Fördjupa dig i den utforskande dataanalysens värld, en avgörande process för att identifiera tendenser och strukturer, samt summera datamängder genom statistiska översikter och visuella presentationer.
Precis som alla andra projekt, är ett datavetenskapligt initiativ en omfattande resa som kräver engagemang, skicklig organisation och en noggrann hantering av många steg. Explorativ dataanalys (EDA) framträder som en av de viktigaste faserna i detta förlopp.
I den här artikeln undersöker vi därför kortfattat vad utforskande dataanalys innebär och hur du kan använda R för att utföra den.
Vad är Explorativ Dataanalys?
Explorativ dataanalys fokuserar på att granska och studera egenskaperna hos en datamängd innan den integreras i en applikation, oavsett om den är avsedd för affärsändamål, statistiska analyser eller maskininlärning.
Denna sammanfattning av informationens karaktär och dess viktigaste särdrag utförs vanligtvis med hjälp av visuella verktyg, som till exempel grafiska representationer och tabeller. Denna process genomförs i ett tidigt skede för att utvärdera potentialen i datan, som senare kommer att genomgå en mer komplex analys.
EDA möjliggör därför:
- Att formulera hypoteser för hur denna information kan användas.
- Att avslöja dolda detaljer i datans struktur.
- Att upptäcka saknade värden, extremvärden eller avvikande beteenden.
- Att identifiera övergripande trender och viktiga variabler.
- Att avlägsna irrelevanta variabler eller variabler som är korrelerade med andra.
- Att avgöra vilken formell modellering som är lämplig.
Vad är Skillnaden Mellan Beskrivande och Utforskande Dataanalys?
Det finns två huvudtyper av dataanalys: beskrivande och utforskande, som båda är viktiga, men har olika syften.
Beskrivande analys fokuserar på att detaljerat skildra variablernas beteende, genom metoder som beräkning av medelvärde, median och läge.
Utförande analys syftar istället till att identifiera korrelationer mellan variabler, extrahera preliminära insikter och guida modelleringen mot de vanligaste maskininlärningsmetoderna: klassificering, regression och klusteranalys.
Båda typerna kan använda grafisk presentation. Däremot är det endast utforskande analys som strävar efter att ge konkreta insikter som kan leda till handling hos den som fattar besluten.
Sammanfattningsvis, medan utforskande dataanalys försöker lösa problem och hitta lösningar som kan styra de kommande modellstegen, är beskrivande analys, som namnet antyder, uteslutande inriktad på att producera en detaljerad beskrivning av den aktuella datamängden.
| Beskrivande Analys | Utforskande Dataanalys |
| Analyserar beteende | Analyserar beteende och relationer |
| Ger en sammanfattning | Leder till specifikationer och åtgärder |
| Organiserar data i tabeller och grafer | Organiserar data i tabeller och grafer |
| Har inte betydande förklaringskraft | Har betydande förklaringsförmåga |
Praktiska Tillämpningar av EDA
#1. Digital Marknadsföring
Digital marknadsföring har omvandlats från en kreativ process till en datadriven verksamhet. Marknadsföringsföretag nyttjar utforskande dataanalys för att utvärdera effektiviteten av kampanjer och för att styra konsumentinvesteringar och inriktningsstrategier.
Demografiska studier, kundsegmentering och andra tekniker ger marknadsförare möjlighet att analysera stora mängder data från konsumentköp, enkäter och paneler för att förstå och kommunicera strategisk marknadsföring.
Undersökande webbanalys hjälper marknadsförare att samla in detaljerad information på sessionsnivå om interaktioner på en webbplats. Google Analytics är ett populärt verktyg som används gratis av många marknadsförare för detta ändamål.
Undersökande metoder som ofta används i marknadsföring inkluderar modellering av marknadsföringsmix, prissättnings- och marknadsföringsanalyser, försäljningsoptimering och utforskande kundanalys, såsom segmentering.
#2. Utforskande Portföljanalys
En vanlig tillämpning av utforskande dataanalys är portföljanalys. En bank eller ett kreditinstitut har en samling konton med varierande värde och risk.
Konton kan differentiera beroende på innehavarens socioekonomiska status (rik, medelklass, låginkomst), geografiska placering, förmögenhet och många andra aspekter. Långivaren måste väga avkastningen på lånet mot risken för betalningsförsening för varje enskilt lån. En viktig frågeställning blir hur man ska utvärdera portföljen som helhet.
De mest risknedbringande lånen kan vara de som beviljas mycket förmögna personer, men det finns ett begränsat antal sådana individer. Å andra sidan finns det fler personer med låg inkomst som kan beviljas lån, men med en högre risk.
Med utforskande dataanalys kan man kombinera tidsseriedata med andra variabler för att avgöra när det är lämpligt att bevilja lån till olika kundsegment, samt vilka räntesatser som ska tillämpas. Räntan beräknas sedan för att täcka potentiella förluster inom respektive segment.
