Databasskärning, en metod för att uppnå horisontell skalbarhet i omfattande system.
I praktiken består de flesta system av en databasserver som hanterar en stor mängd förfrågningar, både läs- och skrivoperationer. Detta kan leda till överbelastning och sänka systemets prestanda.
För att motverka dessa problem och förbättra prestandan finns det olika metoder, som databasreplikering och databasskärning. Denna artikel kommer inledningsvis att granska tekniker för att förbättra systemets prestanda, inklusive:
- Vertikal skalning av databasservern
- Databasreplikering
- Horisontell partitionering
Efter att ha gått igenom dessa metoder kommer vi att undersöka hur databasskärning fungerar, samt dess fördelar och begränsningar.
Låt oss börja!
Metoder för att förbättra systemprestanda
Låt oss inleda med att diskutera metoder för att förbättra systemprestandan när databasservern agerar som en flaskhals:
#1. Vertikal skalning av databasservern
Att uppgradera databasserverns kapacitet kan initialt verka som en enkel lösning för att förbättra systemprestandan. Detta kan innebära att öka processorkraften, lägga till mer RAM-minne och liknande.
Denna metod har dock sina begränsningar. Det är inte möjligt att ha en server med obegränsad lagring och processorkraft. Dessutom avtar effektiviteten efter en viss punkt.
#2. Databasreplikering
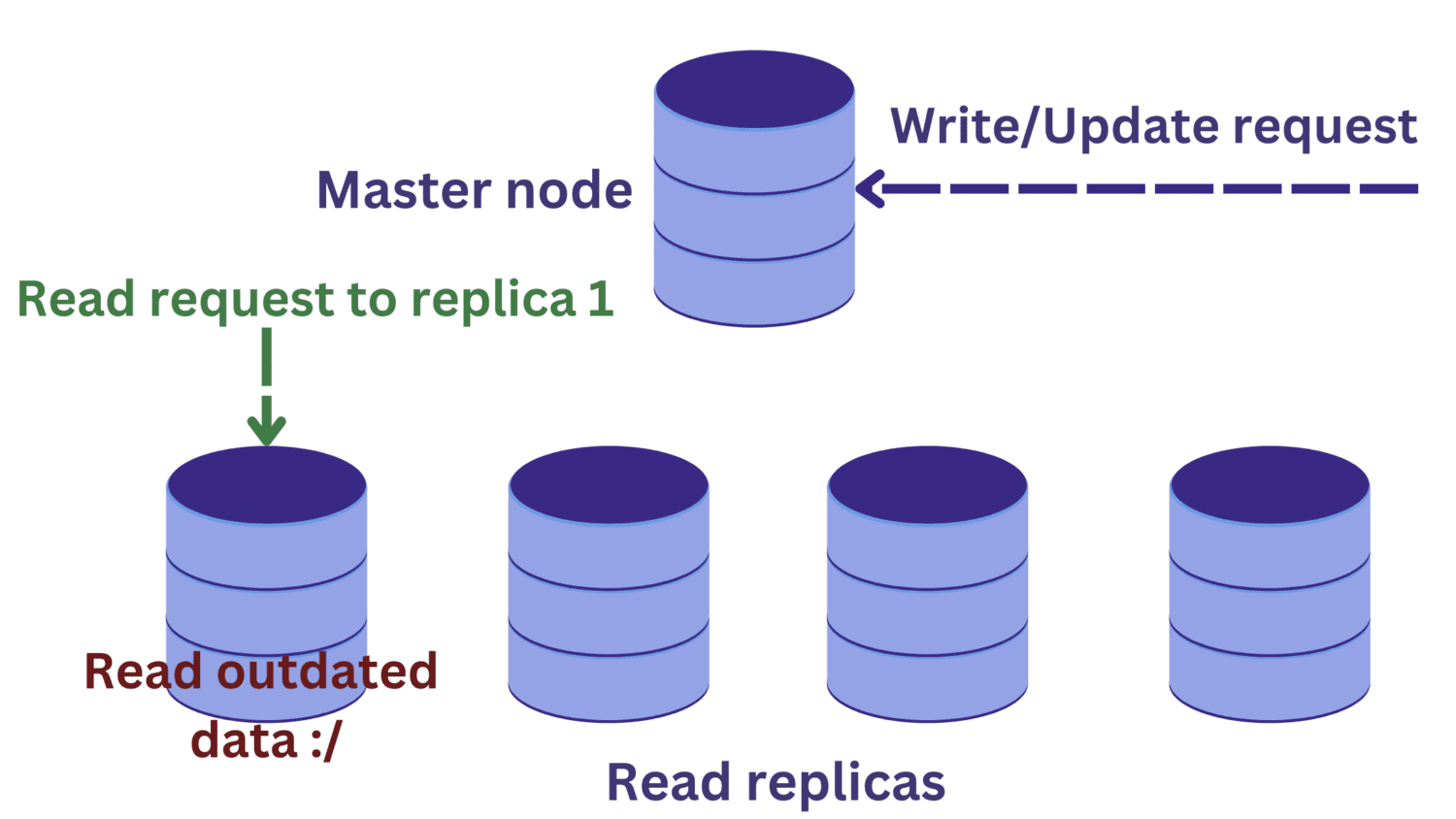
När databasservern överbelastas på grund av inkommande förfrågningar kan databasreplikering vara en relevant lösning.
