Webbskrapning: En Djupdykning
Webbskrapning, en process för automatiserad datainsamling från webbsidor, är ett kraftfullt verktyg för att snabbt samla in stora mängder data. Det är särskilt användbart när webbplatser inte tillhandahåller strukturerad data via API:er (Application Programming Interfaces).
Tänk dig att du utvecklar en applikation för att jämföra priser på olika e-handelssajter. En manuell kontroll av priser på alla webbplatser skulle vara tidskrävande och ineffektiv, med tanke på det stora antalet produkter som finns online.
Webbskrapning är ett mer praktiskt alternativ. Det är en process där programvara används för att automatiskt extrahera data från webbsidor och webbplatser. Dessa skript, ofta kallade ”webbskrapor”, hämtar information från webbplatser. Den hämtade datan, som ofta är ostrukturerad, kan sedan analyseras och struktureras för användning.
Fördelarna med webbskrapning är många: det ger tillgång till stora mängder data, automatiserar datainsamlingsprocessen (vilket möjliggör schemaläggning eller triggning av skrapning), erbjuder uppdateringar i realtid och förenklar marknadsundersökningar.
Webbskrapning används flitigt av företag inom olika branscher, inklusive HR, e-handel, finans, fastigheter, resor, sociala medier och forskning. Till och med sökmotorer som Google använder webbskrapning för att indexera webbplatser och leverera relevanta sökresultat.
Det är dock viktigt att vara medveten om potentiella begränsningar och risker. Även om webbskrapning av offentlig data i sig inte är olagligt, kan vissa webbplatser ha regler som förbjuder det, till exempel på grund av känslig användarinformation, användarvillkor eller skydd av immateriella rättigheter. Dessutom kan intensiv skrapning överbelasta servrar och öka bandbreddskostnader.
För att kontrollera om en webbplats tillåter webbskrapning kan man undersöka dess robots.txt-fil genom att lägga till /robots.txt till webbadressen (till exempel google.com/robots.txt). Denna fil ger information om vilka delar av webbplatsen som får skrapas.
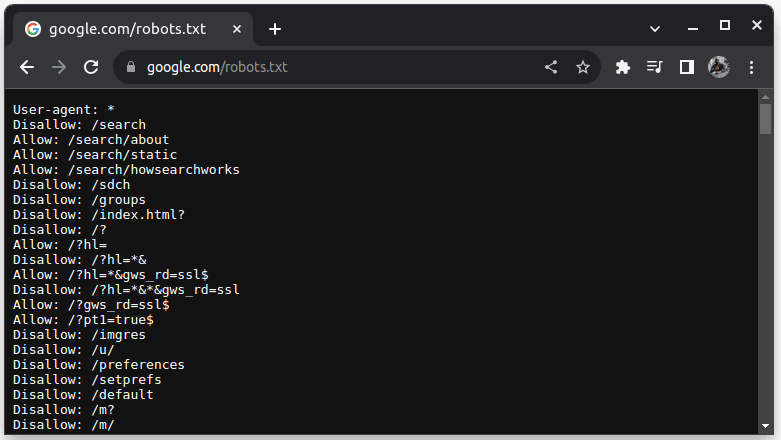
I robots.txt indikerar User-agent: * att instruktionerna gäller alla bots eller skript. Disallow specificerar vilka kataloger som inte får skrapas, medan Allow specificerar tillåtna kataloger. Webbplatser som LinkedIn tillåter till exempel inte skrapning utan uttryckligt tillstånd.
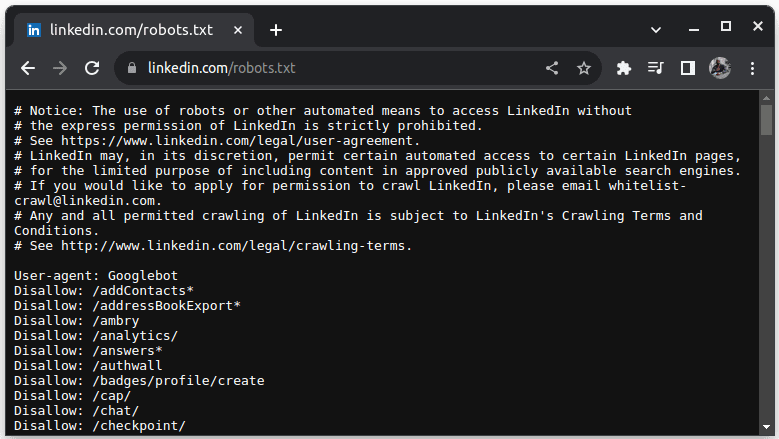
Det är alltid klokt att kontrollera robots.txt för att undvika potentiella juridiska problem.
