I denna artikel utforskar vi vektorisering, en central teknik inom NLP (Natural Language Processing). Vi kommer att undersöka dess betydelse och presentera en omfattande guide till olika metoder för vektorisering.
Vi har tidigare berört grundläggande NLP-koncept och textbearbetning, inklusive tokenisering, normalisering, standardisering och textrensning. Innan vi dyker djupare in i vektorisering, låt oss snabbt repetera vad tokenisering är och hur det relaterar till vektorisering.
Vad är tokenisering?
Tokenisering innebär att dela upp text i mindre enheter, så kallade tokens. Dessa tokens hjälper datorer att förstå och hantera text på ett smidigare sätt.
Exempel: ”Den här artikeln är intressant”
Tokens: [’Den’, ’här’, ’artikeln’, ’är’, ’intressant’]
Vad är vektorisering?
Maskininlärningsmodeller och algoritmer arbetar med numerisk data. Vektorisering är processen att omvandla text eller kategoridata till numeriska vektorer. Genom att konvertera data till numeriskt format kan vi träna modeller mer exakt.
Varför behöver vi vektorisering?
Tokenisering och vektorisering har olika roller inom NLP. Tokenisering bryter ner text i tokens, medan vektorisering omvandlar tokens till numeriska representationer som datorer och maskininlärningsmodeller kan bearbeta.
- Vektorisering är inte bara viktig för att konvertera text till numeriskt format, utan även för att fånga semantisk innebörd.
- Genom vektorisering kan vi reducera dimensionerna i data, vilket ökar effektiviteten. Detta är särskilt användbart vid hantering av stora datamängder.
- Många maskininlärningsalgoritmer, såsom neurala nätverk, kräver numerisk input, och vektorisering möjliggör detta.
Det finns flera olika vektoriseringstekniker, som vi kommer att utforska i den här artikeln.
”Bag of Words” (Påse med ord)
Om vi har en samling dokument eller meningar som vi vill analysera, förenklar ”bag of words” (BoW) denna process genom att behandla varje dokument som en ”påse” fylld med ord. BoW är användbar för textklassificering, sentimentanalys och informationshämtning.
När vi arbetar med stora mängder text hjälper BoW till att representera textdata genom att skapa en ordbok med unika ord. Därefter kodas varje ord som en vektor baserat på dess frekvens i texten. Dessa vektorer består av icke-negativa tal som representerar hur ofta ordet förekommer i dokumentet.
BoW-processen kan delas in i tre steg:
- Tokenisering: Dela upp dokumentet i tokens. Exempel: (Mening: ”Jag gillar pizza och jag gillar hamburgare”)
- Unik ordseparering/Ordboksskapande: Skapa en lista över alla unika ord. Exempel: [”Jag”, ”gillar”, ”pizza”, ”och”, ”hamburgare”]
- Räkna ordförekomster/Vektorskapande: Räkna hur ofta varje unikt ord upprepas och lagra det i en ”gles matris”. I matrisen representerar varje rad en meningsvektor, där kolumnerna motsvarar ordbokens storlek.
Exempel i Python med hjälp av scikit-learn:
from sklearn.feature_extraction.text import CountVectorizer
documents = [
"Detta är det första dokumentet.",
"Detta dokument är det andra dokumentet.",
"Och detta är det tredje.",
"Är detta det första dokumentet?",
]
cv = CountVectorizer()
X = cv.fit_transform(documents)
feature_names = cv.get_feature_names_out()
X_dense = X.toarray()
print("Dokument-Term Matris (DTM):")
print(X_dense)
print("\nFunktionsnamn:")
print(feature_names)
Dokument-Term Matris (DTM):
 |
Funktionsnamn:
 |
Som vi ser består vektorerna av icke-negativa tal som representerar frekvensen av ord i dokumenten. Vi har fyra textdokument och nio unika ord. BoW-modellen kontrollerar om ett unikt ord finns i ett visst dokument. Om ordet finns tilldelas värdet 1 (eller frekvensen), annars 0.
Om vi vill att enstaka ord ska vara en funktion i vokabuläret, kallar vi det en unigram-representation.
Det finns flera bibliotek som kan användas för att implementera BoW, inklusive scikit-learn, Keras och Gensim. BoW är enkel att använda och användbar i många sammanhang. Den har dock vissa begränsningar.
- BoW tilldelar alla ord samma vikt, oavsett deras betydelse. Vissa ord är ofta viktigare än andra.
