Digitaliseringen av ett företag når sin fulla potential först när alla separata affärsdataflöden förenas i en sammanhängande dataväv. Denna väv hjälper till att följa gällande policyer för riskhantering, styrning och integritet, samtidigt som databearbetningen förblir effektiv.
I många organisationer arbetar olika team och avdelningar separat med att samla in och hantera data. Detta skapar en fragmenterad bild och gör det svårt att slå samman olika datakällor, oavsett om det är offentliga eller privata data, på grund av begränsningar i datastyrning och integritet.
Så, vad är lösningen för en verkligt centraliserad och digitaliserad databearbetning? Svaret ligger i en välstrukturerad dataväv. Läs vidare för att förstå denna struktur i detalj. Denna kunskap kommer att vara avgörande när du ska välja rätt verktyg för en dataväv.
Vad är en dataväv?
Konceptet med datavävar eller datanätverk identifierades som en av de tio viktigaste teknologitrenderna redan 2019, enligt en rapport från Gartner. Experter inom analys och datateknik anser att det är det framtidssäkra verktyget för datahantering, lämpligt för både startups och etablerade företag av alla storlekar.
En dataväv kan betraktas som en IT-miljö med en enhetlig arkitektur som kopplar samman olika datakällor med diverse affärsapplikationer. I bakgrunden arbetar en kraftfull artificiell intelligens (AI) som analyserar data på ett säkert sätt och presenterar endast relevant information för den specifika användaren, vare sig det är en säljare, kundsupportmedarbetare eller affärschef.
Ur ett helikopterperspektiv kan dataväven liknas vid en virtuell väv där olika system för datalagring och beräkning samverkar och delar information på ett effektivt sätt.
Syftet med en dataväv
De hinder som skapas av olika affärsapplikationer, tidsaspekter, fysiska avstånd, datalagringsmetoder, datahämtningsprocesser och datasäkerhetsprotokoll utgör betydande flaskhalsar som bromsar utvecklingen för företag. Samtidigt är dessa kontroller nödvändiga för att skydda känslig information. Därför kan man varken helt avskaffa dem eller behålla dem i sin nuvarande form.
Det är här dataväven kommer in i bilden. Den fungerar som en ”motorväg” som underlättar dataflödet från olika platser, affärsapplikationer, lokalkontor, butiker, servrar och andra källor. Denna data kan vara av strukturerad, semistrukturerad eller rå karaktär, och varje datakälla kan ha sina egna säkerhetsrutiner.
Slutanvändarna, som kunder, säljare, supportchefer och ledningsgrupper, behöver inte förstå alla detaljer kring detta. De behöver bara säker och smidig tillgång till data för att kunna utföra sina arbetsuppgifter. Dataväven uppnår detta genom automation, artificiell intelligens och maskininlärning.
Andra viktiga syften med dataväven är:
- Att ansluta alla affärsdatakällor genom containrar och kopplingar.
- Att erbjuda dataintegrations- och inmatningsfunktioner i lagringsutrymmen, applikationer osv.
- Att fungera som en höghastighetsinfrastruktur för analys av stora datamängder.
- Att koppla samman datakonsumenter och datakällor i ett nätverk.
- Att möjliggöra hybrid datahantering mellan privata moln, publika moln, multi-moln, lokala system och fysiska arbetsstationer.

Företag ägnar ofta mer tid åt att diskutera och godkänna data, snarare än att faktiskt bearbeta dem. Anställda kan fastna i långa e-posttrådar innan de får tillstånd att använda datan.
Detta är ett allvarligt hot mot produktiviteten i framtidsorienterade företag. Men dataväven kan rädda företag genom att:
- Erbjuda en enhetlig plattform för att komma åt, mata in, lagra och analysera alla typer av data.
- Säkerställa att datastyrning och regler efterlevs, även om alla inom företaget har tillgång till data upp till en viss nivå.
- Göra data mer tillförlitlig och lättanvänd genom att låta AI bearbeta informationen innan den når användarna.
- Aktivera maskin-till-maskin kommunikation (Internet of Things, IoT) för att minska mänsklig inblandning i känslig data.
- Möjliggöra enkel anpassning till ökningar och minskningar av applikationer, kundförfrågningar, intern dataåtkomst, hantering av stora marknadsföringsdata osv.
- Minska beroendet av gammal infrastruktur och därmed sänka kostnaderna.
- Maximera utnyttjandet av molnteknik genom att samla alla digitala datakällor på en plats, skyddad av avancerade AI-algoritmer.
I slutändan kommer medarbetare i kundtjänst eller säljavdelningen att få tillgång till sina CRM-data snabbare, vilket i sin tur leder till ökat kundförtroende och nöjdhet.
Fördelar med en dataväv

