Denna artikel belyser och förklarar ett urval av de mest framstående Python-biblioteken som är ovärderliga för dataforskare och team som arbetar med maskininlärning.
Python har etablerat sig som ett idealiskt programmeringsspråk inom dessa två discipliner, främst tack vare det omfattande utbudet av tillgängliga bibliotek.
Dessa Python-bibliotek möjliggör funktioner som datainmatning och utmatning, dataanalys samt diverse datamanipuleringsoperationer, vilka är väsentliga för att dataforskare och maskininlärningsexperter ska kunna hantera och utforska data effektivt.
Vad är Python-bibliotek?
Ett Python-bibliotek utgörs av en bred samling av fördefinierade moduler, som innehåller förkompilerad kod, inklusive klasser och metoder. Detta eliminerar behovet för utvecklare att skriva all kod från grunden.
Pythons betydelse inom datavetenskap och maskininlärning
Python tillhandahåller några av de bästa biblioteken för maskininlärnings- och datavetenskapsexperter.
Dess lättförståeliga syntax underlättar implementeringen av komplexa maskininlärningsalgoritmer. Dessutom gör den enkla syntaxen inlärningsprocessen kortare och mer lättillgänglig.
Python stöder även snabb prototypframställning och smidig testning av applikationer.
Den stora Python-gemenskapen är en stor fördel för dataforskare, då de enkelt kan finna lösningar på sina problem när det behövs.
Hur användbara är Python-bibliotek?
Python-bibliotek är grundläggande för utvecklingen av applikationer och modeller inom maskininlärning och datavetenskap.
Dessa bibliotek spelar en stor roll i att underlätta kodåteranvändning. Istället för att utveckla en specifik funktion på nytt, kan du enkelt importera ett relevant bibliotek som redan implementerar den önskade funktionaliteten i ditt program.
Python-bibliotek för maskininlärning och datavetenskap
Dataexperter rekommenderar att dataforskare bekantar sig med ett flertal Python-bibliotek. Beroende på applikationens behov använder maskininlärnings- och datavetenskapsspecialister olika bibliotek, indelade i kategorier som bibliotek för modellimplementering, datautvinning, databearbetning och datavisualisering.
Denna artikel lyfter fram några av de vanligaste Python-biblioteken inom datavetenskap och maskininlärning.
Låt oss utforska dessa närmare.
Numpy
Numpy, vilket står för Numerical Python, är ett Python-bibliotek byggt med högoptimerad C-kod. Dataforskare föredrar detta bibliotek för dess avancerade matematiska och vetenskapliga beräkningsförmåga.
Funktioner
- Numpy har en användarvänlig syntax, vilket gör det enkelt för programmerare att använda, oavsett tidigare erfarenhet.
- Bibliotekets prestanda är mycket hög tack vare den optimerade C-koden.
- Det innehåller verktyg för numeriska beräkningar, inklusive Fourier-transformationsfunktioner, linjär algebra och slumptalsgeneratorer.
- Det är ett open source-projekt, vilket möjliggör ett stort antal bidrag från andra utvecklare.
Numpy erbjuder även andra omfattande funktioner, såsom vektorisering av matematiska operationer, indexering samt grundläggande koncept för att implementera matriser.
Pandas
Pandas är ett framstående bibliotek inom maskininlärning som tillhandahåller avancerade datastrukturer och verktyg för att analysera stora datamängder på ett effektivt sätt. Med bara ett fåtal kommandon kan detta bibliotek utföra komplexa dataoperationer.
