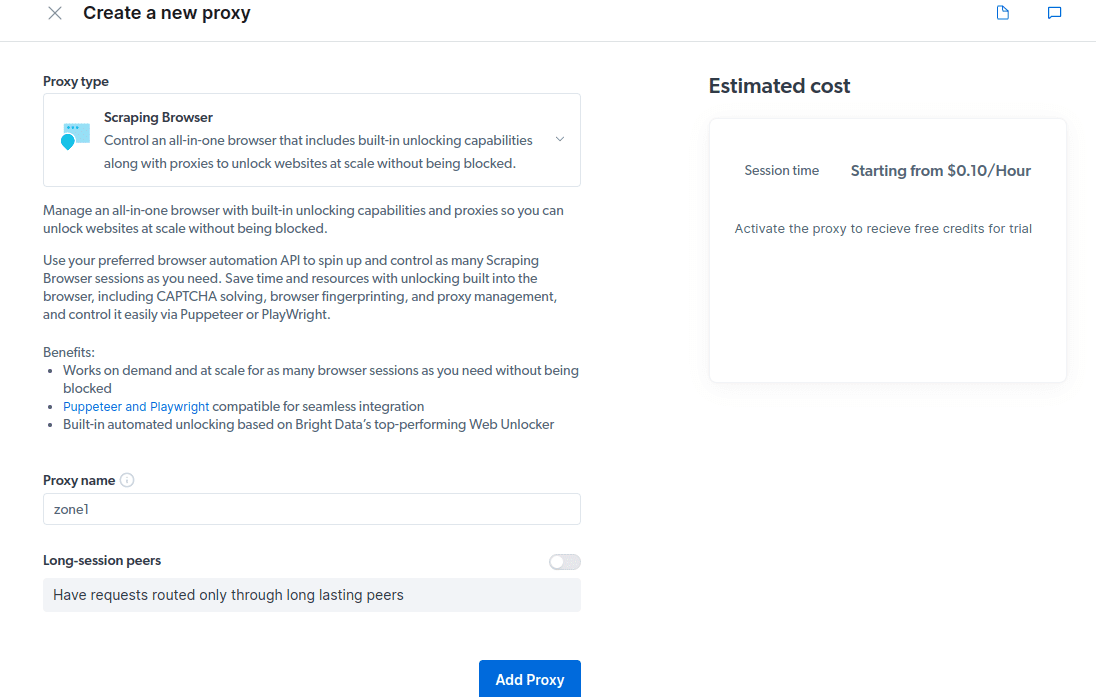
- Skapa en ny proxy. När du har sparat dina faktureringsuppgifter kan du skapa en ny proxy. Klicka på ”+”-ikonen och välj Scraping Browser som din ”Proxy-typ”. Klicka på ”Lägg till proxy” för att fortsätta.
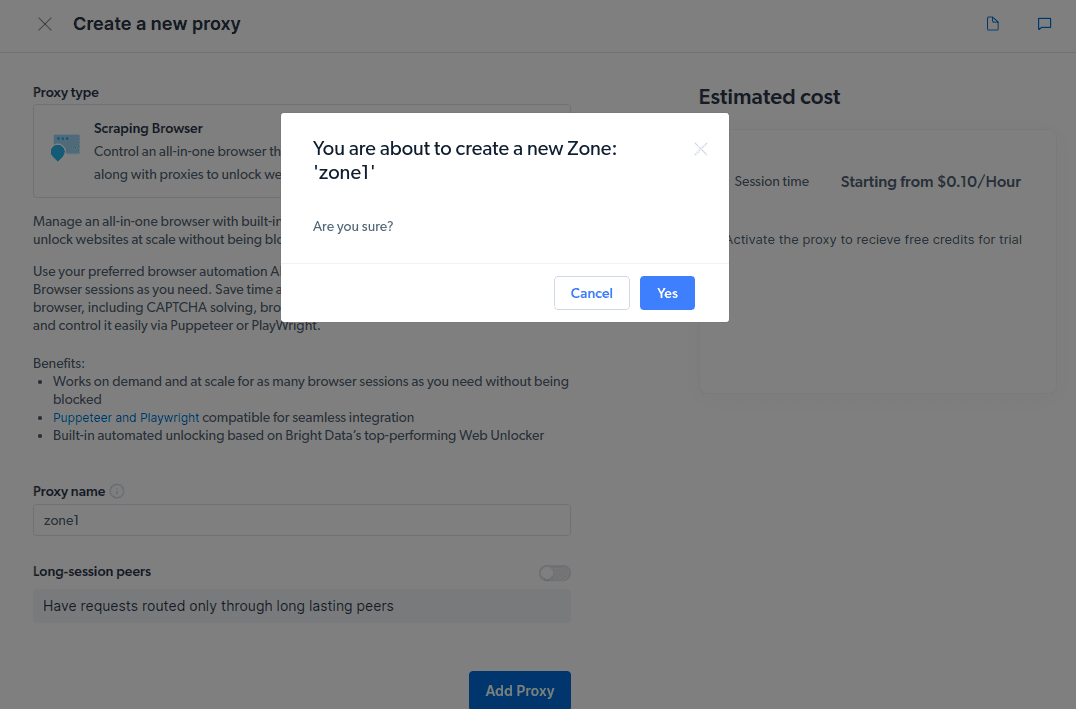
- Skapa en ny ”zon”. En popup visas där du blir tillfrågad om du vill skapa en ny zon; klicka på ”Ja” för att fortsätta.
