Står du inför utmaningar när du ska felsöka din kod? Söker du efter loggningslösningar som kan underlätta felsökningsprocessen? Läs vidare för att lära dig mer om detta.
Programvaruutveckling är en process som innefattar flera steg: insamling av krav, analys, kodning, testning och underhåll. Bland dessa steg är kodnings-/utvecklingsfasen ofta den mest tidskrävande och krävande. Programvaruingenjörer hanterar olika typer av fel, inklusive syntaxfel, logiska fel och exekveringsfel. Syntaxfel, som uppstår när koden inte följer reglerna för det specifika programmeringsspråket, kan identifieras under kompileringen.
Logiska fel och exekveringsfel är däremot svårare att upptäcka eftersom de inte kan identifieras av den integrerade utvecklingsmiljön (IDE). Att åtgärda dessa fel kräver ofta en djupare felsökningsprocess, vilket kan vara tidskrävande.
Felsökning handlar om att förstå varför den skrivna koden inte fungerar som förväntat. Det blir betydligt enklare att lösa ett problem när vi kan identifiera exakt var felet uppstår och vilka kodrader som är inblandade. Loggning är därför ett ovärderligt verktyg för att effektivisera felsökningen.
Vad innebär loggning?
Loggning är en metod där meddelanden registreras under programmets körning. Det är viktigt att endast logga meddelanden som är relevanta för felsökning. Därför är det avgörande att veta exakt när loggposter ska läggas till i koden och att kunna differentiera dem på ett meningsfullt sätt. Det finns olika loggnivåer, såsom info, varning, fel, felsökning och detaljerad. Fel- och varningsmeddelanden används främst för att hantera undantag.
Data som returneras från funktioner, resultat efter arraymanipulation, information hämtad från API:er, etc., kan med fördel loggas med hjälp av info-satser. Debug- och verbose-loggar ger detaljerade beskrivningar av fel. Felsökningsloggen innehåller information om stackspårning, in- och utdataparametrar, medan verbose-loggen ger en omfattande lista över alla inträffade händelser. Loggarna skrivs ut till konsolen, filer eller utdataströmmar. Logghanteringsverktyg kan användas för att strukturera och formatera loggdata.
Loggning i Node.js
Node.js är en Javascript-runtime-miljö som möjliggör asynkron och icke-blockerande programmering, vilket gör den lämplig för dataintensiva och realtidssystem. För att få en djupare förståelse för Node.js kan man studera tutorials och dokumentation. Loggning är avgörande för att förbättra prestanda, underlätta felsökning och spåra fel. I Node.js kan man använda den inbyggda funktionen `console.log` för loggning. Dessutom finns flera paket tillgängliga som erbjuder mer avancerade loggningsfunktioner.
Middleware används för att hantera förfrågningar och svar och kan vara en applikation eller ett Javascript-ramverk. Loggning med middleware kan ske via applikationer och routrar. För att installera en Node.js-logger krävs kommandot `npm` eller `yarn install`.
Npm (Node Package Manager) och Yarn (Yet Another Resource Negotiator) är pakethanterare. Yarn föredras ofta framför npm eftersom den är snabbare och kan installera paket parallellt.
Nedan följer en lista över några populära loggningsbibliotek för Node.js:
Pino
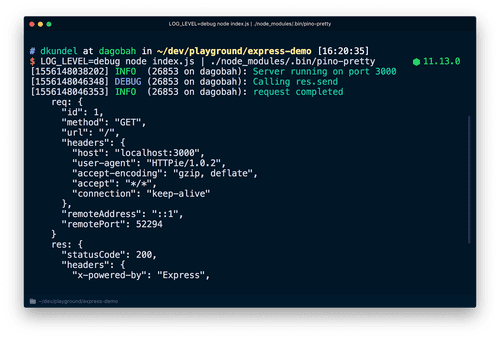
Pino är ett välkänt och snabbt loggningsbibliotek för Node.js-applikationer. Det är öppen källkod och loggar information i ett lättläst JSON-format. Pino erbjuder olika loggnivåer, såsom debug-, varnings-, fel- och infomeddelanden. För att använda Pino importerar man en loggerinstans till projektet och ersätter `console.log`-satser med `logger.info`-satser.