#3. Utforskande Riskanalys
Prediktiva modeller inom banksektorn utvecklas för att ge säkerhet i riskbedömningen av enskilda kunder. Kreditpoäng är konstruerade för att förutsäga en individs potentiella betalningsproblem och används ofta för att bedöma kreditvärdigheten.
Riskanalyser utförs även inom forskningsvärlden och försäkringsbranschen. De används ofta av finansiella institutioner och betalningsplattformar online för att granska om en transaktion är legitim eller inte.
I detta syfte används kundens transaktionshistorik. Det är särskilt vanligt vid kreditkortsbetalningar. Om en plötslig ökning i transaktionsvolym observeras, kontaktas kunden för att verifiera att transaktionen är legitim. Detta hjälper även till att minska förluster till följd av bedrägliga transaktioner.
Utförande av Explorativ Dataanalys med R
För att genomföra EDA med R, behöver du först ladda ner R base och R Studio (IDE), samt installera och ladda följande paket:
#Installera Paket
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Ladda Paket
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
I den här guiden använder vi en ekonomisk datamängd som ingår i R, som ger årliga ekonomiska indikatorer för den amerikanska ekonomin. Vi ändrar namnet till `econ` för enkelhetens skull:
econ <- ggplot2::economics
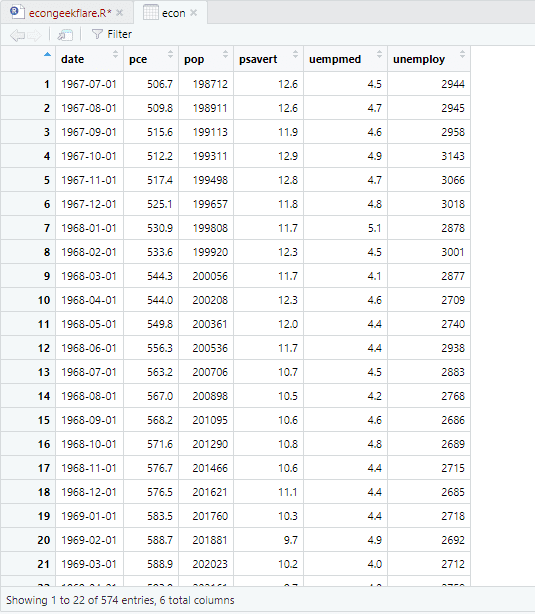
För att genomföra den beskrivande analysen använder vi paketet `skimr`, som beräknar denna statistik på ett tydligt och lättöverskådligt sätt:
#Beskrivande Analys skimr::skim(econ)

Du kan även använda funktionen `summary` för beskrivande analys:
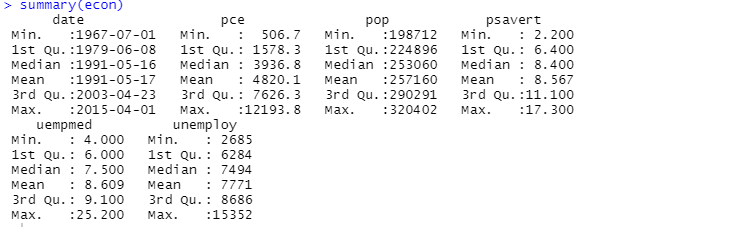
Här visas att den beskrivande analysen inkluderar 547 rader och 6 kolumner. Minimumvärdet avser 1967-07-01 och det högsta värdet är 2015-04-01. Medelvärdet och standardavvikelsen presenteras också.
Nu har du en grundläggande uppfattning om vad datamängden `econ` innehåller. Låt oss skapa ett histogram över variabeln `uempmed` för att visualisera datan bättre:
#Histogram av Arbetslöshet econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Arbetslöshet", title = "Månatlig Arbetslöshet i USA Mellan 1967 och 2015")
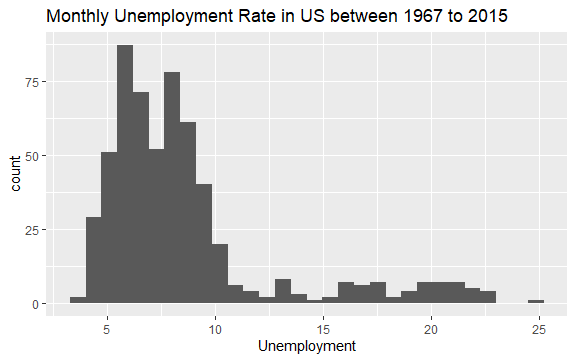
Histogrammets fördelning visar att det har en lång svans åt höger, vilket indikerar att det möjligen finns observationer av denna variabel med mer ”extrema” värden. Frågan uppstår: Under vilken period inträffade dessa värden och hur ser trenden för variabeln ut?
