Apache Parquet erbjuder flera fördelar vid datalagring och datahämtning jämfört med traditionella metoder som CSV.
Parquet-formatet är konstruerat för att möjliggöra snabbare datahantering av komplexa datatyper. Den här artikeln undersöker hur Parquet-formatet möter de ständigt växande databehoven i dagens samhälle.
Innan vi dyker djupare in i detaljerna kring Parquet-formatet, låt oss först förstå vad CSV-data är och vilka utmaningar som är förknippade med det när det gäller datalagring.
Vad innebär CSV-lagring?
Vi har alla stött på CSV (Comma Separated Values) – ett av de vanligaste sätten att strukturera och formatera data. CSV-datalagring är radbaserad. CSV-filer har filändelsen .csv och vi kan lagra och öppna CSV-data med verktyg som Excel, Google Sheets eller vilken textredigerare som helst. Det är enkelt att se informationen när filen väl är öppnad.
Detta är inte optimalt, särskilt inte för ett databasformat.
När datamängderna växer blir det svårare att fråga, hantera och hämta data effektivt.
Här är ett exempel på hur data kan se ut i en .CSV-fil:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
I Excel ser vi datan presenterad i en rad- och kolumnstruktur:
Utmaningar med CSV-lagring
Radbaserade lagringsmetoder som CSV är praktiska för att skapa, uppdatera och radera data.
Men hur ser det ut med läsning av data?
Föreställ dig en .csv-fil med en miljon rader. Det skulle ta betydande tid att öppna filen och söka efter specifik information. Det är inte särskilt effektivt. Dessutom debiterar de flesta molntjänstleverantörer, som AWS, företag baserat på mängden data som skannas eller lagras – och CSV-filer kräver betydande lagringsutrymme.
CSV-lagring saknar även ett dedikerat sätt att lagra metadata, vilket gör dataskanning till en tidskrävande uppgift.
Så, vilken är den kostnadseffektiva och optimerade lösningen för att utföra alla CRUD-operationer? Låt oss undersöka det.
Vad är Parquet datalagring?
Parquet är ett öppen källkodsformat för att lagra data. Det är flitigt använt inom Hadoop- och Spark-ekosystemen. Parquet-filer har filändelsen .parquet.
Parquet är ett mycket strukturerat format. Det kan användas för att optimera komplexa rådata som lagras i stora mängder i datasjöar. Detta kan leda till betydande minskningar av frågetider.
Parquet möjliggör effektiv datalagring och snabbare hämtning genom att använda en kombination av rad- och kolumnbaserade (hybrid) lagringsformat. I detta format delas data in både horisontellt och vertikalt. Parquet-formatet eliminerar även overhead för parsing till stor del.
Formatet begränsar antalet I/O-operationer och därmed kostnaden.
Parquet lagrar även metadata, som ger information om data som dataschema, antal värden, kolumnplacering, min- och maxvärden, antal radgrupper, typ av kodning med mera. Metadata lagras på olika nivåer i filen, vilket underlättar snabbare dataåtkomst.
I radbaserad åtkomst som CSV tar datahämtning tid eftersom varje rad måste genomsökas för att hitta de specifika kolumnvärdena. Med Parquet-lagring kan alla nödvändiga kolumner nås direkt.
Sammanfattningsvis:
- Parquet använder en kolumnstruktur för datalagring.
- Det är ett optimerat dataformat för att lagra stora mängder komplex data i lagringssystem.
- Parquet-formatet stöder olika metoder för datakomprimering och kodning.
- Det minskar avsevärt tiden för dataskanning och frågekörning samt tar upp mindre diskutrymme jämfört med andra lagringsformat som CSV.
- Minimerar antalet IO-operationer, vilket sänker kostnaderna för lagring och frågekörning.
- Inkluderar metadata som underlättar datahämtning.
- Erbjuder stöd med öppen källkod.
Dataformat för Parquet
Innan vi tittar på ett exempel, låt oss granska hur data lagras i Parquet-formatet mer i detalj:
En fil kan bestå av flera horisontella partitioner som kallas radgrupper. Inom varje radgrupp tillämpas vertikal partitionering. Kolumnerna delas upp i flera kolumnbitar. Data lagras som sidor inuti kolumnbitarna. Varje sida innehåller kodade datavärden och metadata. Som tidigare nämnt lagras även metadata för hela filen i filens sidfot, på radgruppsnivå.