Stärker agila DevOps-modeller
Agila projekt för mjukvaru- eller produktutveckling kan drabbas hårt av störningar i databearbetningen. Med ett datavävsverktyg kan man praktiskt taget eliminera dessa avbrott.
Efterlevnad av datastyrning
Den integrerade AI och maskininlärningen hjälper till att upprätthålla policyer för dataskydd och styrning. Samtidigt kommer samma AI att bearbeta den begärda datan och presentera den för en anställd i enlighet med företagets riktlinjer.
Skalbarhet
Leverantörer av hanterade tjänster (MSP) kan snabbt skala upp eller ner företagets databearbetningsbehov.
Hantering av metadata
En datakatalog kommer att lagra alla datakällor, tillgångar och metadata. Genom att studera metadata kan AI snabbare hämta den information som efterfrågas.
Feldetektering
AI kan identifiera datakorruption, integritetsproblem och fel innan företaget drabbas av ekonomiska förluster.
Rollbaserad åtkomst
Anställda kan begära bearbetad information baserat på sina individuella säkerhetsbehörigheter.
Eliminering av datasilos
Datasilos utgör inte längre ett hot mot verksamheten när dataväven samlar all data på en krypterad ”datamotorväg”. Team kan säkert få tillgång till legitim data från vilken avdelning som helst utan att gå igenom onödiga byråkratiska hinder.
Dataintegration
Dataväven och dess integrerade AI möjliggör omedelbar dataintegration med realtidssystem som CRM, ERP, kundapplikationer, medarbetarapplikationer, etc.
Högkvalitativ data
Intelligenta algoritmer inom dataväven analyserar kontinuerligt alla datakällor. Därför kan de anställda lita på den data de får utan att behöva göra egna valideringar.
Arkitekturen för en dataväv
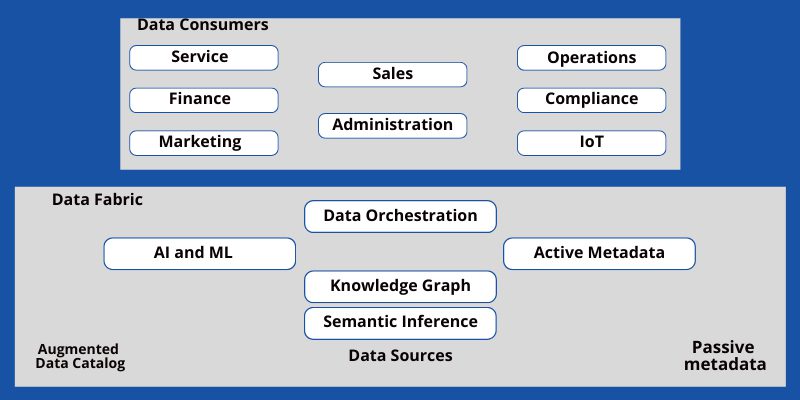
Dataväven måste säkerställa ökad datatillgänglighet utan att kompromissa med kvalitet och säkerhet. En standardarkitektur för en dataväv bör därför innehålla följande komponenter:
Datakatalog
En datakatalog är ett strukturerat register över all affärsdata. Användare kan använda dessa kataloger för att hitta den information som behövs för att utföra sina uppgifter. Datakatalogen består av underkomponenterna: metadata och kunskapsgrafer.
AI- och ML-baserad automation
Flera AI-system bör finnas i kärnan av dataväven för att hantera alla frågor, datakvalitetskontroller, säkerhetskontroller etc.
Dataintegration och transport
Dataväven integrerar data från alla källor, inklusive lokala servrar, molnlagring, anställdas datorer etc. Det bör finnas anslutningar för att länka informationen till en fjärrdator eller transportörer som flyttar datan genom dataväven.
Hur implementerar man en dataväv?

Implementeringen av en dataväv beror helt på vilken typ av organisation det rör sig om och dess specifika behov. Det finns ingen standardlösning som passar alla företag. Men det finns några vanliga funktioner eller lager som ingår i datavävens arkitektur.
Datahantering: Detta lager ansvarar för datasäkerhet och styrning.
Datainmatning: Här börjar sammanfogningen av all molndata, samtidigt som man kartlägger hur strukturerad och ostrukturerad data hänger ihop.
Databearbetning: Säkerställer att relevant data är tillgänglig under datauttag.
Dataarrangering: Detta lager inkluderar utförande av uppgifter som data insamling, strukturering, rensning, integration och transformation för att skapa användbar data.
Dataupptäckt: Gör det möjligt att samla in data genom att integrera olika källor. Detta är avgörande för kundnöjdheten.
Dataåtkomst: Detta lager hanterar datakonsumtion. Det hjälper till att få tillgång till relevant data via visualiseringsverktyg och applikationsinstrumentpaneler.
Principer för en dataväv

Syftet med dataväven är att förena distribuerade och olika datatillgångar för företag inom alla branscher. Det handlar också om att kombinera end-to-end processer för datahantering i en enhetlig plattform.
Dataväven uppnår detta genom att dra nytta av följande principer för datahantering:
- Dataupptäckt
- Datakurering
- Dataorganisation
- Datamodellering
- Kvalitetskontroller
- Dataorkestrering
- Dataintegration
- Datastyrning
Funktioner hos en dataväv