Vid databasreplikering finns det en primär nod som oftast hanterar skrivförfrågningar och flera sekundära noder för läsoperationer.
Detta förbättrar tillgängligheten och reducerar belastningen på systemet. Flera förfrågningar kan behandlas samtidigt, eftersom läsförfrågningar kan omdirigeras till någon av läsreplikerna.
Detta introducerar dock ett nytt problem. Skrivförfrågningar till den primära noden ändrar data, och dessa ändringar måste sedan spridas till läsreplikerna.
Om en läsförfrågan skickas till en läsreplik samtidigt som en skrivoperation sker på den primära noden, kommer de nya ändringarna inte att ha replikerats än. Det kan leda till att inaktuell data läses, vilket är oönskat.
#3. Horisontell partitionering
Horisontell partitionering är en annan teknik för att optimera systemprestanda. Det kan finnas en enda stor databastabell med miljarder rader, exempelvis kund- och transaktionsdata.
Läsförfrågningar från en sådan stor tabell är långsammare. Men genom horisontell partitionering delas den stora tabellen upp i flera mindre partitioner (eller mindre tabeller) som kan läsas separat. Relationsdatabaser som PostgreSQL stöder partitionering.
Men alla partitioner finns fortfarande på en och samma databasserver. Skillnaden är att läsoperationerna sker från partitionerna i stället för den stora tabellen.