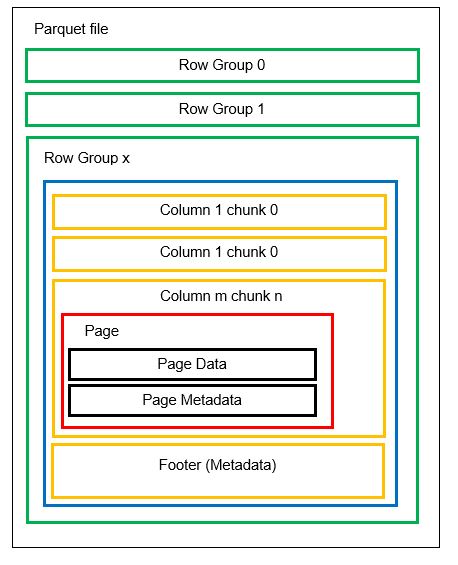
Eftersom data delas upp i kolumnbitar är det enkelt att lägga till ny data genom att koda de nya värdena till en ny bit och fil. Metadatan uppdateras sedan för de berörda filerna och radgrupperna. Därför kan vi konstatera att Parquet är ett flexibelt format.
Parquet stöder inbyggd datakomprimering med hjälp av sidkomprimering och tekniker för ordbokskodning. Låt oss titta på ett enkelt exempel på ordbokskomprimering:
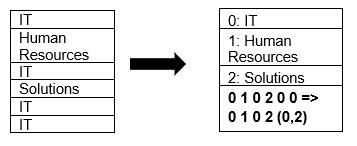
Observera att IT-avdelningen i exemplet ovan förekommer 4 gånger. När data lagras i ordboken kodar formatet data med ett annat, mer lagringseffektivt värde (0,1,2…) tillsammans med antalet gånger det upprepas i följd – IT, IT ändras till 0,2 för att spara mer utrymme. Att söka efter komprimerad data går snabbare.
Direkt jämförelse
Nu när vi har en klar bild av hur CSV- och Parquet-formaten fungerar är det dags att jämföra dem med lite statistik:
| CSV | Parquet | |
| Lagringsformat | Radbaserat lagringsformat. | En hybrid av radbaserade och kolumnbaserade lagringsformat. |
| Utrymmesförbrukning | Förbrukar mycket utrymme eftersom det inte finns något standardkompressionsalternativ. Till exempel kommer en fil på 1 TB att ta upp samma utrymme när den lagras på Amazon S3 eller någon annan molntjänst. | Komprimerar data under lagring, vilket ger en mindre utrymmesförbrukning. En fil på 1 TB som lagras i Parquet-format tar endast upp 130 GB utrymme. |
| Frågekörningstid | Långsam frågekörningstid på grund av den radbaserade sökningen. För varje kolumn måste varje rad med data hämtas. | Frågekörningstiden är cirka 34 gånger snabbare på grund av den kolumnbaserade lagringen och förekomsten av metadata. |
| Dataskanning | Mer data behöver skannas per fråga. | Cirka 99 % mindre data skannas för frågekörning, vilket optimerar prestandan. |
| Lagringskostnad | De flesta lagringsenheter tar betalt baserat på lagringsutrymmet, så CSV-formatet innebär höga lagringskostnader. | Mindre lagringskostnad eftersom data lagras i komprimerat och kodat format. |
| Filschema | Filschemat måste antingen härledas (vilket kan leda till fel) eller tillhandahållas (vilket är tidskrävande). | Filschemat lagras i metadata. |
| Datatyper | Formatet är lämpligt för enkla datatyper. | Parquet är lämpligt även för komplexa datatyper som kapslade scheman, matriser och ordböcker. |
Slutsats 👩💻
Genom exemplen ovan har vi sett att Parquet är mer effektivt än CSV när det gäller kostnad, flexibilitet och prestanda. Det är en effektiv mekanism för att lagra och hämta data, särskilt när världen rör sig mot molnlagring och utrymmesoptimering. Alla större plattformar som Azure, AWS och BigQuery stöder Parquet-formatet.