Kontinuerlig hantering av datafrågor
Dataväven förlitar sig på höghastighetsinternet, SSD-enheter och superdatorer för att kontinuerligt hämta data utan avbrott.
Kontinuerlig dataintegration, upptäckt och katalogisering
Den primära AI som ansvarar för datahanteringen måste arbeta kontinuerligt för att acceptera ny rådata, analysera, katalogisera och integrera den i affärsapplikationer.
Passiv och aktiv metadata
Aktiv metadata är information som datakvalitet, dataanvändning, aktuell redigerare osv. Passiv metadata är statisk information, t.ex. vem som skapade den. Datavävens AI ändrar kontinuerligt den här informationen för att minska behovet av manuell datahantering.
Flexibilitet
Dataväven är mycket flexibel och kan enkelt anpassas när företagets behov ändras.
Implementering av en dataväv kan göras smidigt med hjälp av smarta mjukvarulösningar. Det finns många alternativ, men här följer några lämpliga för små och medelstora företag:
Atlan

Atlan är en kraftfull och användarvänlig plattform för aktiv metadata och dataarbetsytor. Den gör det enkelt att få tillgång till data från alla källor. Den fungerar som en modern datakatalog för att möta behoven av datastrukturering. Plattformen erbjuder lösningar för katalogisering, profilering, upptäckt, kvalitetskontroll, styrning, utforskning och integration.
Den har ett gränssnitt som liknar Google Sök och en rik affärsordlista som hjälper användarna att förstå datan. Företag kan utnyttja funktioner som granulär styrning och åtkomstkontroller för att hantera hur data används i ett helt ekosystem.
Atlan stöder integration med applikationer som Big Query, Amazon Redshift, Snowflake, MYSQL, Looker och Tableau.
K2View

Om du letar efter en plattform med komplett datavävsfunktionalitet är K2View ett bra alternativ. Denna dataplattform hjälper dig med alla steg i dataväven, inklusive dataintegration, förberedelse, dataorkestrering och pipelining.
Med dess hjälp kan företag införa avancerade datavävsarkitekturer i molnet, lokalt eller i hybridmiljöer. Resultatet blir att manuell datahantering minskar i takt med att dataväven förenklar processerna. K2View kan förena data från flera källor och koppla dem till olika målsystem.
Med K2View kan du snabbt skapa datasjöar och datalager som du kan analysera direkt. Även om du inte har någon erfarenhet av kodning kan du styra datans rörelse och omvandling från källa till mål.
Företag kan använda plattformens konfigurerbara regler för att kontrollera dataåtkomst, synkronisering och säkerhet. Dessutom är K2View lämplig för automatisering av datatjänster med hjälp av ett lättanvänt ramverk.
Talend
Talend är en datavävsplattform som säkerställer tillförlitlig tillgång till data samtidigt som den hjälper företaget att öka sin affärsnytta. Alla företag behöver kunna hantera komplett och tillförlitlig data för att säkerställa användbarhet, integritet, tillgänglighet och säkerhet. Denna plattform hjälper företag att hålla sin data i bra skick genom att minska riskerna.
Talend är en enhetlig plattform för tillförlitlig data som erbjuder styrning, integration och dataskydd. Den levererar data med hög kvalitet med hjälp av serviceinfrastruktur och partnernätverk. Här kan du hitta relevant data genom dokumentation och kategorisering.
Eftersom Talend rensar data automatiskt i realtid finns det liten risk att dålig data smiter in i systemet. Företag kan förbättra sin produktivitet och spara pengar genom att använda detta verktyg, som garanterar efterlevnad av regler och minskar riskerna.
Du kan erbjuda dina kunder bättre upplevelser med hjälp av Talends applikations- och API-integration. Dessa säkerställer även självbetjäningsmöjligheter för att dela tillförlitlig data internt och externt.
Incorta

Incorta är en självbetjäningsplattform för dataanalys där företag kan utnyttja sin data fullt ut och få insikter till en lägre kostnad. Lösningen ger en smidig datahantering så att du kan fatta snabba och välgrundade beslut.
Den använder in-memory-analys och direkt datamappning för att ge oöverträffad hastighet och skalbarhet för datalagring och hantering. Incorta säkerställer flexibel datapipelining, även om du vill analysera data från många källor.
Dessutom hjälper den dig med datainsamling, bearbetning, analys och presentation av data från affärsapplikationer. Du kan också presentera komplett affärsdata med hjälp av dess inbyggda visualiseringsfunktioner.
Slutsats
Dataväven är nästa generations arkitektur för datalagring, bearbetning och hantering. Trots att det är en framtidsorienterad IT-lösning använder många digitala företag redan datavävsverktyg för att förbereda sin personal för framtiden.
Små, medelstora och nystartade företag kan dra nytta av denna teknik eftersom de inte har råd med fördröjningar i arbetsflödet på grund av godkännanden och granskningar. Besök webbplatserna för de verktyg som nämnts ovan för att se hur de kan tillföra mervärde till ditt företag.
Din RevOps affärsmodell kan i hög grad gynnas av en dataväv. Läs mer om verktyg för intäktsoptimering (RevOps) här.