Varför Java är ett lämpligt val för webbskrapning
Även om flera programmeringsspråk kan användas för webbskrapning, är Java ett särskilt bra val tack vare dess robusta ekosystem, stora community och tillgång till många specialiserade bibliotek, såsom JSoup, WebMagic och HTMLUnit. Dessa bibliotek underlättar utvecklingen av webbskrapor.

Java erbjuder dessutom bibliotek för att parsa HTML-dokument och göra nätverksanrop via HttpURLConnection, vilket förenklar processen för att hämta och analysera webbsidor. Dessutom är Javas stöd för samtidighet och multithreading fördelaktigt för hantering av flera förfrågningar parallellt, vilket möjliggör skrapning av flera sidor samtidigt. Javas skalbarhet gör det möjligt att effektivt skrapa webbplatser även i stor skala.
Plattformsoberoendet hos Java ger en flexibilitet där webbskrapor kan skrivas och köras på olika system med kompatibla Java Virtual Machines, utan att behöva modifieras. Dessutom kan Java integreras med huvudlösa webbläsare som Headless Chrome och HTML Unit, vilket är användbart vid skrapning av webbplatser som kräver användarinteraktion.
Slutligen är Java ett populärt språk med omfattande stöd och integreringsmöjligheter med olika verktyg, databaser och ramverk. Detta säkerställer kompatibilitet med de verktyg som behövs för dataskrapning, bearbetning och lagring.
Låt oss nu titta närmare på hur Java kan användas för webbskrapning i praktiken.
Förutsättningar för webbskrapning med Java
Innan du börjar skrapa med Java, se till att följande förutsättningar är uppfyllda:
- Java: Installera den senaste LTS-versionen av Java. Du kan hitta instruktioner för installation på officiella Java-webbplatsen.
- IDE: Använd en IDE (Integrated Development Environment). Denna guide använder IntelliJ IDEA, men du kan använda valfri IDE du är bekväm med.
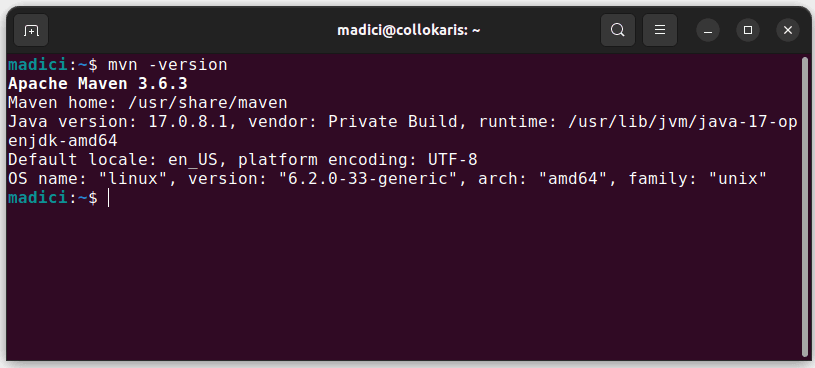
- Maven: Installera Maven för att hantera beroenden och webbskrapningsbibliotek. Om du inte har Maven installerat kan du göra det genom att öppna terminalen och köra:
sudo apt install maven. Verifiera sedan installationen medmvn -version.
Konfigurera miljön
Följ dessa steg för att ställa in din miljö:
- Öppna IntelliJ IDEA och välj ”New Project”.
- I ”New Project”-fönstret, ställ in ”Language” till ”Java” och ”Build System” till ”Maven”. Ange projektnamn och plats, och klicka sedan på ”Create”.