- BoW räknar bara frekvensen av ord, vilket kan leda till en snedvridning mot vanliga ord som ”det”, ”och” eller ”är”.
- Längre dokument kan ha fler ord och skapa större vektorer, vilket försvårar jämförelser och kan leda till glesa matriser.
För att lösa dessa problem kan vi använda en mer avancerad metod, såsom TF-IDF.
TF-IDF
TF-IDF (Term Frequency – Inverse Document Frequency) är en numerisk representation som används för att bestämma vikten av ord i ett dokument.
Varför TF-IDF istället för Bag of Words?
BoW behandlar alla ord lika och fokuserar på frekvens. TF-IDF däremot värdesätter ord baserat på deras frekvens och unikhet. Vanliga ord ”straffas” så att mindre frekventa, men viktigare ord får högre vikt.
TF (Term Frequency) mäter hur viktigt ett ord är i enskilt dokument.
IDF (Inverse Document Frequency) mäter hur viktigt ett ord är i en hel dokumentsamling.
TF = Antal gånger ett ord förekommer i ett dokument / Totalt antal ord i det dokumentet
DF = Antal dokument som innehåller ord w / Totalt antal dokument
IDF = log(Totalt antal dokument / Antal dokument som innehåller ord w)
IDF är omvänt proportionell mot DF. Ju vanligare ett ord är i alla dokument, desto mindre viktigt är det i ett enskilt dokument.
Slutlig TF-IDF poäng: TF-IDF = TF * IDF
TF-IDF används för att identifiera vilka ord som är vanliga i ett visst dokument, men unika för alla dokument. Dessa ord är ofta nyckeln till dokumentets huvudtema.
Exempel:
Doc1 = ”Jag gillar maskininlärning”
Doc2 = ”Jag gillar adminvista.com”
Vi skapar en ordbok: Ordbok = [”Jag”, ”gillar”, ”maskin”, ”inlärning”, ”adminvista.com”]
Vi beräknar TF och IDF för varje ord.
TF:
- För ”Jag”: TF i Doc1: 1/4 = 0.25; TF i Doc2: 1/3 ≈ 0.33
- För ”gillar”: TF i Doc1: 1/4 = 0.25; TF i Doc2: 1/3 ≈ 0.33
- För ”maskin”: TF i Doc1: 1/4 = 0.25; TF i Doc2: 0/3 ≈ 0
- För ”inlärning”: TF i Doc1: 1/4 = 0.25; TF i Doc2: 0/3 ≈ 0
- För ”adminvista.com”: TF i Doc1: 0/4 = 0; TF i Doc2: 1/3 ≈ 0.33
IDF:
- För ”Jag”: IDF är log(2/2) = 0
- För ”gillar”: IDF är log(2/2) = 0
- För ”maskin”: IDF är log(2/1) = log(2) ≈ 0.69
- För ”inlärning”: IDF är log(2/1) = log(2) ≈ 0.69
- För ”adminvista.com”: IDF är log(2/1) = log(2) ≈ 0.69
Slutlig TF-IDF beräkning:
- För ”Jag”: TF-IDF i Doc1: 0.25 * 0 = 0; TF-IDF i Doc2: 0.33 * 0 = 0
- För ”gillar”: TF-IDF i Doc1: 0.25 * 0 = 0; TF-IDF i Doc2: 0.33 * 0 = 0
- För ”maskin”: TF-IDF i Doc1: 0.25 * 0.69 ≈ 0.17; TF-IDF i Doc2: 0 * 0.69 = 0
- För ”inlärning”: TF-IDF i Doc1: 0.25 * 0.69 ≈ 0.17; TF-IDF i Doc2: 0 * 0.69 = 0
- För ”adminvista.com”: TF-IDF i Doc1: 0 * 0.69 = 0; TF-IDF i Doc2: 0.33 * 0.69 ≈ 0.23
TF-IDF Matris ser ut som följande:
I gillar maskin inlärning adminvista.com
Doc1 0.0 0.0 0.17 0.17 0.0
Doc2 0.0 0.0 0.0 0.0 0.23
Höga TF-IDF värden indikerar att ett ord är viktigt i ett dokument, medan låga värden indikerar att det är mindre viktigt.
TF-IDF används i textklassificering, chatbot-information, textextraktion och textsammanfattning.