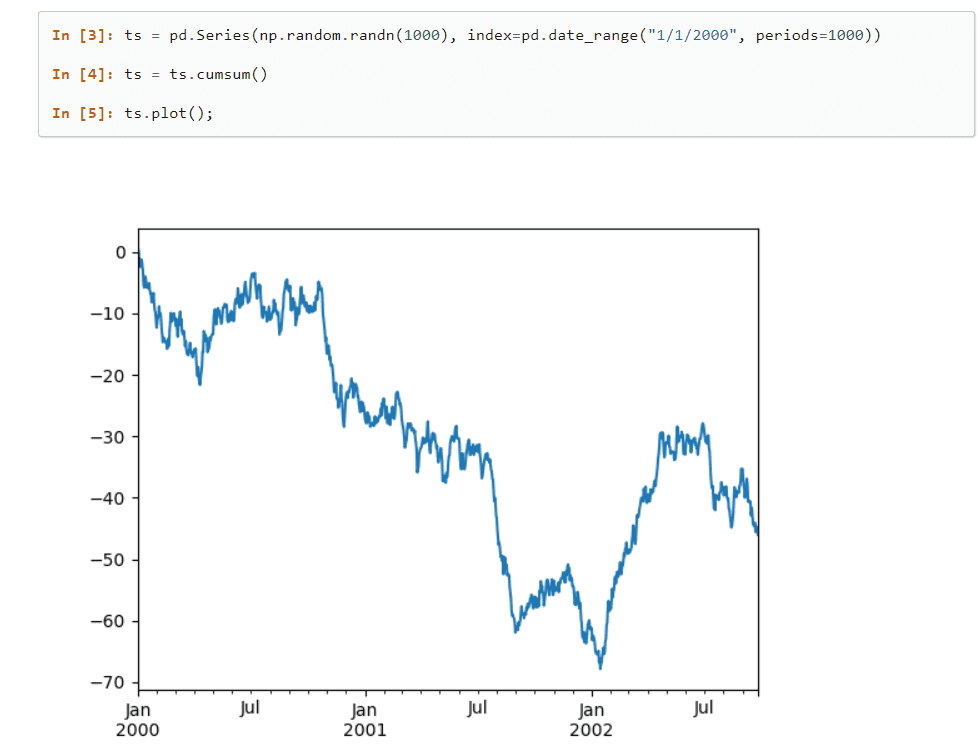
Biblioteket har många inbyggda metoder för att gruppera, indexera, hämta, dela, omstrukturera och filtrera datamängder, vilket möjliggör insättning i enkla och flerdimensionella tabeller.
Huvudfunktioner i Pandas
- Pandas gör det enkelt att etikettera data i tabeller och automatiskt justera och indexera data.
- Det kan snabbt läsa in och spara dataformat som JSON och CSV.
Det är mycket effektivt tack vare sina starka dataanalysfunktioner och höga flexibilitet.
Matplotlib
Matplotlib är ett 2D-grafiskt Python-bibliotek som hanterar data från en mängd olika källor. Visualiseringarna som skapas är statiska, animerade och interaktiva, vilket ger användaren möjlighet att zooma in, vilket gör det effektivt för visualiseringar och skapande av diagram. Det möjliggör även anpassning av layout och visuell stil.
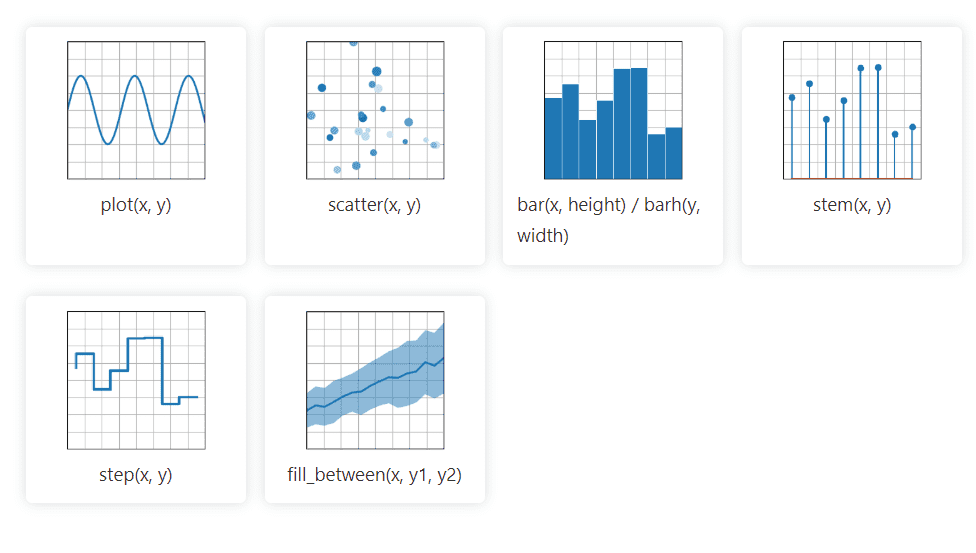
Bibliotekets dokumentation är öppen källkod och erbjuder en omfattande samling verktyg för implementering.
