Betydelsen av data och anomalidetektering
Data utgör en grundläggande resurs för företag och organisationer. Dess värde realiseras fullt ut när den är korrekt strukturerad och effektivt hanterad.
Enligt undersökningar upplever hela 95% av dagens företag svårigheter med att hantera och strukturera ostrukturerad data, vilket skapar betydande utmaningar.
Här kommer datautvinning in i bilden. Det är en process som involverar att identifiera, analysera och utvinna meningsfulla mönster och värdefull insikt från omfattande mängder ostrukturerad data.
Företag använder sig av specialiserad programvara för att hitta mönster i stora datamängder. Detta hjälper dem att förstå sin kundbas och målgrupp bättre, samt utveckla affärs- och marknadsstrategier som ökar försäljningen och sänker kostnaderna.
Utöver de fördelarna är även upptäckt av bedrägerier och anomalier centrala tillämpningar inom datautvinning.
Denna artikel fokuserar på begreppet avvikelsedetektering, dess olika aspekter, och hur det kan vara ett effektivt verktyg för att skydda mot dataintrång och nätverksintrång, och därigenom stärka datasäkerheten.
Vad är avvikelsedetektering och dess kategorier?
Datautvinning handlar om att identifiera samband, relationer och tendenser. Inom ramen för detta är det också ett utmärkt sätt att upptäcka anomalier eller avvikande punkter i ett nätverk.
Anomalier i datautvinning är datapunkter som tydligt avviker från det normala mönstret som majoriteten av datauppsättningen följer.
Avvikelser kan kategoriseras på olika sätt, bland annat:
- Händelseförändringar: Dessa avser abrupta eller systematiska avvikelser från det tidigare etablerade normala beteendet.
- Extremvärden: Små, icke-systematiska anomala mönster som uppkommer i data. Dessa kan vidare indelas i globala, kontextuella och kollektiva extremvärden.
- Drifter: Långsamma, oregelbundna och långvariga förändringar i data.
Sammanfattningsvis är avvikelsedetektering en databehandlingsteknik som är mycket användbar för att upptäcka bedrägliga transaktioner, hantera fallstudier med ojämn balans och för att identifiera sjukdomar. Det är en viktig komponent i att skapa robusta datavetenskapliga modeller.
Ett företag kan exempelvis analysera sitt kassaflöde för att identifiera ovanliga eller återkommande transaktioner till okända bankkonton. Detta gör det möjligt att snabbt upptäcka bedrägerier och genomföra grundligare undersökningar.
Fördelar med avvikelsedetektering
Genom att analysera användarbeteenden kan avvikelsedetektering bidra till att förbättra säkerhetssystemens noggrannhet och precision.
Tekniken analyserar och tolkar olika typer av information som säkerhetssystem genererar, och identifierar därmed hot och potentiella risker inom nätverket.
Här är de viktigaste fördelarna med avvikelsedetektering för företag:
- Identifiering av säkerhetshot och dataintrång i realtid. Algoritmer baserade på artificiell intelligens (AI) genomsöker kontinuerligt data för att upptäcka onormala beteenden.
- Snabbare och effektivare spårning av onormala aktiviteter och mönster. Automatisering minskar behovet av manuell avvikelsedetektering och därmed minskar den tid och de resurser som krävs för att hantera hot.
- Minimering av operativa risker. Genom att identifiera operativa fel, som t.ex. plötsliga prestandafall, innan de inträffar, minskas de potentiella skadorna.
- Minskning av affärsskador. Genom att snabbt upptäcka anomalier kan företag undvika betydande förluster som kan uppstå om hot inte identifieras i tid.
Avvikelsedetektering är en värdefull resurs för företag som hanterar stora mängder kund- och affärsdata. Det hjälper inte bara till att hitta tillväxtmöjligheter utan också att eliminera säkerhetshot och operativa flaskhalsar.
Metoder för avvikelsedetektering
Avvikelsedetektering använder sig av en rad procedurer och maskininlärningsalgoritmer (ML) för att analysera data och identifiera hot.
De viktigaste metoderna för avvikelsedetektering är:
#1. Maskininlärningsmetoder
Dessa metoder använder maskininlärningsalgoritmer för att analysera data och upptäcka anomalier. De vanligaste algoritmerna för avvikelsedetektering är:
- Klusteralgoritmer
- Klassificeringsalgoritmer
- Djupinlärningsalgoritmer
Andra vanliga ML-tekniker är stödvketormaskiner (SVM), K-means-klustring och autokodare.
