
Den här artikeln nämner och förklarar några av de bästa pythonbiblioteken för datavetare och maskininlärningsteamet.
Python är ett idealiskt språk som är känt inom dessa två områden, främst för de bibliotek som det erbjuder.
Detta beror på Python-bibliotekens applikationer som datainmatning/utdata I/O och dataanalys, bland andra datamanipuleringsoperationer som datavetare och maskininlärningsexperter använder för att hantera och utforska data.
Innehållsförteckning
Python-bibliotek, vad är det?
Ett Python-bibliotek är en omfattande samling av inbyggda moduler som innehåller förkompilerad kod, inklusive klasser och metoder, vilket eliminerar behovet för utvecklaren att implementera kod från grunden.
Betydelsen av Python i datavetenskap och maskininlärning
Python har de bästa biblioteken för användning av maskininlärnings- och datavetenskapsexperter.
Dess syntax är enkel, vilket gör det effektivt att implementera komplexa maskininlärningsalgoritmer. Dessutom förkortar den enkla syntaxen inlärningskurvan och gör förståelsen lättare.
Python stöder även snabb prototyputveckling och smidig testning av applikationer.
Pythons stora community är praktiskt för datavetare att lätt söka lösningar på sina frågor när det behövs.
Hur användbara är Python-bibliotek?
Python-bibliotek är avgörande för att skapa applikationer och modeller inom maskininlärning och datavetenskap.
Dessa bibliotek går långt för att hjälpa utvecklaren med kodåteranvändbarhet. Därför kan du importera ett relevant bibliotek som implementerar en specifik funktion i ditt program förutom att återuppfinna hjulet.
Python-bibliotek som används inom maskininlärning och datavetenskap
Data Science-experter rekommenderar olika Python-bibliotek som datavetenskapsentusiaster måste vara bekanta med. Beroende på deras relevans i applikationen använder maskininlärnings- och datavetenskapsexperterna olika Python-bibliotek kategoriserade i bibliotek för att distribuera modeller, bryta och skrapa data, databearbetning och datavisualisering.
Den här artikeln identifierar några vanliga Python-bibliotek inom datavetenskap och maskininlärning.
Låt oss titta på dem nu.
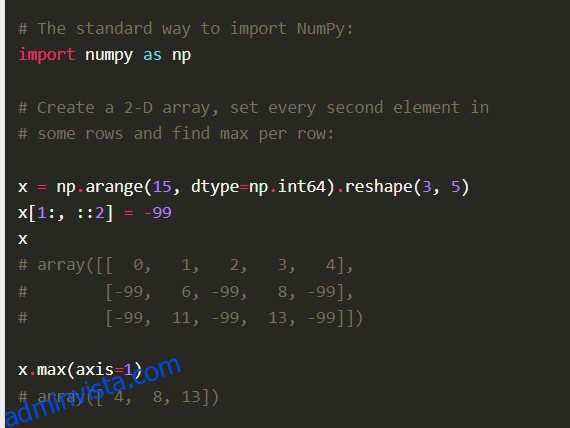
Numpy
Numpy Python-biblioteket, även Numerical Python Code i sin helhet, är byggt med väl optimerad C-kod. Dataforskare föredrar det för dess djupgående matematiska beräkningar och vetenskapliga beräkningar.
Funktioner
Numpy kommer med andra omfattande funktioner som vektorisering av matematiska operationer, indexering och nyckelbegrepp för implementering av matriser och matriser.
Pandas
Pandas är ett berömt bibliotek inom maskininlärning som tillhandahåller datastrukturer på hög nivå och många verktyg för att analysera massiva datamängder enkelt och effektivt. Med väldigt få kommandon kan det här biblioteket översätta komplexa operationer med data.
Många inbyggda metoder som kan gruppera, indexera, hämta, dela, omstrukturera data och filtrera uppsättningar innan de infogas i enkla och flerdimensionella tabeller; utgör detta bibliotek.
Pandas biblioteks huvudfunktioner
Den är mycket effektiv för sin goda dataanalysfunktionalitet och höga flexibilitet.
Matplotlib
Matplotlib 2D grafiska Python-bibliotek kan enkelt hantera data från många källor. Visualiseringarna som skapas är statiska, animerade och interaktiva som användaren kan zooma in på, vilket gör det effektivt för visualiseringar och skapa diagram. Det tillåter också anpassning av layout och visuell stil.
Dess dokumentation är öppen källkod och erbjuder en omfattande samling verktyg som krävs för implementering.
Matplotlib importerar hjälpklasser för att implementera år, månad, dag och vecka, vilket gör det effektivt att manipulera tidsseriedata.
Scikit-lär dig
Om du funderar på ett bibliotek som hjälper dig att arbeta med komplexa data bör Scikit-learn vara ditt idealiska bibliotek. Maskininlärningsexperter använder Scikit-learn i stor utsträckning. Biblioteket är associerat med andra bibliotek som NumPy, SciPy och matplotlib. Den erbjuder både övervakade och oövervakade inlärningsalgoritmer som kan användas för produktionsapplikationer.