Pino installeras med följande kommando:
$ npm install pino
Loggarna som genereras är utförliga och formaterade i JSON, inklusive radnummer, loggtyp och tidpunkt. Pino minimerar overhead i applikationen och är flexibel vid loggbearbetning. Det kan integreras med webbramverk som Hapi, Restify och Express. Pino-loggar kan också lagras i filer och använder Worker-trådar för drift samt är kompatibelt med TypeScript.
Winston
Winston är ett bibliotek som fokuserar på flexibilitet och utbyggbarhet och erbjuder loggning för olika webbramverk. Det stöder flera typer av transporter, vilket innebär att loggarna kan lagras på olika platser. Transporter är platser där loggmeddelandena lagras.
Winston erbjuder inbyggda transporter som Http, Console, File och Stream samt stöder även andra transporter som Cloud Watch och MongoDB. Loggning sker på olika nivåer och i olika format. Loggningsnivåerna indikerar problemets allvarlighetsgrad.

Följande är Winstons olika loggningsnivåer:
{
error: 0,
warn: 1,
info: 2,
http: 3,
verbose: 4,
debug: 5,
silly: 6
}
Loggutdataformatet kan anpassas, filtreras och kombineras. Loggar inkluderar information om tidsstämpel, etiketter associerade med loggen, millisekunder som förflutit sedan föregående logg, etc. Winston hanterar även undantag och oupptäckta löften. Den erbjuder även funktioner som arkivering av frågekörning, strömmande loggar osv. Installationen av Winston krävs, följt av skapandet av ett Winston-konfigurationsobjekt med en transport för lagring. Slutligen skapas ett loggobjekt med `createLogger()` och loggmeddelanden skickas till detta objekt.
Node-Bunyan
Bunyan används för snabb JSON-loggning i Node.js och tillhandahåller ett kommandoradsgränssnitt (CLI) för att visa loggar. Det är ett lättviktigt verktyg som stöder olika runtime-miljöer som Node.js, Browserify, WebPack och NW.js. Loggarnas JSON-format kan anpassas med hjälp av en ”pretty print”-funktion. Loggarna har olika nivåer som fatal, error, warn, info, debug och trace, var och en med ett tillhörande numeriskt värde.

Alla nivåer som är högre än den inställda nivån loggas. Bunyan stream är platsen där loggarna sparas. Underelement i en applikation kan loggas med `log.child()`. Alla underordnade loggare är kopplade till en specifik överordnad applikation. Strömtypen kan vara en fil, en roterande fil eller rådata, etc. Följande är ett exempel på kod för att definiera en ström:
var bunyan = require('bunyan');
var log = bunyan.createLogger({
name: "foo",
streams: [
{
stream: process.stderr,
level: "debug"
},
...
]
});
Bunyan stöder även DTrace-loggning. DTrace-loggarna inkluderar log-trace, log-warn, log-error, log-info, log-debug och log-fatal. Bunyan använder serializers för att producera loggarna i JSON-format. Serializer-funktioner är robusta och producerar inga undantag.
Loglevel
Loglevel används för loggning i Javascript-applikationer och är ett lättviktigt och enkelt bibliotek. Det loggar data på den valda nivån och använder en enda fil för loggning utan beroenden. Standardloggnivån är ”warn”. Loggutdata är välformaterat och inkluderar radnummer. Några metoder för loggning är trace, debug, warn, error och info.
Loglevel är motståndskraftigt mot fel i olika miljöer. `getLogger()`-metoden används för att hämta ett loggerobjekt. Det kan också kombineras med andra plugins för att utöka funktionaliteten. Några plugins är loglevel-plugin-prefix, loglevel-plugin-remote, ServerSend och DEBUG. Följande kodexempel visar hur man lägger till ett prefix till loggmeddelanden:
var originalFactory = log.methodFactory;
log.methodFactory = function (methodName, logLevel, loggerName) {
var rawMethod = originalFactory(methodName, logLevel, loggerName);
return function (message) {
rawMethod("Newsflash: " + message);
};
};
log.setLevel(log.getLevel()); // Be sure to call setLevel method in order to apply plugin
Byggprocesser körs med kommandot `npm run dist`, och tester körs med `npm test`. Loglevel stöder Webjar-, Bower- och Atmosphere-paket. Nya versioner av Loglevel släpps när nya funktioner har lagts till.