Matplotlib importerar hjälpklasser för att hantera år, månad, dag och vecka, vilket gör det effektivt för att arbeta med tidsseriedata.
Scikit-lär dig
Om du söker ett bibliotek för att hantera komplex data, är Scikit-learn ett utmärkt val. Det används flitigt av maskininlärningsexperter och är sammankopplat med bibliotek som NumPy, SciPy och matplotlib. Biblioteket erbjuder både övervakade och oövervakade inlärningsalgoritmer som kan användas i produktionsapplikationer.

Funktioner i Scikit-learn
- Identifiering av objektkategorier, till exempel genom att använda algoritmer som SVM och random forest i tillämpningar som bildigenkänning.
- Förutsägelse av ett kontinuerligt attributvärde associerat med ett objekt, vilket kallas regression.
- Extrahering av särdrag.
- Reduktion av dimensioner, där man minskar antalet slumpvariabler.
- Klustring av liknande objekt i grupper.
Scikit-learn är effektivt för att extrahera särdrag från text- och bilddata. Dessutom är det möjligt att kontrollera noggrannheten hos övervakade modeller på okänd data. De många tillgängliga algoritmerna underlättar datautvinning och andra maskininlärningsuppgifter.
SciPy
SciPy, eller Scientific Python, är ett bibliotek för maskininlärning som erbjuder moduler för matematiska funktioner och algoritmer. Dess algoritmer löser algebraiska ekvationer, interpolation, optimering, statistik och integration.
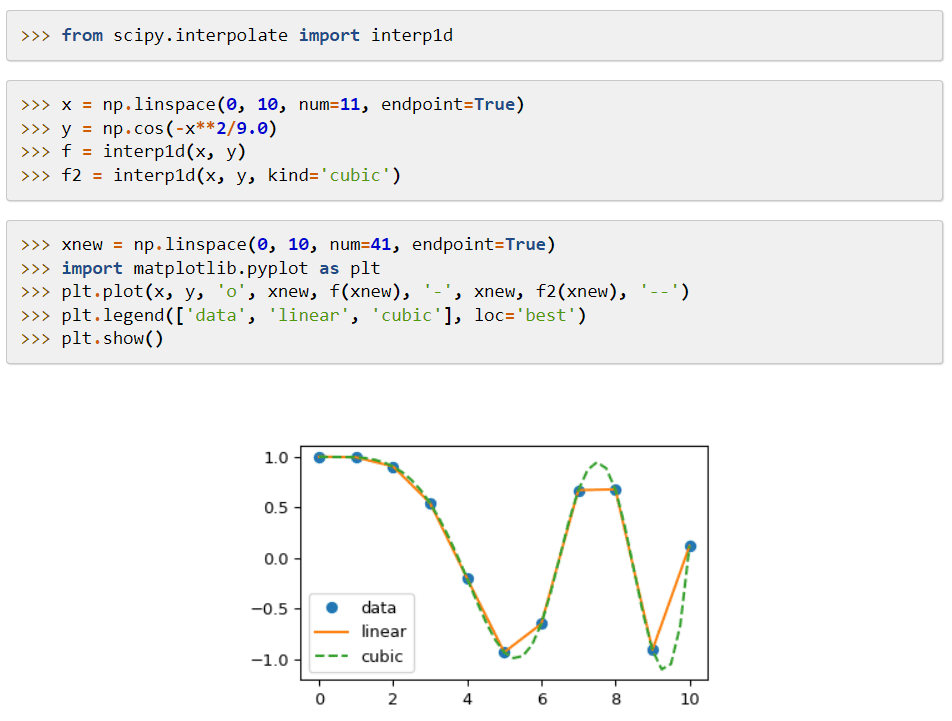
Dess huvudsakliga funktion är att utöka NumPy genom att lägga till verktyg för att lösa matematiska funktioner och tillhandahålla datastrukturer som glesa matriser.