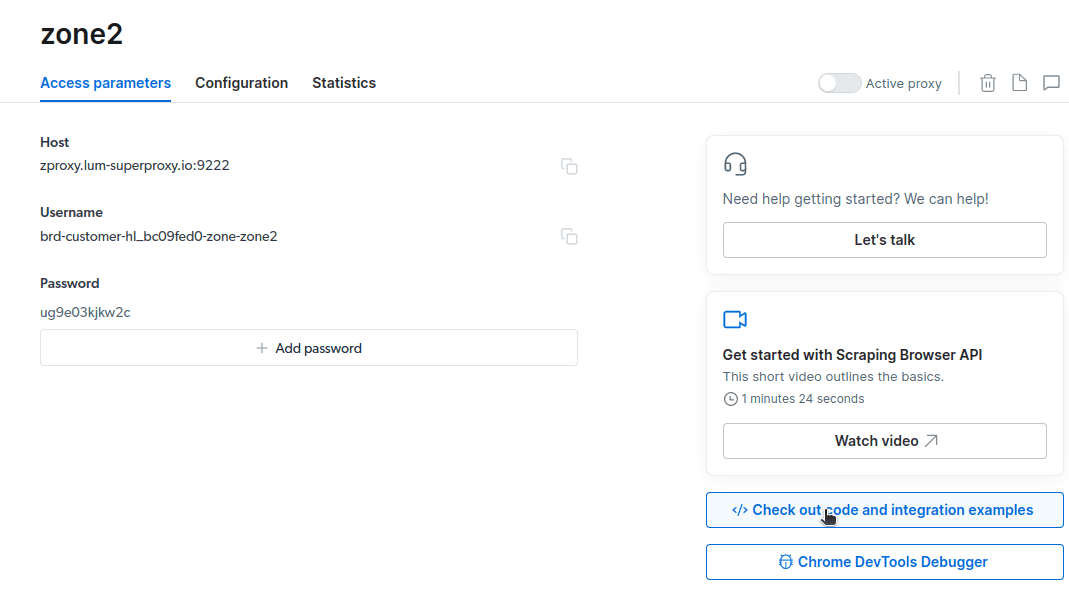
- Klicka på ”Kolla in exempel på kod och integration”. Du får nu exempel på proxyintegration som du kan använda för att skrapa data från din målwebbplats. Du kan använda Node.js eller Python för att extrahera data.
Du har nu allt du behöver för att extrahera data från en webbplats. Vi kommer att använda vår webbplats, adminvista.com, som exempel för att visa hur Scraping Browser fungerar. För den här demonstrationen kommer vi att använda node.js. Du kan följa med om du har node.js installerat.
Följ dessa steg:
npm i puppeteer-core.