- Efter att projektet skapats, leta upp filen
pom.xml.
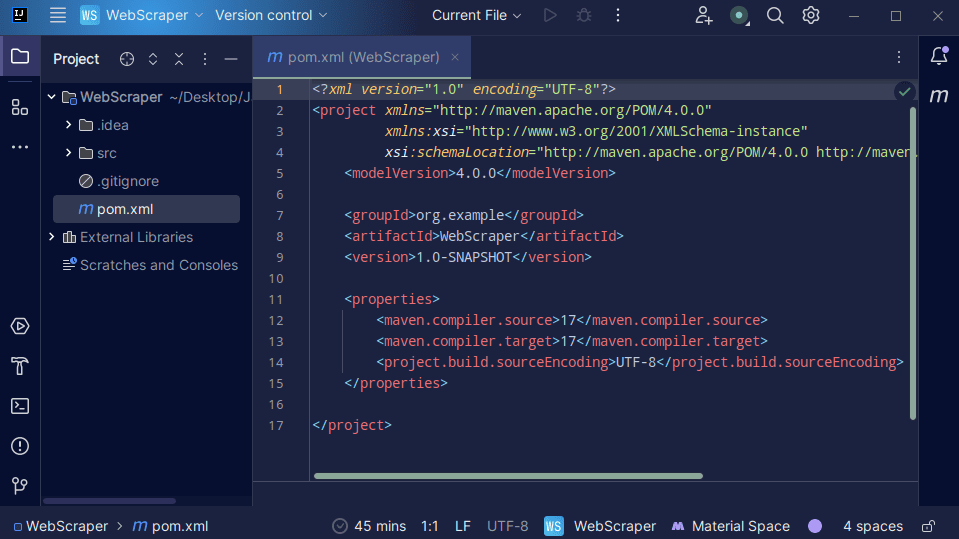
Filen pom.xml innehåller projektinformation och konfigurationsdetaljer. Vi kommer att använda den för att lägga till externa bibliotek. För detta exempel, behöver vi inkludera jsoup-biblioteket.
- Lägg till jsoup-beroendet i
pom.xmlgenom att kopiera och klistra in följande kod:
<dependencies> <!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.16.1</version> </dependency> </dependencies>
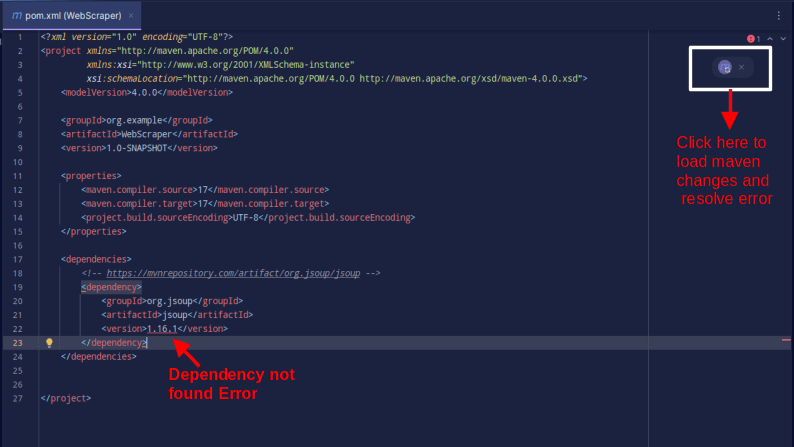
Om felmeddelanden uppstår, klicka på Maven-ikonen för att ladda om beroendena. Nu är din miljö redo!
Webbskrapning med Java: Ett exempel
Vi kommer att använda ScrapeThisSite, en webbplats som är utformad för att öva på webbskrapning, för detta exempel.
Följande steg beskriver hur du skrapar en webbplats med Java:
- I IntelliJ IDEA, navigera till
src->main->java. Högerklicka påjava-mappen, välj ”New” och sedan ”Java Class”. - Namnge klassen, till exempel ”WebScraper”, och tryck på Enter för att skapa klassen.