Signale
Signale innehåller 19 loggare för Javascript-applikationer, stöder TypeScript och scoped logging, samt timers som loggar tidsstämpel, data och filnamn. Utöver de 19 inbyggda loggarna (väntar, komplett, dödlig, favorit, info, etc.), kan man skapa anpassade loggar.
Anpassade loggar skapas genom att definiera ett JSON-objekt och fält med loggerdata. Interaktiva loggare kan också skapas, och när en interaktiv logger är aktiverad åsidosätter nya värden de gamla.
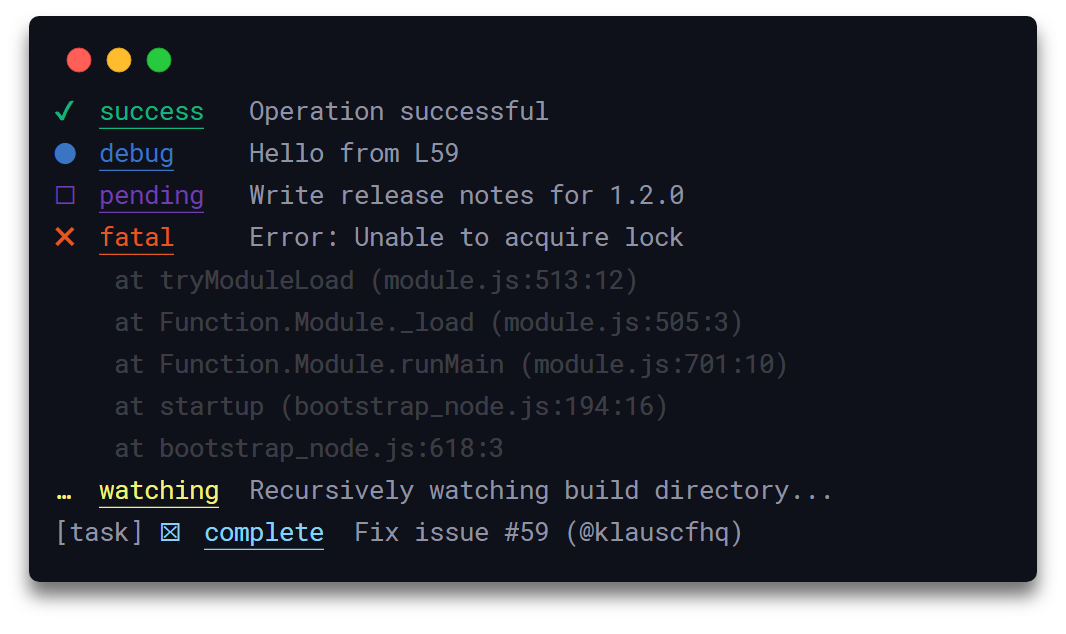
En av de stora fördelarna med Signale är möjligheten att filtrera bort känslig information. Flera hemligheter lagras i en array och kan hanteras med funktionerna `addSecrets()` och `clearSecrets()`. Signale används för loggning i Boostnote, Docz, Shower, Taskbook och Vant. Följande syntax används för att anropa API:er från Signale:
signale.<logger>(message[,message]|messageObj|errorObj)
Antalet Signale-nedladdningar översteg en miljon vid tidpunkten då denna artikel skrevs.
Tracer
Tracer används för att generera detaljerade loggmeddelanden, inklusive tidsstämplar, filnamn, radnummer och metodnamn. Hjälppaket kan installeras för att anpassa loggutdataformatet. Hjälppaketen installeras med följande kommando:
npm install -dev tracer
Tracer stöder fil-, ström- och MongoDB-transporter. Det erbjuder även färgläggning av konsoler och filtrering under loggning. Tracer installeras med npm och därefter skapas ett loggerobjekt där man väljer typ av konsol. Olika loggnivåer eller -typer kan specificeras på objektet för vidare loggning.
Anpassade filter kan skapas genom att definiera synkrona funktioner med specifik affärslogik. Mikromallar som tinytim kan också användas för systemloggning.