SciPy använder kommandon och klasser på hög nivå för att manipulera och visualisera data. Dess databehandlings- och prototypsystem gör det till ett mycket effektivt verktyg.
SciPys användarvänliga syntax gör det enkelt för programmerare på alla erfarenhetsnivåer att använda.
SciPys enda nackdel är dess fokus på numeriska objekt och algoritmer, vilket innebär att det inte erbjuder någon plottningsfunktion.
PyTorch
Detta flexibla bibliotek för maskininlärning implementerar effektivt tensorberäkningar med GPU-acceleration, skapar dynamiska beräkningsgrafer och utför automatiska gradientberäkningar. PyTorch-biblioteket är baserat på Torch, ett open source-bibliotek för maskininlärning utvecklat i C.

Huvudfunktioner:
- Det erbjuder smidig utveckling och skalning tack vare bra stöd på stora molnplattformar.
- Ett robust ekosystem av verktyg och bibliotek stödjer utveckling inom datorseende och andra områden som Natural Language Processing (NLP).
- Det ger en mjuk övergång mellan ivriga och grafiska lägen med Torch Script, samtidigt som det använder TorchServe för att påskynda vägen till produktion.
- Torch distribuerade backend möjliggör distribuerad utbildning och prestandaoptimering inom forskning och produktion.
Du kan använda PyTorch för att utveckla NLP-applikationer.
Keras
Keras är ett open source Python-bibliotek för maskininlärning som används för att experimentera med djupa neurala nätverk.
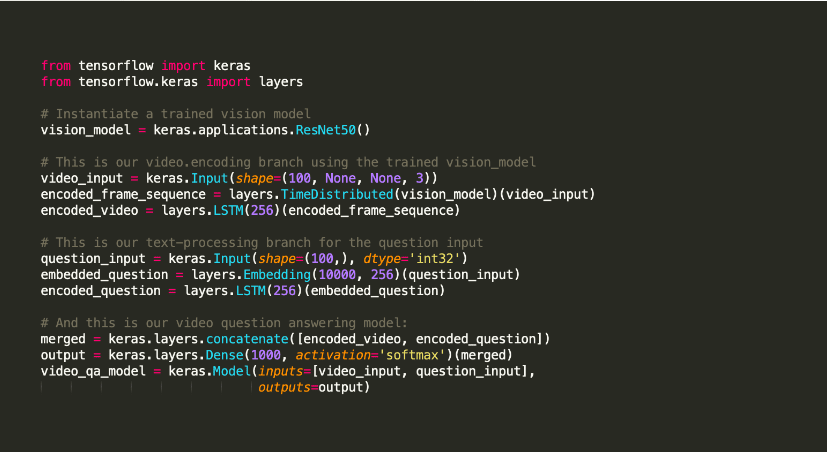
Det är känt för att erbjuda verktyg som stöder uppgifter som modellkompilering och grafvisualiseringar. Det använder Tensorflow som backend. Alternativt kan Theano eller neurala nätverk som CNTK användas i backend. Denna backend-infrastruktur hjälper till att skapa beräkningsgrafer för att implementera operationer.