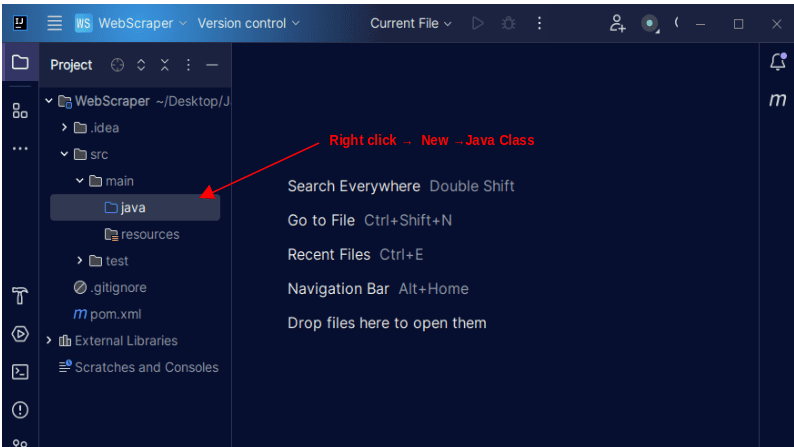
Nu är du redo att skriva Java-kod för att skrapa information.
- För att börja skrapa måste vi ange webbadressen vi ska hämta data från. Vi ansluter till webbadressen och skickar en GET-förfrågan för att hämta HTML-innehållet på sidan.
Koden ser ut så här:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
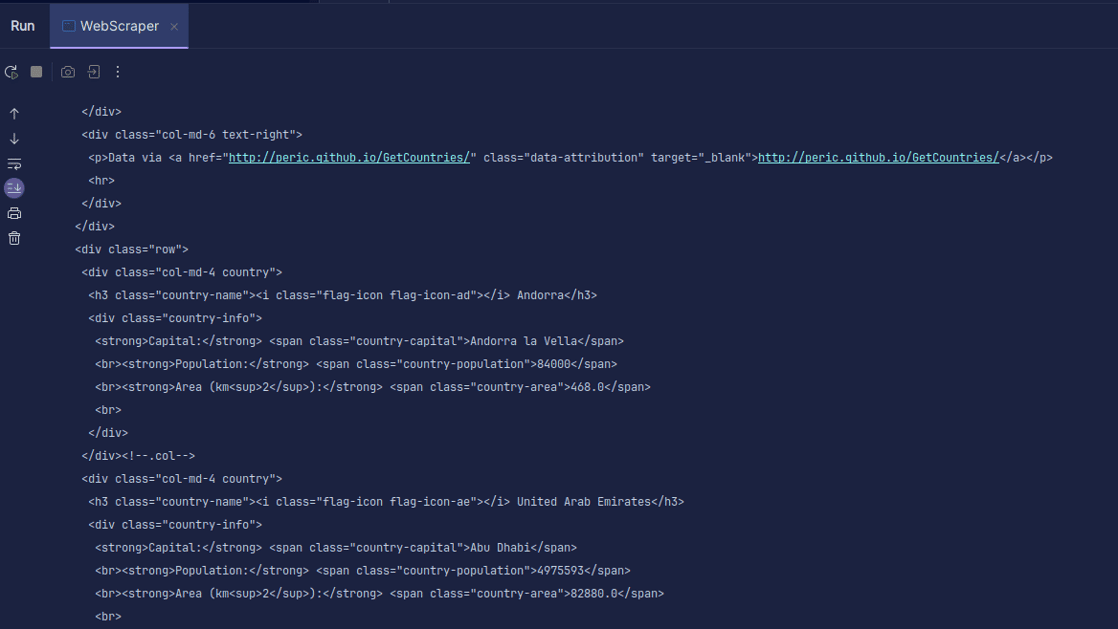
HTML-koden returneras och skrivs ut. Observera att vi har lagt in koden i en try-catch sats, eftersom det kan uppstå fel. Jsoup.connect(url).get() används för att ansluta till den angivna webbadressen och hämta HTML-koden. Den hämtade koden lagras sedan i ett JSOUP-dokument, vilket möjliggör manipulering av HTML-koden med JSOUP API.
- Inspektera webbsidan på ScrapeThisSite. Observera strukturen i HTML-koden.