Funktioner i Scikit-lär Python-biblioteket
Scikit-learn-biblioteket är effektivt för att extrahera funktioner från text- och bilddatauppsättningar. Dessutom är det möjligt att kontrollera noggrannheten hos övervakade modeller på osynliga data. Dess många tillgängliga algoritmer möjliggör datautvinning och andra maskininlärningsuppgifter.
SciPy
SciPy (Scientific Python Code) är ett maskininlärningsbibliotek som tillhandahåller moduler som tillämpas på matematiska funktioner och algoritmer som är allmänt tillämpliga. Dess algoritmer löser algebraiska ekvationer, interpolation, optimering, statistik och integration.
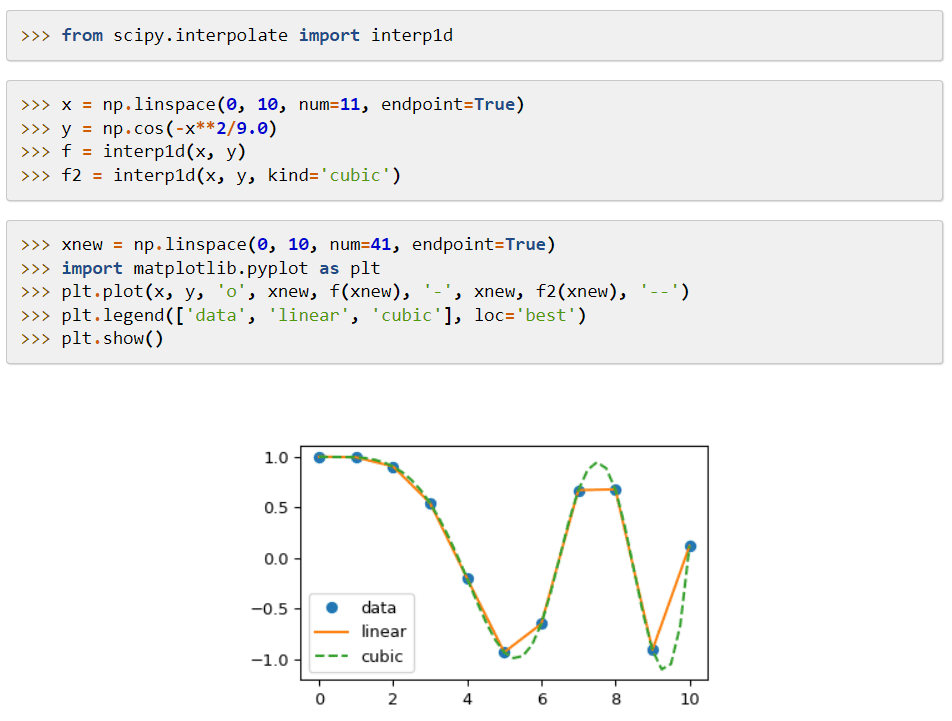
Dess huvudsakliga funktion är dess förlängning till NumPy, som lägger till verktyg för att lösa de matematiska funktionerna och tillhandahåller datastrukturer som glesa matriser.
SciPy använder kommandon och klasser på hög nivå för att manipulera och visualisera data. Dess databehandling och prototypsystem gör det till ett ännu effektivare verktyg.
Dessutom gör SciPys syntax på hög nivå det enkelt för programmerare på alla erfarenhetsnivåer att använda.
SciPys enda nackdel är dess enda fokus på numeriska objekt och algoritmer; kan därför inte erbjuda någon plottningsfunktion.
PyTorch
Detta mångsidiga maskininlärningsbibliotek implementerar effektivt tensorberäkningar med GPU-acceleration, vilket skapar dynamiska beräkningsgrafer och automatiska gradientberäkningar. Torch-biblioteket, ett maskininlärningsbibliotek med öppen källkod utvecklat på C, bygger PyTorch-biblioteket.

Nyckelfunktioner inkluderar:
Du kan använda PyTorch för att utveckla NLP-applikationer.
Keras
Keras är ett Python-bibliotek med öppen källkod för maskininlärning som används för att experimentera med djupa neurala nätverk.
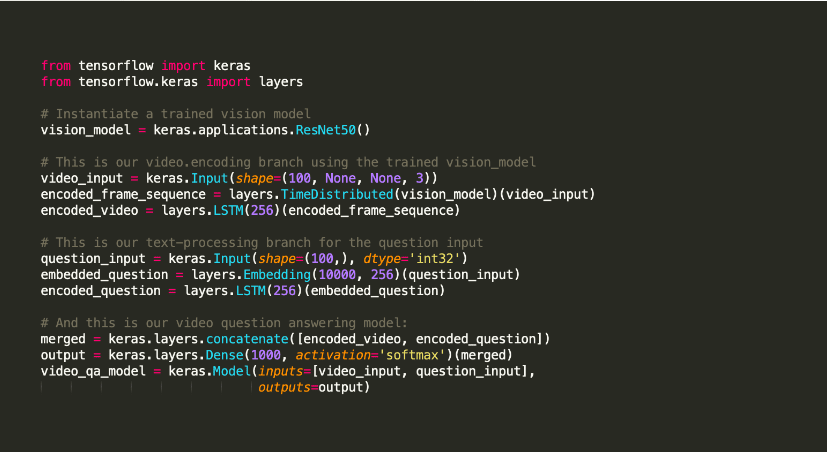
Det är känt för att erbjuda verktyg som bland annat stöder uppgifter som modellkompilering och grafvisualiseringar. Den tillämpar Tensorflow för sin backend. Alternativt kan du använda Theano eller neurala nätverk som CNTK i backend. Denna backend-infrastruktur hjälper den att skapa beräkningsgrafer som används för att implementera operationer.