Huvudfunktioner i biblioteket
- Det kan köras effektivt på både centralprocessorer och grafiska processorer.
- Felsökning är enklare i Keras då det är baserat på Python.
- Keras är modulärt, vilket gör det uttrycksfullt och anpassningsbart.
- Du kan implementera Keras var som helst genom att exportera dess moduler till JavaScript för att köra i webbläsaren.
Keras används bland annat för att skapa byggstenar för neurala nätverk som lager och mål, och erbjuder verktyg för att underlätta arbete med bilder och textdata.
Seaborn
Seaborn är ett annat värdefullt verktyg för statistisk datavisualisering.
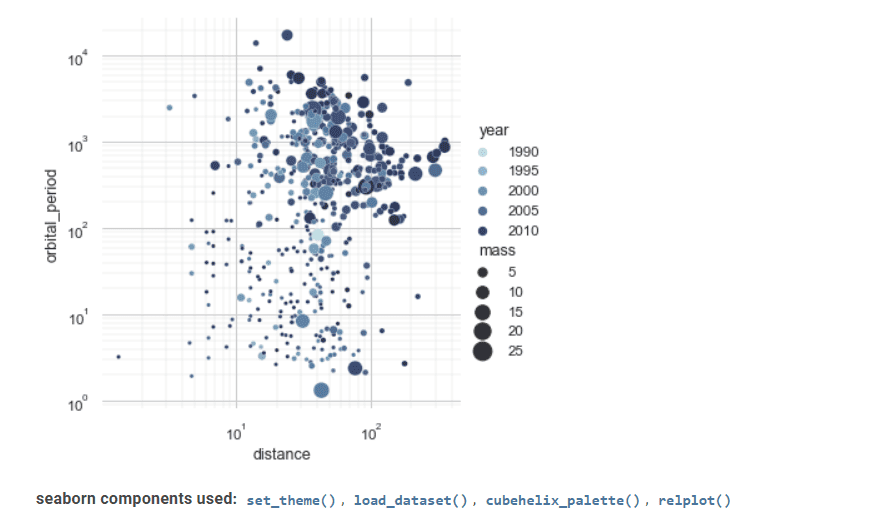
Dess avancerade gränssnitt kan skapa attraktiva och informativa statistiska grafikritningar.
Plotly
Plotly är ett 3D-webbaserat visualiseringsverktyg som bygger på Plotly JS-biblioteket. Det har stöd för en mängd diagramtyper, inklusive linjediagram, spridningsdiagram och rutatyper.
Det används för att skapa webbaserade datavisualiseringar i Jupyter-anteckningsböcker.
Plotly är lämpligt för visualisering eftersom det kan markera extremvärden eller avvikelser i grafen med sitt hover-verktyg. Du kan också anpassa graferna efter dina behov.
En nackdel med Plotly är att dokumentationen är föråldrad, vilket kan göra det svårt för användare. Dessutom har det många verktyg som användaren måste lära sig, vilket kan vara svårt att hålla reda på.
Funktioner i Plotly
- De 3D-diagram som används erbjuder flera interaktionspunkter.
- Det har en förenklad syntax.
- Du kan dela dina visualiseringar utan att kompromissa med kodens integritet.
SimpleITK
SimpleITK är ett bibliotek för bildanalys som erbjuder ett gränssnitt till Insight Toolkit (ITK). Det är baserat på C++ och är open source.
Funktioner i SimpleITK
- Dess bildfil I/O stöder och kan konvertera över 20 bildfilformat, inklusive JPG, PNG och DICOM.
- Det tillhandahåller ett stort antal filter för bildsegmentering, inklusive Otsu, nivåuppsättningar och vattendelar.
- Det tolkar bilder som rumsliga objekt snarare än en samling pixlar.