#2. Statistiska metoder
Statistiska metoder används för att identifiera ovanliga mönster i data genom att använda statistiska modeller. Exempelvis kan ovanliga fluktuationer i en maskins prestanda detekteras genom att identifiera värden som faller utanför det förväntade intervallet.
Vanliga statistiska metoder inkluderar hypotesprövning, IQR, Z-poäng, modifierad Z-poäng, densitetsuppskattning, boxplot, extremvärdesanalys och histogram.
#3. Datautvinningsmetoder

Datautvinningsmetoder använder sig av dataanalys och klustringstekniker för att identifiera anomalier i datauppsättningen. Vanliga metoder inkluderar spektral klustring, densitetsbaserad klustring och principal komponentanalys.
Klustringsalgoritmer används för att gruppera liknande datapunkter och identifiera de som faller utanför dessa grupper. Klassificeringsalgoritmer å sin sida tilldelar datapunkter till fördefinierade klasser och upptäcker punkter som inte tillhör någon av dessa.
#4. Regelbaserade metoder
Dessa metoder använder förutbestämda regler för att upptäcka anomalier i data.
Regelbaserade metoder är enklare att installera men kan sakna flexibilitet och kanske inte anpassar sig tillräckligt bra till förändringar i datamönster.
Till exempel kan ett regelbaserat system programmeras för att flagga transaktioner som överskrider ett visst belopp som bedrägliga.
#5. Domänspecifika metoder
Domänspecifika metoder är anpassade för att detektera avvikelser i specifika datasystem. De är mycket effektiva i sina specifika områden men kan vara mindre användbara utanför dessa.
Exempelvis kan domänspecifika metoder utformas för att upptäcka avvikelser i finansiella transaktioner, men kanske inte fungerar lika bra för att upptäcka avvikelser i maskinprestanda.
Varför maskininlärning är viktigt för avvikelsedetektering
Maskininlärning spelar en central roll i avvikelsedetektering.
Dagens företag och organisationer hanterar stora mängder data, från texter, kundinformation och transaktioner till mediefiler som bilder och video.
Att manuellt gå igenom all denna information är omöjligt. Dessutom har många företag problem med att strukturera och analysera ostrukturerad data.
Det är här maskininlärning (ML) kommer in i bilden. ML-tekniker används för att samla in, rensa, strukturera och analysera stora datamängder.
Maskininlärningsalgoritmer kan effektivt bearbeta stora datamängder och ger flexibilitet genom att använda och kombinera olika tekniker. Detta säkerställer bästa möjliga resultat.
Dessutom bidrar maskininlärning till att effektivisera processen för avvikelsedetektering och spara resurser.
Här är några ytterligare fördelar med maskininlärning inom avvikelsedetektering:
- Enklare detektering av avvikelser genom automatisering av mönsteridentifiering, utan att kräva specifik programmering.
- Maskininlärningsalgoritmer är anpassningsbara till förändrade datamönster, vilket säkerställer effektivitet över tid.
- Hantering av stora och komplexa datauppsättningar.
- Tidig identifiering av avvikelser när de inträffar, vilket sparar tid och resurser.
- Högre noggrannhet jämfört med traditionella metoder.
Avvikelsedetektering i kombination med maskininlärning ger snabbare och tidigare upptäckt av avvikelser, vilket minskar riskerna för säkerhetshot och skadliga intrång.
Maskininlärningsalgoritmer för avvikelsedetektering
Anomalier kan detekteras med hjälp av olika algoritmer för klassificering, klustring och associationsregelinlärning.
Dessa algoritmer delas vanligtvis in i två kategorier: övervakade och oövervakade inlärningsalgoritmer.
Övervakat lärande
Övervakad inlärning använder algoritmer som stödvketormaskiner, logistisk regression och linjär regression. Dessa tränas på märkt data, vilket innebär att träningsdatan inkluderar både normala indata och motsvarande utdata, eller onormala exempel. Målet är att göra prediktioner för osynlig data baserat på träningsdatamönstren.
Tillämpningsområden för övervakat lärande inkluderar bild- och taligenkänning, prediktiv modellering och naturlig språkbehandling (NLP).
Oövervakat lärande
Oövervakad inlärning tränas utan märkt data. Istället identifieras processer och underliggande datastrukturer utan någon vägledning.
Tillämpningar för oövervakat lärande inkluderar avvikelsedetektering, densitetsuppskattning och datakomprimering.