Huvudfunktioner i biblioteket
Tillämpningar av Keras inkluderar byggstenar för neurala nätverk som lager och mål, bland andra verktyg som underlättar arbete med bilder och textdata.
Seaborn
Seaborn är ett annat värdefullt verktyg för statistisk datavisualisering.
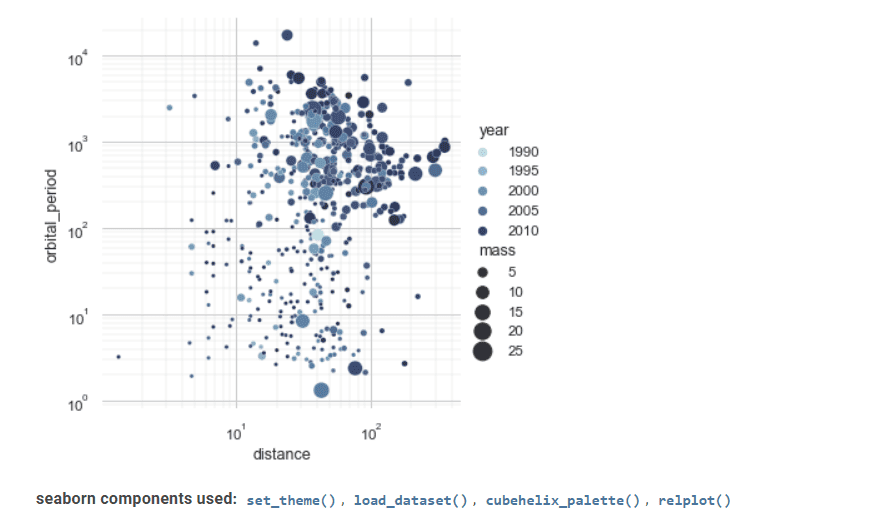
Dess avancerade gränssnitt kan implementera attraktiva och informativa statistiska grafikritningar.
Handling
Plotly är ett 3D-webbaserat visualiseringsverktyg byggt på Plotly JS-biblioteket. Den har ett brett stöd för olika diagramtyper som linjediagram, spridningsdiagram och rutatyper.
Dess applikation inkluderar att skapa webbaserade datavisualiseringar i Jupyter-anteckningsböcker.
Plotly är lämplig för visualisering eftersom den kan peka ut extremvärden eller avvikelser i grafen med sitt hovringsverktyg. Du kan också anpassa graferna så att de passar dina önskemål.
På Plotlys nackdel är dess dokumentation föråldrad; därför kan det vara svårt för användaren att använda den som en guide. Dessutom har den många verktyg som användaren bör lära sig. Det kan vara svårt att hålla reda på dem alla.
Funktioner i Plotly Python-biblioteket
SimpleITK
SimpleITK är ett bildanalysbibliotek som erbjuder ett gränssnitt till Insight Toolkit (ITK). Den är baserad på C++ och är öppen källkod.
Funktioner i SimpleITK-biblioteket
Dess förenklade gränssnitt är tillgängligt i olika programmeringsspråk som R, C#, C++, Java och Python.
Statsmodell
Statsmodel uppskattar statistiska modeller, implementerar statistiska tester och utforskar statistiska data med hjälp av klasser och funktioner.
Ange modeller använder R-formler, NumPy-matriser och Pandas-dataramar.
Skramligt
Detta paket med öppen källkod är ett föredraget verktyg för att hämta (skrapa) och genomsöka data från en webbplats. Den är asynkron och därför relativt snabb. Scrapy har arkitektur och funktioner som gör den effektiv.
På nackdelen är installationen olika för olika operativsystem. Dessutom kan du inte använda den på webbplatser byggda på JS. Dessutom kan det bara fungera med Python 2.7 eller senare versioner.
Data Science-experter tillämpar det i datautvinning och automatiserad testning.
Funktioner
Kudde
Pillow är ett Python-bildbibliotek som manipulerar och bearbetar bilder.
Den lägger till Python-tolkens bildbehandlingsfunktioner, stöder olika filformat och erbjuder en utmärkt intern representation.
Data som lagras i grundläggande filformat kan lätt nås tack vare Pillow.
Avslutning💃
Det sammanfattar vår utforskning av några av de bästa Python-biblioteken för datavetare och maskininlärningsexperter.
Som den här artikeln visar har Python mer användbara maskininlärnings- och datavetenskapspaket. Python har andra bibliotek som du kan använda inom andra områden.
Du kanske vill veta om några av de bästa anteckningsböckerna för datavetenskap.
Lycka till med lärandet!