Exempel i Python:
from sklearn.feature_extraction.text import TfidfVectorizer
text = [
"Detta är det första dokumentet.",
"Detta dokument är det andra dokumentet.",
"Och detta är det tredje.",
"Är detta det första dokumentet?",
]
cv = TfidfVectorizer()
X = cv.fit_transform(text)
feature_names = cv.get_feature_names_out()
X_dense = X.toarray()
print("TF-IDF Matris:")
print(X_dense)
print("\nFunktionsnamn:")
print(feature_names)
TF-IDF Matris:
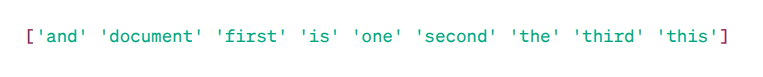 |
Funktionsord:
Som vi kan se, indikerar de decimala värdena hur viktiga orden är i specifika dokument. Vi kan också kombinera ord i grupper om 2, 3, 4 osv. med hjälp av n-gram.
TF-IDF har dock vissa begränsningar. Det fångar inte semantisk innebörd och kontextuell förståelse. Låt oss utforska mer avancerade tekniker.
Word2Vec
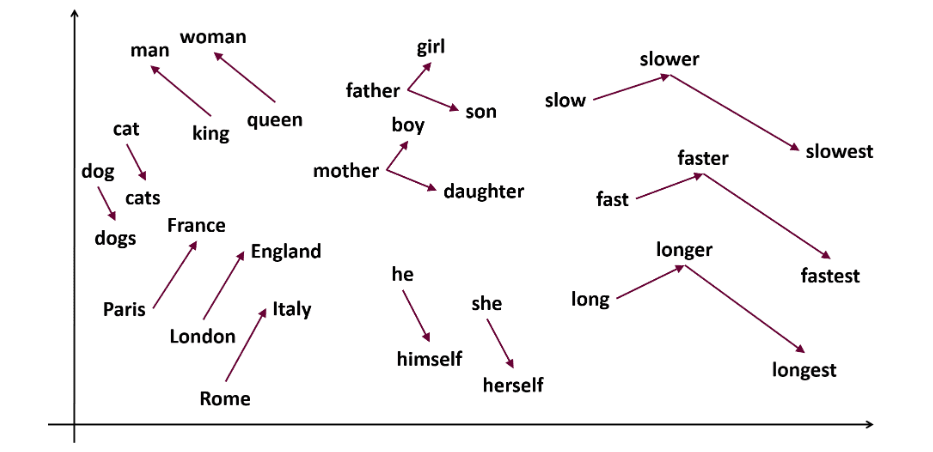
Word2Vec är en populär teknik för ordinbäddning som fångar semantisk och syntaktisk likhet. Det utvecklades av Tomas Mikolov med team på Google år 2013. Word2Vec representerar ord som kontinuerliga vektorer i ett flerdimensionellt utrymme.
Word2Vec strävar efter att representera ord på ett sätt som fångar deras semantiska betydelse. Ordvektorer placeras i ett kontinuerligt vektorutrymme. Exempelvis skulle vektorerna för ”Katt” och ”Hund” vara närmare varandra än vektorerna för ”Katt” och ”Flicka”.
 |
Källa: usna.edu
Det finns två arkitekturer för att skapa ordinbäddningar med Word2Vec:
- CBOW (Continuous Bag of Words): Försöker förutsäga ett ord genom att beräkna ett medelvärde av betydelsen hos närliggande ord. Det tar ett fast fönster av ord, konverterar det till numeriskt format, gör ett medelvärde och använder det för att förutsäga målordet.