Låt oss nu utforska några populära maskininlärningsbaserade algoritmer för avvikelsedetektering.
Local Outlier Factor (LOF)
LOF är en algoritm för avvikelsedetektering som utgår från lokal datatäthet för att bestämma om en datapunkt är en anomali.
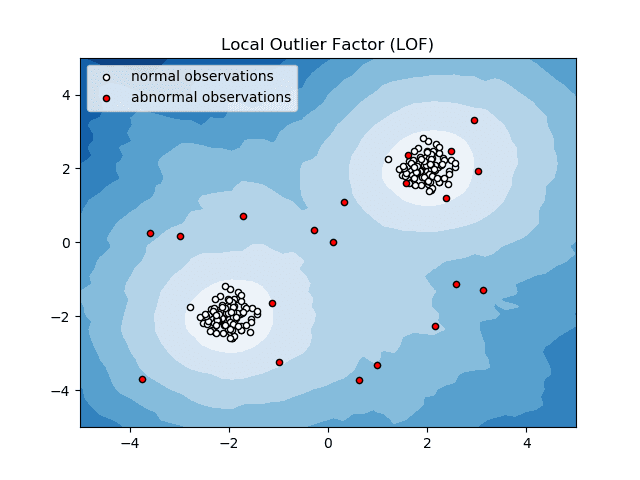
Algoritmen jämför den lokala tätheten hos ett objekt med tätheten hos dess grannar. Om ett objekt har en jämförelsevis lägre täthet än sina grannar betraktas det som en anomali.
Enkelt uttryckt, om tätheten runt ett objekt skiljer sig markant från tätheten runt dess grannar, identifieras objektet som avvikande. Algoritmen är en densitetsbaserad metod för extremvärdesdetektering.
K-Närmaste Granne (K-NN)
K-NN är en enkel klassificerings- och övervakad algoritm som lagrar alla tillgängliga exempel och data. Nya exempel klassificeras utifrån avståndsmåtten.
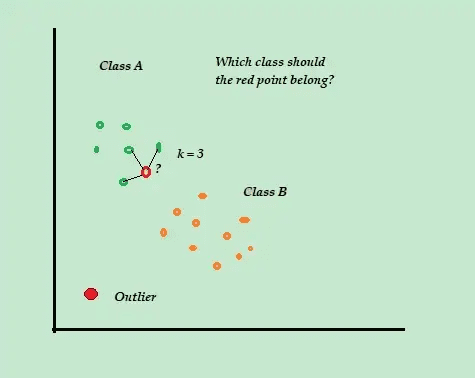
Algoritmen kallas också en lat elev eftersom den bara lagrar märkt träningsdata.
När en ny, omärkt datapunkt kommer analyserar algoritmen de K-närmaste träningsdatapunkterna för att klassificera den nya datapunkten.
Algoritmen använder följande metoder för att bestämma de närmaste datapunkterna:
- Euklidiskt avstånd för att mäta avståndet för kontinuerlig data.
- Hammingavstånd för att mäta likheten mellan två textsträngar för diskret data.
Om träningsdatan består av två klasser, A och B, och en ny datapunkt anländer, beräknar algoritmen avståndet mellan den nya punkten och varje datapunkt. Om K=3 och 2 av 3 datapunkter är märkta som A, klassificeras den nya punkten som klass A.
K-NN-algoritmen är mest användbar i dynamiska miljöer med frekventa datauppdateringar. Den används inom finans och företag för att upptäcka bedrägliga transaktioner och öka andelen upptäckt bedrägerier.
Support Vector Machine (SVM)
SVM är en övervakad maskininlärningsalgoritm som används för regressions- och klassificeringsproblem.
Den använder ett flerdimensionellt hyperplan för att dela upp data i två grupper (nya och normala). Hyperplanet fungerar som en gräns mellan normala data och ny data.