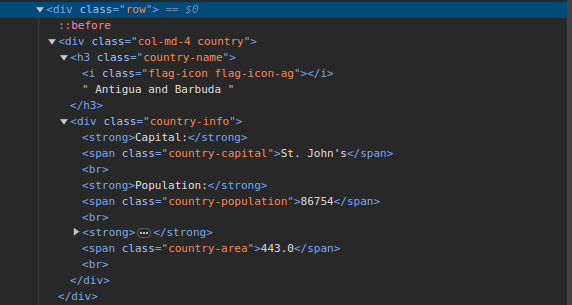
All landsinformation är strukturerad på samma sätt: ett div-element med klassen ”country” innehåller ett h3-element med klassen ”country-name” samt ett div-element med klassen ”country-info” som innehåller information om huvudstad, befolkning och yta. Vi kan utnyttja dessa klasser för att välja och extrahera data.
- Använd följande rader för att extrahera den specifika informationen:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
doc.select() används för att välja HTML-element med hjälp av CSS-selektorer. Först väljer vi alla div-element med klassen country och lagrar dem i en Elements-lista. Sedan går vi igenom varje land och extraherar landets namn, huvudstad och befolkning med CSS-selektorerna .country-name, .country-capital och .country-population. Till sist skriver vi ut den information vi hämtat.
Här är hela koden:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
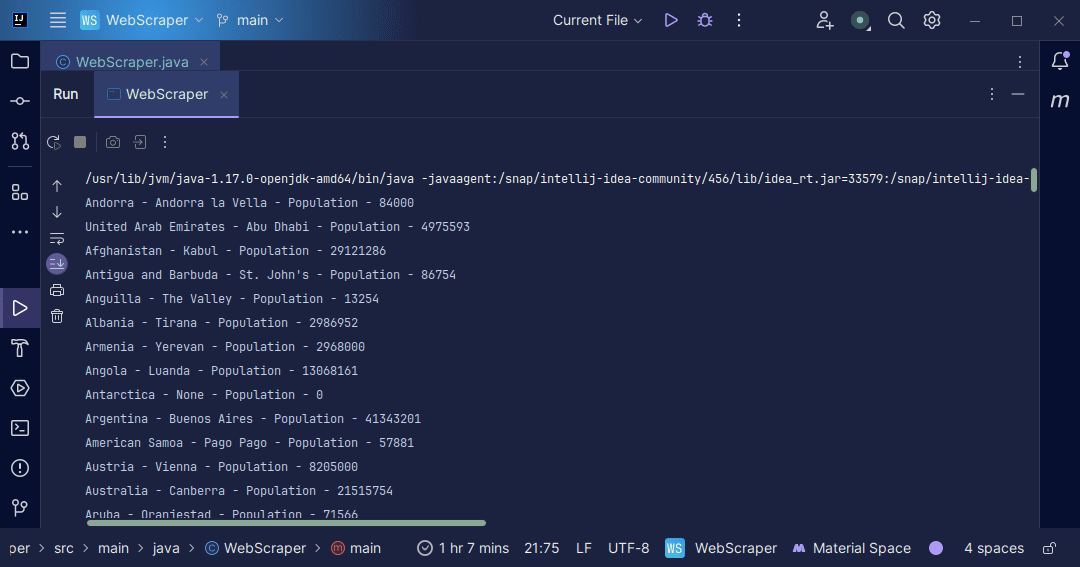
Den utvunna informationen kan nu användas för en mängd olika ändamål, till exempel lagring i en fil för vidare bearbetning.
Slutsats
Webbskrapning är en värdefull teknik för att samla in ostrukturerad data, strukturera den och använda den för att få insikter. Det är dock viktigt att vara försiktig och följa regler för webbplatsanvändning. Använd ”sandlådor” som ScrapeThisSite för att öva och undersök alltid robots.txt för de webbplatser du vill skrapa. Java är ett utmärkt språk för webbskrapning med sina bibliotek som förenklar processen. Utforska och bygg din egen skrapa, och anpassa den för att extrahera olika typer av information. Lycka till!
Du kan också utforska molnbaserade webbskrapningslösningar.