Exempel: Förutsäg ordet: ”Räv”
Meningsord: ’den’, ’snabba’, ’bruna’, ’hoppar’, ’över’, ’den’.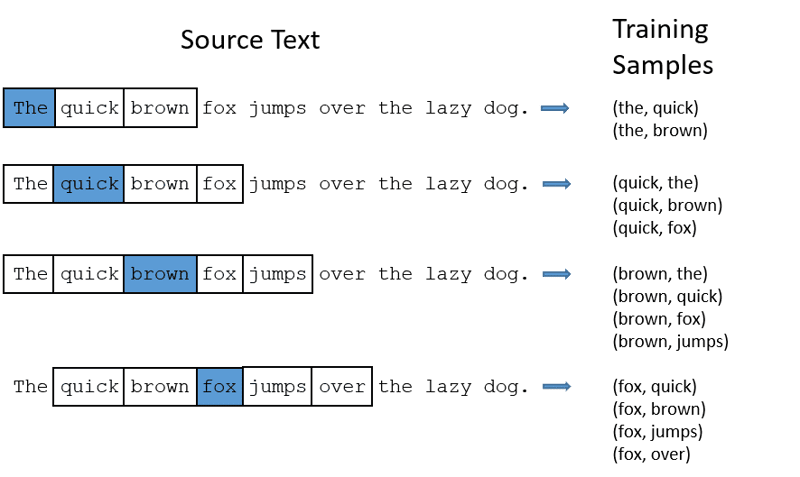
- CBOW använder ett fönster av ord (t.ex. 2 ord till vänster och 2 till höger)
- Konverterar orden till ordinbäddningar
- Beräknar ett medelvärde av inbäddningarna
- Använder detta medelvärde för att förutsäga målordet med ett neuralt nätverk.
- Skip-gram: Förutsäger kontextorden givet ett målord. Skip-gram är bättre på att fånga semantiska samband mellan ord. Exempel: ”Kung – Man + Kvinna = Drottning”
Vi kan träna vår egen Word2Vec modell eller använda en förtränad modell. Vi använder en förtränad modell som exempel.
Exempel i Python med Gensim:
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
sentences = [
"Jag gillar Thor",
"Hulk är en viktig medlem av Avengers",
"Ironman hjälper Spiderman",
"Spiderman är en av de populära medlemmarna av Avengers",
]
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
similar_words = model.wv.most_similar("avengers")
print("Ord som liknar 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Ord som liknar ’avengers’:
 |
Modellen beräknar likhetspoäng baserat på cosinuslikheten mellan orden. Värden mellan -1 och 1 anger likheten. 1 = identiska vektorer, 0 = inga starka kopplingar, -1 = motsatta vektorer.
Besök denna länk för en bättre förståelse av Word2Vec-modeller och visualisering.
GloVe är en annan teknik som liknar Word2Vec, med ordinbäddningar som ofta kräver mindre minne.
GloVe
Global Vectors for Word Representation (GloVe) är en teknik som liknar Word2Vec och representerar ord som vektorer i kontinuerligt utrymme. GloVe försöker producera kontextuella ordinbäddningar och utnyttjar Word2Vecs överlägsna prestanda.
Varför behöver vi GloVe?
Word2Vec är en fönsterbaserad metod och använder endast närliggande ord för att förstå ord. Den semantiska betydelsen av ett ord påverkas endast av dess omgivande ord, vilket kan vara en ineffektiv användning av statistik. GloVe däremot, samlar både global och lokal statistik för ordinbäddningar.
När ska man använda GloVe?
Använd GloVe när du vill fånga bredare semantiska relationer och globala ordassociationer. GloVe presterar bra i named entity recognition, ordanalogi och ordlikhet.
Exempel i Python:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
print(glove_model["cute"])
Vektor för ordet ”söt”:
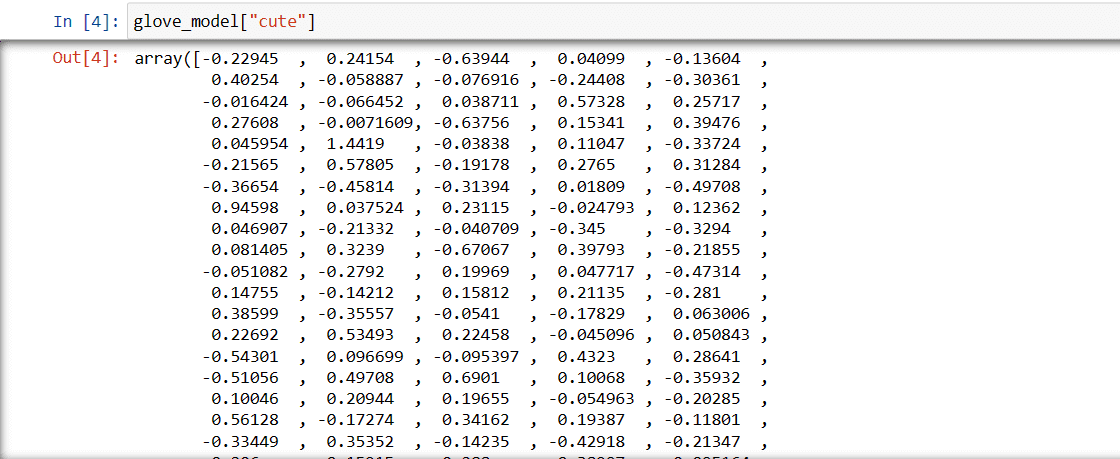 |
Värdena i vektorn fångar ordets betydelse och relationer till andra ord. Positiva värden indikerar positiva associationer, medan negativa indikerar negativa associationer. GloVe tar hänsyn till både global och lokal statistik.