Därför kan servern ha svårt att hantera en ökning av antalet inkommande förfrågningar.
Hur fungerar databasskärning?
Efter att ha diskuterat metoder för att förbättra systemets prestanda och deras begränsningar, låt oss undersöka hur databasskärning fungerar.
Vid skärning delas den stora databasen upp i flera mindre databaser, var och en körs på en separat databasserver. Varje sådan mindre databas kallas för en ”shard”. Och varje shard innehåller en unik delmängd av data.
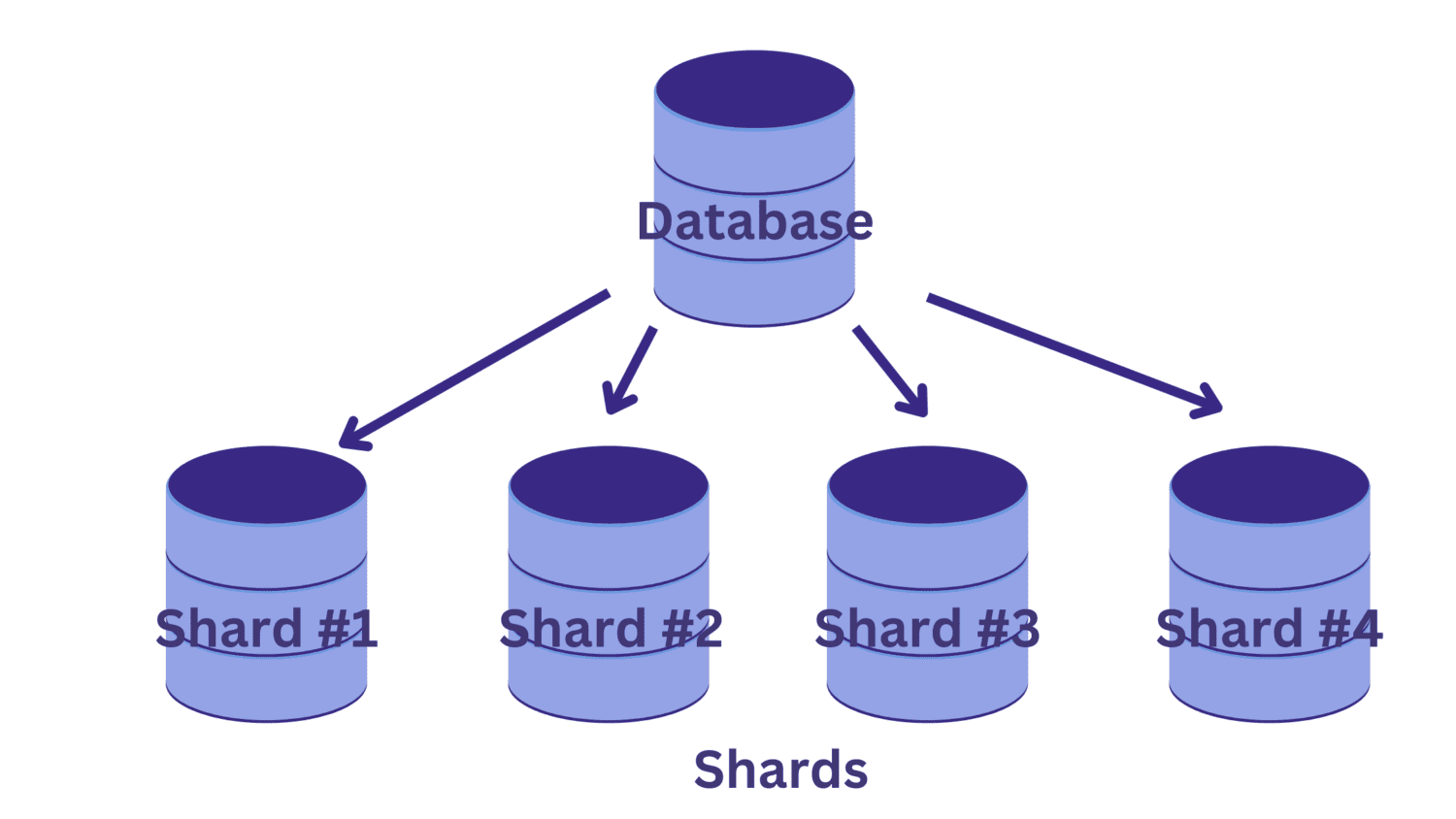
Men hur sker uppdelningen av databasen i shards? Och hur bestäms vilken data som ska lagras i vilken shard?
🔑 Lösningen är en ”sharding key”.
Förstå Sharding Key
Låt oss undersöka sharding key’s roll.
En sharding key, oftast en kolumn (eller en kombination av kolumner) i databastabellen, bör väljas så att datan är jämt fördelad mellan shards. Syftet är att undvika att en viss shard blir betydligt större än de andra.
I en databas som lagrar kund- och transaktionsdata är `customer_ID` en bra kandidat för en sharding key.
När sharding key har bestämts kan en hashfunktion användas för att bestämma vilken data som tillhör vilken shard.
I detta exempel, anta att databasen ska delas upp i fem shards (shard #0 till shard #4) med `customer_ID` som sharding key. En enkel hashfunktion är `customer_ID % 5`.
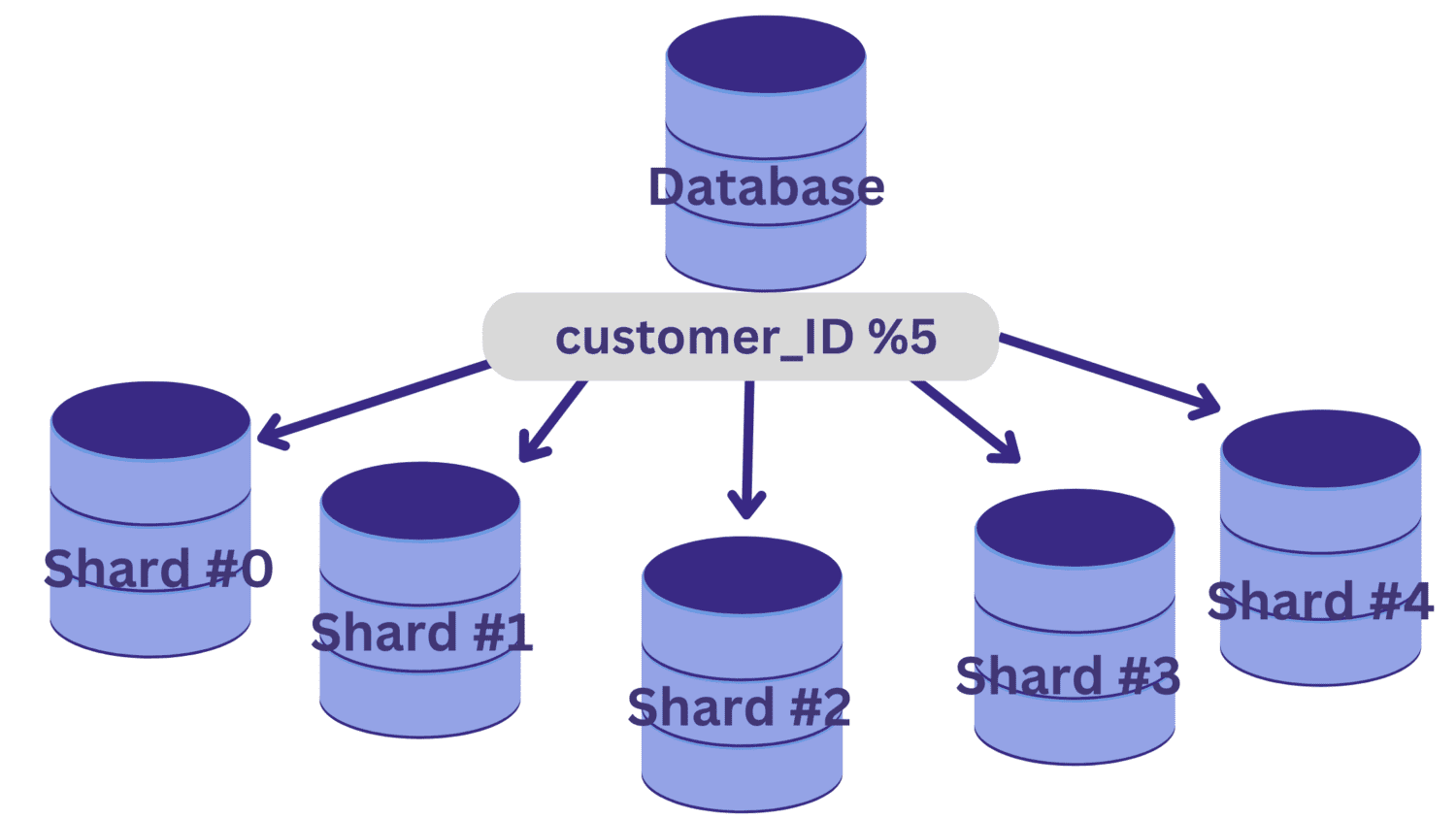