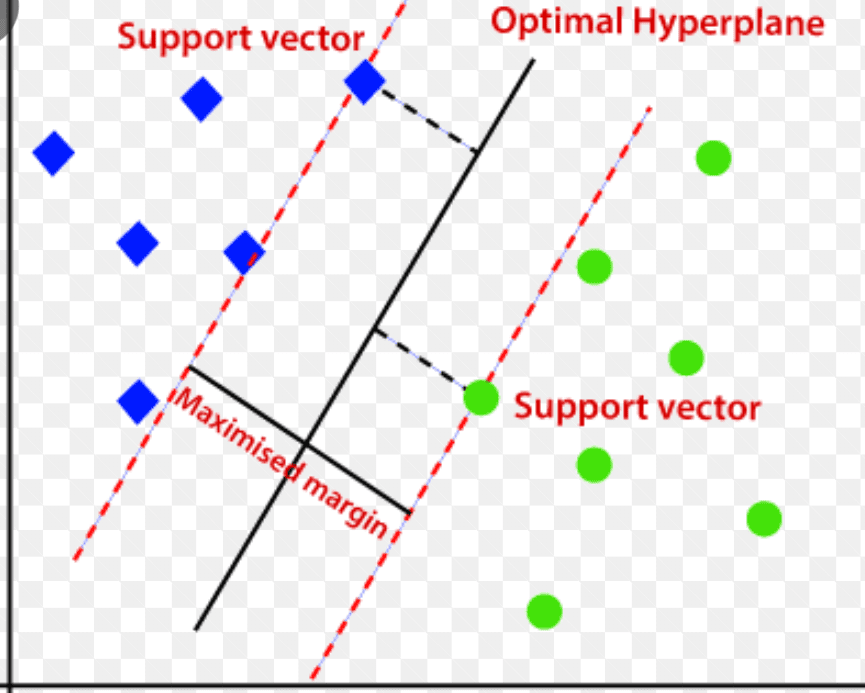
Avståndet mellan dessa två datapunkter kallas marginaler.
Målet är att maximera avståndet mellan de två grupperna. SVM bestämmer det bästa hyperplanet med maximal marginal.
När det gäller avvikelsedetektering, beräknar SVM marginalen för en ny datapunkt från hyperplanet för att klassificera den. Om marginalen överskrider en fördefinierad tröskel klassificeras den som en anomali. Om marginalen är mindre än tröskeln klassificeras den som normal.
SVM-algoritmer är mycket effektiva för att hantera komplexa datamängder med många dimensioner.
Isolationsskog
Isolation Forest är en oövervakad maskininlärningsalgoritm baserad på konceptet med en Random Forest Classifier.
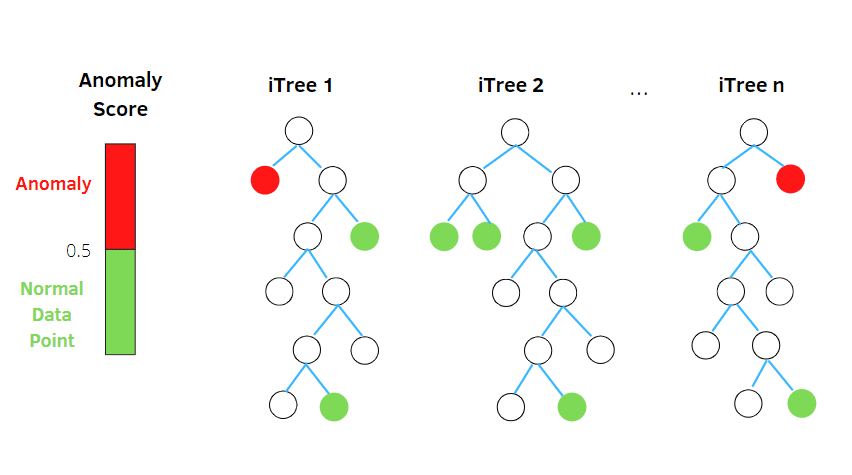
Algoritmen bearbetar slumpmässigt delar av data i en trädstruktur baserat på slumpmässiga attribut. Flera beslutsträd konstrueras för att isolera observationer. En viss observation betraktas som en anomali om den isoleras i färre träd.
Enkelt uttryckt, algoritmen delar in datapunkter i olika beslutsträd och isolerar observationer från varandra.
Anomalier ligger vanligtvis långt från datapunktsklustret, vilket gör dem lättare att identifiera.
Isolation Forest hanterar både kategorisk och numerisk data och är snabbare att träna, vilket gör den mycket effektiv vid upptäckt av avvikelser i stora datamängder med många dimensioner.
Kvartilavståndet
Interquartile range (IQR) används för att mäta statistisk variabilitet och hitta avvikande punkter genom att dela upp datamängderna i kvartiler.