Låt oss hitta några ord som liknar ordet ”pojke”:
print(glove_model.most_similar("boy"))
Topp 10 ord som liknar ”pojke”:
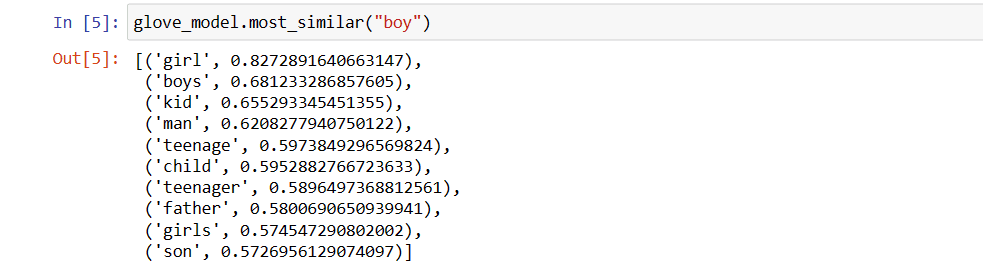 |
Det mest liknande ordet till ”pojke” är ”flicka”.
Låt oss undersöka den semantiska betydelsen av givna ord:
print(glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1))
Det mest relevanta ordet för ”drottning”:
 |
Modellen kan upptäcka relationer mellan ord.
Låt oss visualisera semantiska samband med hjälp av en plot:
vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
tsne_plot(embedding_matrix, vocab)
t-SNE Plot:
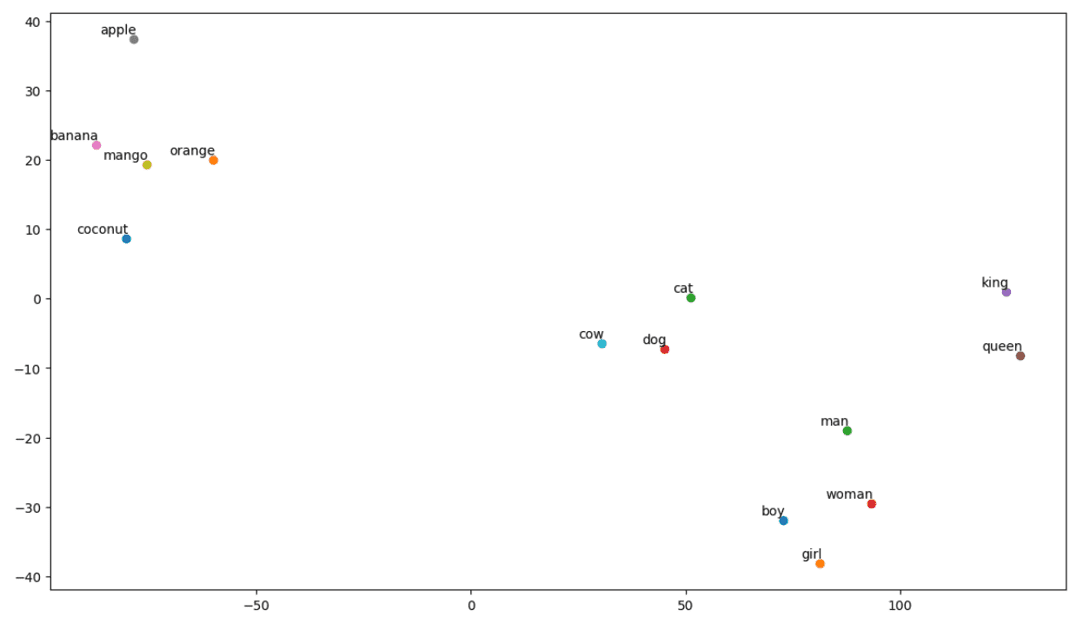 |
Vi ser att ord som ”banan”, ”mango”, ”apelsin”, ”kokos” och ”äpple” grupperas på ena sidan, medan ”ko”, ”hund” och ”katt” grupperas tillsammans eftersom de är djur.