Dess förenklade gränssnitt är tillgängligt i olika programmeringsspråk som R, C#, C++, Java och Python.
Statsmodell
Statsmodel beräknar statistiska modeller, implementerar statistiska tester och utforskar statistisk data med hjälp av klasser och funktioner.
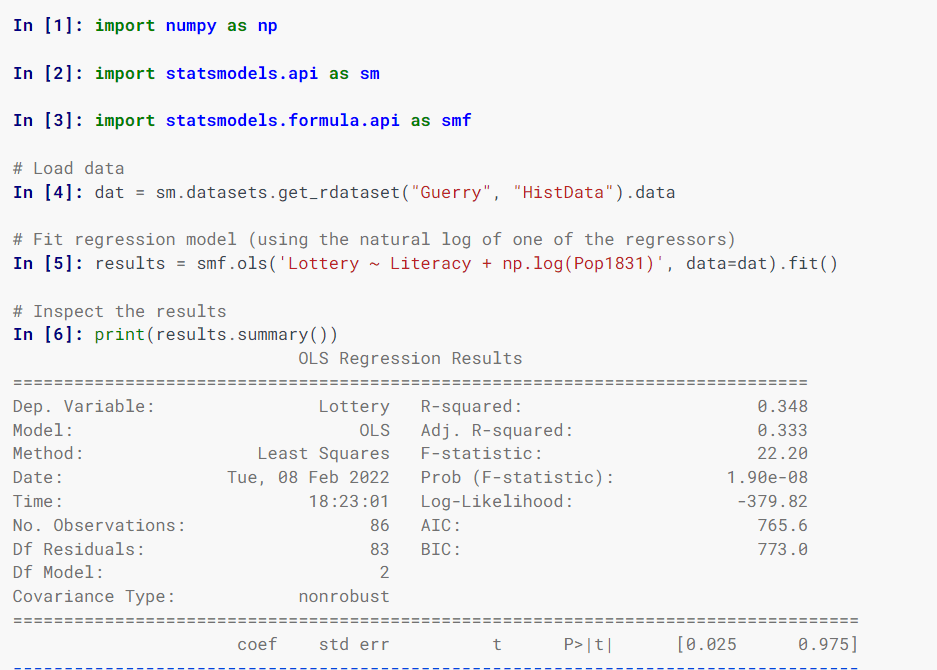
Modellerna använder R-formler, NumPy-matriser och Pandas-dataframes.
Scrapy
Detta open source-paket är ett populärt verktyg för att hämta och genomsöka data från webbplatser. Det är asynkront, vilket gör det relativt snabbt. Scrapy har en arkitektur och funktioner som gör det effektivt.
En nackdel är att installationen varierar mellan olika operativsystem. Dessutom kan det inte användas på webbplatser byggda med JS. Det fungerar endast med Python 2.7 eller senare versioner.
Dataexperter använder det inom datautvinning och automatiserad testning.
Funktioner
- Det kan exportera flöden i JSON, CSV och XML och lagra dem i flera backend-system.
- Det har inbyggd funktionalitet för att samla in och extrahera data från HTML/XML-källor.
- Du kan använda ett väldefinierat API för att utöka Scrapy.
Pillow
Pillow är ett Python-bibliotek för bildhantering som används för att manipulera och bearbeta bilder.
Det utökar Python-tolkens bildbehandlingsfunktioner, stöder olika filformat och erbjuder en utmärkt intern representation.
Data som lagras i vanliga filformat är enkelt tillgängliga tack vare Pillow.
Sammanfattning💃
Detta sammanfattar vår utforskning av några av de bästa Python-biblioteken för dataforskare och maskininlärningsexperter.
Som den här artikeln visar har Python många användbara paket för maskininlärning och datavetenskap. Python har även andra bibliotek som kan användas inom andra områden.
Du kanske också är intresserad av att lära dig mer om några av de bästa anteckningsböckerna för datavetenskap.
Lycka till med inlärningen!