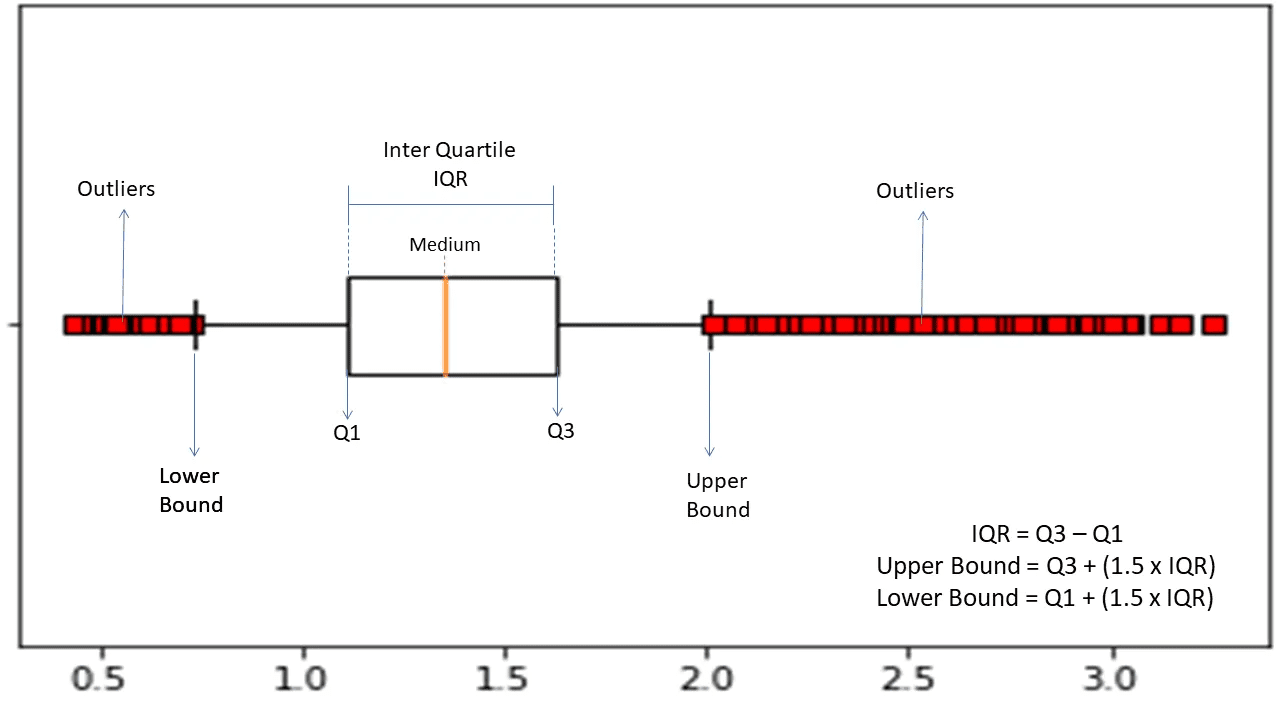
Algoritmen sorterar data i stigande ordning och delar in mängden i fyra lika delar. Värdena som skiljer delarna åt är Q1, Q2 och Q3.
Percentilfördelningen för kvartilerna är:
- Q1 anger den 25:e percentilen.
- Q2 anger den 50:e percentilen.
- Q3 anger den 75:e percentilen.
IQR är skillnaden mellan den tredje (75:e) och den första (25:e) percentilen, vilket representerar 50 % av datan.
För att använda IQR för avvikelsedetektering beräknas IQR för datan och de nedre och övre gränserna definieras för att hitta avvikelser.
- Nedre gräns: Q1 – 1,5 * IQR
- Övre gräns: Q3 + 1,5 * IQR
Observationer som faller utanför dessa gränser betraktas som anomalier.
IQR-algoritmen fungerar effektivt med datauppsättningar där datan inte är jämnt fördelad och där distributionen inte är fullt ut förstådd.
Sammanfattning
Cybersäkerhetsrisker och dataintrång ser inte ut att minska, snarare tvärtom. Denna riskfyllda industri förväntas växa ytterligare under kommande år. Enbart IoT-cyberattacker förväntas fördubblas till år 2025.
Cyberbrott kommer att kosta globala företag och organisationer uppskattningsvis 10,3 biljoner dollar årligen till 2025.
Detta gör att behovet av avvikelsedetektering blir allt större, för att upptäcka bedrägerier och förebygga nätverksintrång.
Denna artikel ger en grundläggande förståelse för vad anomalier är i datautvinning, olika typer av avvikelser, och hur man kan skydda sig mot nätverksintrång med hjälp av maskininlärningsbaserade metoder för avvikelsedetektering.
För ytterligare studier kan du utforska begreppet förvirringsmatrisen inom maskininlärning.