GloVe tränas på samförekomstmatriser och kombinerar lokal och global statistik. Den kan användas i olika NLP-uppgifter.
FastText är en annan populär metod för vektorisering. Låt oss utforska den.
FastText
FastText är ett bibliotek med öppen källkod från Facebooks AI Research för textklassificering och sentimentanalys. FastText tillhandahåller verktyg för att träna ordinbäddningar. FastText stöder både multi-label och multi-class klassificering.
Varför FastText?
FastText är bättre än andra modeller tack vare sin förmåga att generalisera till okända ord. FastText tillhandahåller förtränade ordvektorer för många språk.
 |
Hur fungerar det?
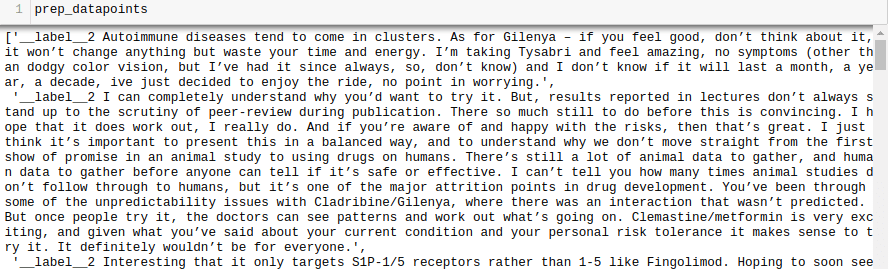
Andra modeller som Word2Vec och GloVe använder ord för ordinbäddning. FastText använder istället bokstäver. Det innebär att det kan generera vektorer även för okända ord. FastText kräver också mindre träningsdata, eftersom ord bildas av tecken vilket ger mer information.
Ordinbäddningarna är en kombination av inbäddningar på lägre nivå.
FastText använder underordsinformation genom tecken-n-gram. Om vi har ordet ”läsa”, skulle tecken-n-gram (3-6 tecken) vara: <lä, läs, äsa, s>, <läs, läsa, äsa>. Parenteserna anger början och slutet av ordet. Istället för att lära sig inbäddningar för varje distinkt n-gram, lär sig modellen inbäddningar för totalt B hinkar. Varje tecken-n-gram mappas till ett heltal med en hashfunktion och indexet har motsvarande inbäddning. Ordinbäddningen fås genom att medelvärdesberäkna dessa inbäddningar.
FastText använder neurala nätverk liknande Word2Vec och kan tränas i två lägen: CBOW och skip-gram.
Vi använder en förtränad modell för att demonstrera hur FastText fungerar.
import fasttext
# (Exempeldata, förberedd enligt formatet nedan)
all_texts = train['text'].tolist()
all_labels = train['drug type'].tolist()
prep_datapoints=[]
for i in range(len(all_texts)):
sample="__label__"+ str(all_labels[i]) + ' '+ all_texts[i]
prep_datapoints.append(sample)
with open('train_fasttext.txt','w') as f:
for datapoint in prep_datapoints:
f.write(datapoint)
f.write('n')
f.close()
model = fasttext.train_supervised('train_fasttext.txt')
# (Visa förutsägelser från modellen)
Datauppsättning:
 |
Träningsdata måste förberedas enligt formatet:
__label__
 |
 |
FastText förutsäger etiketten och en konfidenspoäng. Resultaten beror på en mängd olika variabler, men FastText kan vara ett bra alternativ för en snabb uppfattning om förväntad noggrannhet.
Slutsats
Textvektoriseringsmetoder såsom BoW, TF-IDF, Word2Vec, GloVe och FastText erbjuder olika funktioner för NLP-uppgifter. BoW och TF-IDF är enkla och lämpliga för textklassificering och rekommendationer. Word2Vec fångar semantik och är anpassningsbar för olika NLP-uppgifter. GloVe erbjuder förtränade inbäddningar för sentimentanalys. FastText är bra på underordsanalys och fungerar bra för strukturellt rika språk och enhetsigenkänning. Valet av teknik beror på uppgiften, data och tillgängliga resurser.
Vi kommer att utforska NLP i större detalj i kommande artiklar. Lycka till med inlärningen!
Kolla gärna in de bästa NLP-kurserna om du vill lära dig mer.