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
const auth='ANVÄNDARNAMN:LÖSENORD'; med dina kontouppgifter. Du hittar ditt användarnamn, zonnamn och lösenord under fliken ”Åtkomstparametrar”.Ändra koden på rad 10 till:
await page.goto('https://adminvista.com/authors');
Den färdiga koden ser nu ut så här:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://adminvista.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
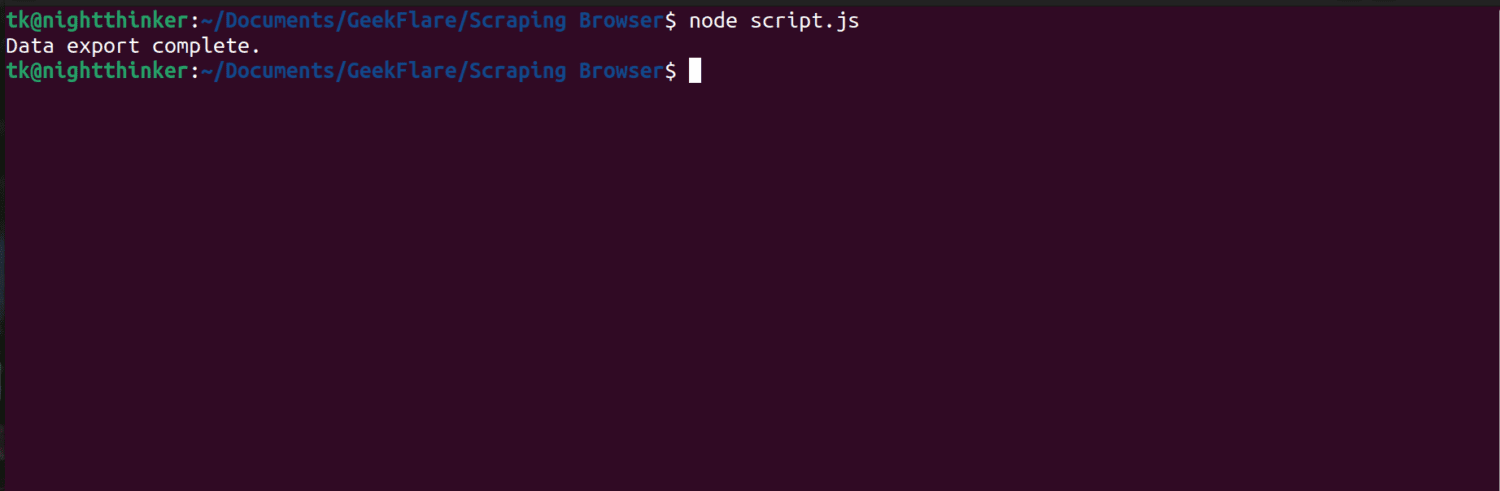
node script.js.Du kommer nu att se något liknande i din terminal.
Hur man exporterar data
Det finns flera sätt att exportera data, beroende på hur den ska användas. I det här exemplet ska vi exportera data till en HTML-fil genom att ändra skriptet så att det skapar en fil som heter data.html istället för att skriva ut informationen i konsolen.
Ändra innehållet i din kod enligt följande:
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://adminvista.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Kör nu koden med kommandot: node script.js.
Som du kan se i skärmdumpen nedan, visas meddelandet ”Data export complete” i terminalen.
Om du tittar i projektmappen kommer du nu att se en fil som heter data.html med tusentals rader kod.
Detta är bara en enkel demonstration av hur man extraherar data med Scraping Browser. Det är möjligt att begränsa datainsamlingen och endast extrahera till exempel författarnas namn och beskrivningar med det här verktyget.
För att använda Scraping Browser, identifiera de datauppsättningar du vill extrahera och modifiera koden därefter. Beroende på vilken webbplats du riktar in dig på och HTML-filens struktur kan du extrahera text, bilder, videor, metadata och länkar.
Vanliga frågor
Är datautvinning och webbskrapning lagligt?
Webbskrapning är ett omdebatterat ämne där vissa anser att det är oetiskt medan andra tycker det är okej. Lagligheten beror på vilken typ av information som skrapas och på webbplatsens policy. Generellt sett anses det olagligt att skrapa personlig information såsom adresser och ekonomiska data. Innan du skrapar data, kontrollera om webbplatsen har några särskilda riktlinjer. Se alltid till att du inte skrapar data som inte är allmänt tillgänglig.
Är Scraping Browser ett gratis verktyg?
Nej, Scraping Browser är en betaltjänst. Om du registrerar dig för en gratis provperiod får du en kredit på $5. De betalda paketen börjar från $15/GB + $0,1/h. Du kan också välja alternativet Pay As You Go som börjar från $20/GB + $0,1/h.
Vad är skillnaden mellan Scraping Browser och huvudlösa webbläsare?
Scraping Browser är en huvudfull webbläsare, vilket innebär att den har ett grafiskt användargränssnitt (GUI). Huvudlösa webbläsare saknar däremot ett grafiskt gränssnitt. Huvudlösa webbläsare som Selenium används för att automatisera webbskrapning men kan vara begränsade eftersom de måste hantera CAPTCHA och botdetektering.
Sammanfattning
Som du ser gör Scraping Browser det enklare att extrahera data från webbsidor. Scraping Browser är användarvänligt jämfört med verktyg som Selenium. Även icke-utvecklare kan använda webbläsaren tack vare det bra användargränssnittet och tydliga dokumentationen. Verktyget har funktioner för att hantera blockeringar som inte finns i andra skrapverktyg, vilket gör det effektivt för alla som vill automatisera sådana processer.
Du kan också undersöka hur du hindrar ChatGPT-plugins från att skrapa innehåll från din webbplats.