Alla `customer_ID`-värden som ger resten noll vid division med 5 tilldelas shard #0. `customer_ID`-värden som ger resten 1 till 4 tilldelas shard #1 till shard #4, respektive.
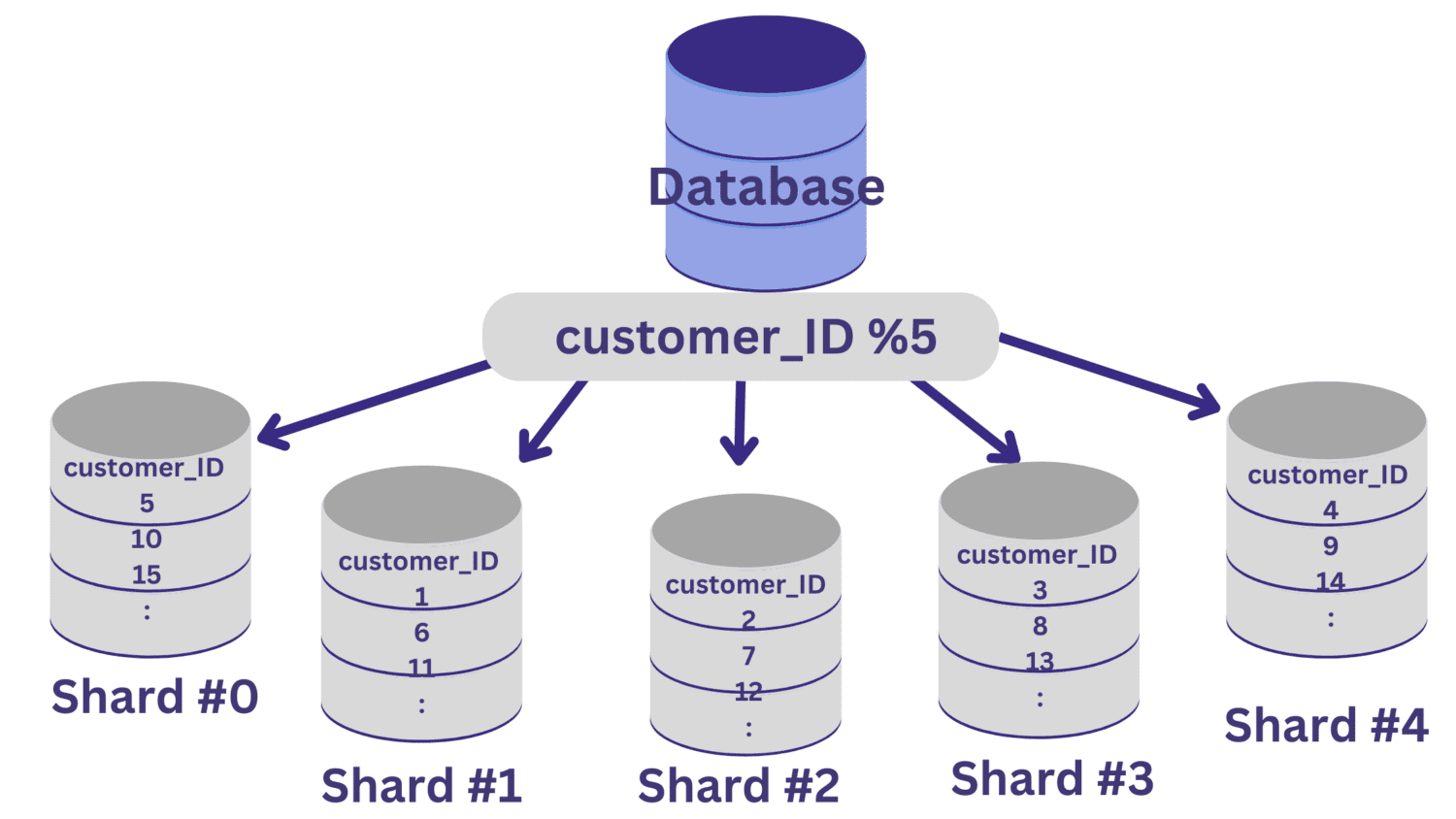
När databasdelningen har implementerats på det här sättet, är det viktigt att ha ett routinglager som dirigerar inkommande förfrågningar till rätt databasfragment.
Fördelar med databasskärning
Här följer några fördelar med databasskärning:
#1. Hög skalbarhet
Det är alltid möjligt att dela upp en stor databas i fler mindre shards. Databasskärning möjliggör alltså horisontell skalning.
#2. Hög tillgänglighet
När en enda databasserver hanterar alla inkommande förfrågningar finns det en enda felpunkt. Om databasservern slutar fungera, slutar hela applikationen att fungera.
Med databasskärning är sannolikheten för att alla shards är nere samtidigt relativt låg. Om en specifik shard är nere, kan vi inte hantera läsförfrågningar till just den sharden. Men övriga shards fortsätter att fungera. Detta resulterar i hög tillgänglighet och ökad feltolerans.
Begränsningar med databasskärning
Låt oss nu granska några begränsningar med databasskärning:
#1. Komplexitet
Även om skärning erbjuder fördelar som skalbarhet och feltolerans, medför det också ökad komplexitet.
Allt från att mappa data till partitioner till implementering av ett routinglager, det kräver betydande ansträngning att implementera sharding.
