Reddit tillhandahåller JSON-flöden för varje enskild subreddit. Den här guiden visar hur du skapar ett Bash-skript som hämtar och analyserar inlägg från valfri subreddit. Detta är bara ett exempel på vad man kan göra med Reddits JSON-data.
Installation av Curl och JQ
Vi använder curl för att ladda ner JSON-flödet från Reddit och jq för att bearbeta och extrahera specifik information. Du kan installera dessa verktyg med apt-get på Ubuntu och andra Debian-baserade system. På andra Linux-distributioner, använd din pakethanterare.
sudo apt-get install curl jq
Hämtning av JSON-data från Reddit
Låt oss undersöka hur dataflödet ser ut. Vi använder curl för att hämta de senaste inläggen från subredditen MildlyInteresting:
curl -s -A "användare-exempel" https://www.reddit.com/r/MildlyInteresting.json
Observera parametrarna före webbadressen: -s gör att curl körs tyst och endast visar data från Reddit. -A "användare-exempel" definierar en unik användaragent, vilket hjälper Reddit att identifiera vår förfrågan. Reddit API använder begränsningar baserade på användaragenten. Genom att använda en egen sträng minskar vi risken för att få ett HTTP 429-fel.
Utdata fyller terminalfönstret och ser ut ungefär så här:
Data innehåller många fält, men vi är främst intresserade av titeln, permalänken och URL:en. En fullständig lista över datatyper och fält finns på Reddits API-dokumentationssida: https://github.com/reddit-archive/reddit/wiki/JSON
Extrahering av Data från JSON
Vi vill få tag på titel, permalänk och URL och spara dem i en tabbseparerad fil. Istället för att använda textverktyg som sed och grep, använder vi jq, ett verktyg för JSON-data. Vi börjar med att snyggt formatera och färglägga resultatet. Använd samma anrop men skicka resultatet genom jq för analys och utskrift:
curl -s -A "användare-exempel" https://www.reddit.com/r/MildlyInteresting.json | jq .
Punkten . i kommandot instruerar jq att bearbeta och skriva ut indatan som den är. Resultatet blir snyggt formaterat och färgkodat:
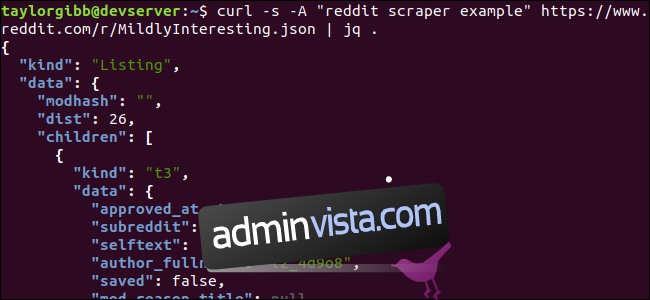
JSON-data vi får tillbaka från Reddit består av ett rotobjekt med två fält: typ och data. Fältet data innehåller ett fält som heter children, som i sin tur är en array av inlägg för denna subreddit. Varje objekt i arrayen är ett objekt med fälten typ och data. Den information vi söker finns i varje data-objekt. Jq förväntar sig ett uttryck som filtrerar och omvandlar indatan till önskad utdata. Låt oss köra hela kommandot med rätt uttryck:
curl -s -A "användare-exempel" https://www.reddit.com/r/MildlyInteresting.json | jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
Resultatet visar titeln, URL:en och permalänken var och en på en egen rad:
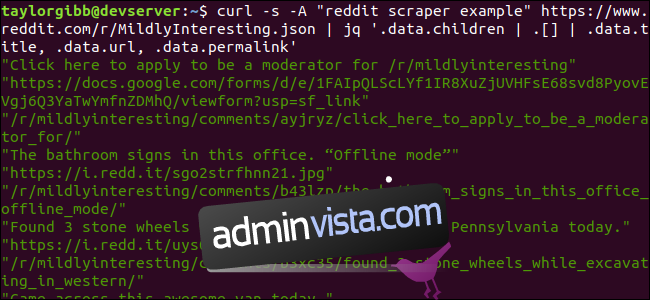
Låt oss analysera jq-kommandot:
jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
Kommandot består av tre uttryck, separerade av pipes. Varje uttrycks resultat skickas till nästa steg för vidare bearbetning. Det första uttrycket filtrerar ut allt utom arrayen med inlägg. Denna array bearbetas i det andra uttrycket. Det tredje uttrycket extraherar de tre fälten från varje objekt i arrayen. Mer information om jq och dess syntax hittar du i jq:s officiella manual.
Sätta ihop allt i ett skript
Vi samlar nu ihop API-anropet och JSON-bearbetningen i ett skript som skapar en fil med inlägg vi är intresserade av. Vi gör det flexibelt så att det fungerar med vilken subreddit som helst, inte bara /r/MildlyInteresting.
Skapa en fil som heter `scrape-reddit.sh` och kopiera följande innehåll:
#!/bin/bash
if [ -z "$1" ]
then
echo "Ange en subreddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete '"' >> ${OUTPUT_FILE}
done
Skriptet börjar med att kontrollera om användaren har angett ett subreddit-namn. Om inte, avslutas skriptet med ett felmeddelande och returkod. Därefter lagras det första argumentet som subreddit-namnet, och ett filnamn skapas med en tidsstämpel. Kärnan i skriptet är curl-anropet som hämtar JSON-data från den angivna subredditen. Data skickas till jq där den reduceras till tre fält: Titel, URL och Permalänk. Dessa rader läses in i en while-loop med hjälp av `read`-kommandot. Inne i loopen ekas de tre fälten, separerade med tabbtecken, citattecken tas bort med tr-kommandot och resultatet läggs till i filen.
Innan vi kan köra skriptet, måste vi bevilja det exekveringsrättigheter med `chmod`:
chmod u+x scrape-reddit.sh
Kör sedan skriptet med ett subreddit-namn:
./scrape-reddit.sh MildlyInteresting
En utdatafil skapas i samma mapp. Innehållet kommer se ut ungefär så här:
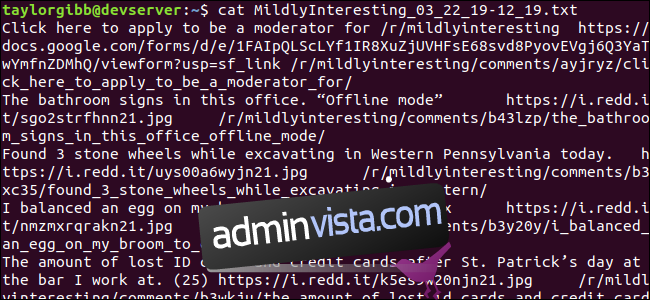
Varje rad innehåller de tre önskade fälten, separerade med tabbtecken.
Vidareutveckling
Reddit är en källa till intressant innehåll och media, som är tillgängligt via JSON API. Nu när du kan hämta och bearbeta denna data, kan du:
- Hämta de senaste nyheterna från /r/WorldNews och skicka dem till ditt skrivbord med notify-send
- Integrera de bästa skämten från /r/DadJokes i systemets Message-Of-The-Day
- Hämta dagens sötaste bild från /r/aww och använd den som skrivbordsbakgrund
Allt detta är möjligt med de tillgängliga verktygen och din kreativitet. Lycka till med hackandet!