Det mest direkta sättet att identifiera en variabels trend är med ett linjediagram. Nedan skapar vi ett linjediagram och lägger till en utjämningslinje:
#Linjediagram över Arbetslöshet econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
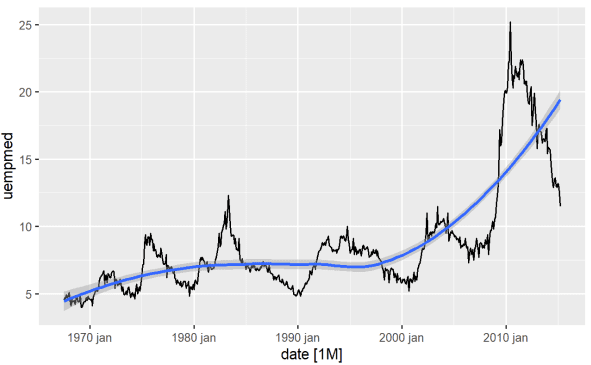
Med hjälp av detta diagram kan vi se att det under den senaste perioden, de senaste observationerna från 2010, har varit en tendens till ökad arbetslöshet, vilket överstiger de nivåer som observerats under tidigare decennier.
En annan viktig faktor, särskilt i ekonometriska modelleringssammanhang, är seriens stationaritet. Det vill säga, är medelvärdet och variansen konstanta över tid?
Om dessa antaganden inte stämmer för en variabel, säger vi att serien har en enhetsrot (icke-stationär) vilket innebär att de yttre påverkan som variabeln utsätts för genererar en permanent effekt.
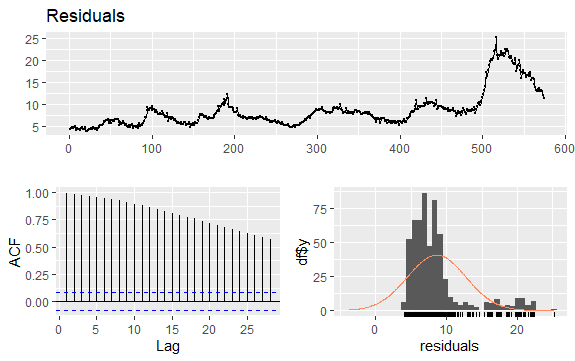
Det verkar vara fallet för variabeln i fråga, arbetslöshetens varaktighet. Vi har sett att variabelns fluktuationer har förändrats avsevärt, vilket har viktiga implikationer som relaterar till ekonomiska teorier om cykler. Men hur kontrollerar vi praktiskt om variabeln är stationär, och avviker från teorin?
Prognospaketet har en utmärkt funktion som gör det möjligt att tillämpa tester, som ADF, KPSS och andra, som redan anger antalet nödvändiga differenser för att serien ska vara stationär:
#Använd ADF-test för att kontrollera stationaritet forecast::ndiffs( x = econ$uempmed, test = "adf")

Här visar p-värdet som är större än 0,05 att datan är icke-stationär.
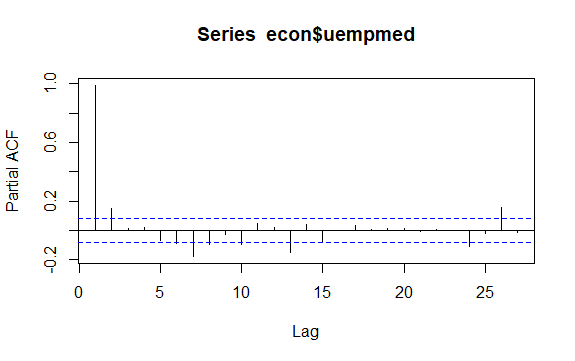
En annan viktig aspekt i tidsserier är att identifiera möjliga korrelationer (linjära samband) mellan de fördröjda värdena i serien. Korrelogrammen ACF och PACF hjälper till att göra detta.
Eftersom serien inte har säsongsvariationer utan har en viss trend, tenderar de initiala autokorrelationerna att vara stora och positiva eftersom observationer som är nära i tid även är nära i värde.
Autokorrelationsfunktionen (ACF) för en tidsserie med trend tenderar därmed att ha positiva värden som minskar långsamt när fördröjningarna ökar.
#Residualer av Arbetslöshet checkresiduals(econ$uempmed) pacf(econ$uempmed)
Slutsats
När vi får tillgång till data som är mer eller mindre bearbetad, frestas vi ofta att direkt hoppa in i modellkonstruktionsstadiet för att snabbt se resultat. Vi bör dock motstå denna frestelse och istället påbörja utforskande dataanalys, vilket är en enkel men kraftfull metod för att få värdefulla insikter om datan.
Du kan även undersöka några av de bästa resurserna för att lära dig statistik för datavetenskap.