#2. Omskärning
En annan begränsning är behovet av omskärning.
Även om hashfunktionen kan skapa en jämn datadistribution, kan en shard bli betydligt större än andra. I det fallet måste omskärning övervägas, vilket medför kostnader.
#3. Komplexa frågor
När analyser ska utföras som kräver sammanlänkning av data från flera shards, istället för en enda databas, kan det vara utmanande. Det kan lösas med databasdenormalisering, men även det kräver extra ansträngning!
Sammanfattning
Låt oss avsluta med en sammanfattning.
Vertikal skalning är inte alltid en optimal lösning, och det rekommenderas inte att endast uppgradera serverns kapacitet. Vi har även granskat databasreplikering och horisontell partitionering samt deras begränsningar.
Vi har lärt oss hur databasskärning fungerar genom att dela upp en stor databas i mindre och mer hanterbara shards. Vi har diskuterat hur sharding key bör väljas noggrant för att få jämna partitioner och behovet av ett routinglager för att dirigera förfrågningar till rätt shard.
Databasskärning har fördelar som hög tillgänglighet och skalbarhet. Nackdelarna inkluderar komplexiteten i uppsättningen och behovet av omskärning om shards blir obalanserade.
Överväg därför att använda skärning om fördelarna överväger de komplexiteterna som införs. Undersök jämförelser mellan olika AWS-relationsdatabaser.