Cabin.js
Cabin används för loggning på server- och klientsidan av Node.js-applikationer. Det är särskilt användbart där maskering av känslig information, som kreditkortsnummer, BasicAuth-rubriker, lösenord och bankkontonummer, är nödvändig. Följande kodexempel visar hur loggning utförs med Cabin.js:
const Cabin = require('cabin');
const cabin = new Cabin();
cabin.info('hello world');
cabin.error(new Error('oops!'));
Cabin har över 1600 fältnamn och följer principen ”Bring Your Own Logger” (BYOL), vilket gör det kompatibelt med andra loggare som Axe, Pino, Bunyan, Winston osv. Det minskar lagringskostnader tack vare automatisk streaming och Cabin-buffertar. Det är plattformsoberoende och lätt att felsöka.
Loggning på serversidan kräver användning av middleware för routing och automatisk loggutskrift. Loggning på webbläsarsidan kräver XHR-förfrågningar och skript. Cabin använder Axe som visar metadata, stackspår och felinformation. Variablerna `SHOW_STACK` och `SHOW_META` är booleska och styr visningen av stackspår och metadata.
Npmlog
Npmlog är en grundläggande loggare som npm använder. Några loggningsmetoder är nivå, post, maxRecordSize, prefixStyle, rubrik och ström. Det stöder även färgad loggning. Olika loggnivåer är silly, verbose, info, warn, http och error. Följande kodexempel visar hur man använder npm-loggen:
var log = require('npmlog')
// additional stuff ---------------------------+
// message ----------+ |
// prefix ----+ | |
// level -+ | | |
// v v v v
log.info('fyi', 'I have a kitty cat: %j', myKittyCat)
Alla meddelanden undertrycks om loggnivån är inställd på ”Infinity”. Om loggnivån är ”-Infinity” måste loggmeddelanden vara aktiverade för att se loggarna.
Händelser och meddelandeobjekt används för loggning. Prefixmeddelanden genereras när prefixhändelser används. Stilobjekt används för att formatera loggarna, till exempel genom att lägga till färg på text och bakgrund, eller använda typsnittsstilar som fetstil, kursiv stil och understrykning. Vissa npm-loggpaket är brolog, npmlogger, npmdate-logg, etc.
Roarr
Roarr är en loggare för Node.js som inte kräver initiering och genererar strukturerad data. Den har ett kommandoradsgränssnitt och kan integreras med Fastify, Elastic Search osv. Den kan skilja mellan applikationskod och beroendekod. Varje loggmeddelande består av ett sammanhang, meddelande, sekvens, tid och version. Olika loggnivåer är trace, debug, info, warn, error och fatal. Följande kodexempel visar hur man loggar med Roarr:
import {
ROARR,
} from 'roarr';
ROARR.write = (message) => {
console.log(JSON.parse(message));
};
Fel kan serialiseras, vilket innebär att felets instans kan loggas tillsammans med objektets kontext. Några miljövariabler som är specifika för Node.js och Roarr är ROARR_LOG och ROARR_STREAM. Funktionen ”adoptera” används med Node.js för att överföra kontextegenskaper till olika nivåer. Underordnade funktioner kan också användas med middleware under loggning.
Slutord
Loggning är en viktig metod för att spåra aktiviteter och händelser under körning av ett program. Loggning underlättar felsökningen av kod och förbättrar läsbarheten. Node.js är en öppen källkod Javascript-runtime-miljö. Några av de populäraste loggarna för Node.js är Pino, Winston, Bunyan, Signale, Tracer och Npmlog. Varje loggningsverktyg har egna funktioner som profilering, filtrering, strömning och transport.
Vissa loggare stöder färgade konsoler, och andra är mer lämpade för att hantera känslig information. Detaljerad och formaterad loggning är till stor hjälp för utvecklare som felsöker sin kod. JSON-format är ofta att föredra för loggning eftersom det lagrar data som nyckel-värdepar, vilket gör det mer användarvänligt.
Loggare kan integreras med andra applikationer och är kompatibla med flera webbläsare. Det rekommenderas att utvärdera de specifika kraven och behoven hos din applikation innan du väljer vilken typ av loggningsverktyg du ska använda.
Du kan också undersöka hur du installerar Node.js och NPM på Windows och macOS.