Övergången till serverlös arkitektur: En ny era för mjukvaruutveckling
Under en längre tid krävde konstruktionen av automatiserade mjukvarusystem att flera servrar installerades med specifik CPU-konfiguration, minne, lagring och andra resurser. Detta ledde till att specialiserade administrationsteam bildades för att övervaka och underhålla dessa system. Senare tog utvecklingsteamen över ansvaret för infrastrukturen och inledde processer för att sammanlänka servrarna.
Denna process kunde vara komplex och involverade många team med gemensamma mål, vilket ibland ledde till intressekonflikter.
Dessutom var detta ofta en kostsam lösning. Företag behövde anställa administratörer och de ständigt aktiva servrarna förbrukade resurser även när de inte användes aktivt.
För att bibehålla hög prestanda över tid behövdes en lösning för automatisk skalning, som självständigt kunde anpassa serverresurserna efter behov.
Molnplattformar erbjuder en fördelaktig lösning genom att möjliggöra skapandet av en komplett arkitektur utan behov av att konfigurera serverkluster. Ur ett förvaltningsperspektiv minskar detta underhållsbyrån avsevärt.
Detta är ett kostnadseffektivt alternativ för startups och under de initiala faserna av MVP (Minimum Viable Product) i projekt. Det är en bra utgångspunkt när det är svårt att förutse framtida produktionsbelastningar och användaraktivitet, vilket kan göra det svårt att bestämma rätt konfiguration för klusterservrar.
Automatiseringen av processer via serverlösa molntjänster är en central egenskap hos serverlös arkitektur. Den skapar kopplingar mellan tjänster och levererar resultat som liknar de från traditionella klusterservrar.
Nedan följer ett exempel på hur en sådan arkitektur kan skapas med hjälp av inbyggda AWS-tjänster.
Serverlöst flöde: Att välja tjänsterna
Låt oss säga att du vill skapa en plattform för att samla in data och bilder (eller foton) av specifik infrastruktur (oavsett om det rör sig om tillverknings- eller nyttotillgångar).
- För att möjliggöra framtida analyser måste den inkommande datan först bearbetas och lagras.
- Efter tillämpning av affärsregler sparar en backend-process den bearbetade informationen som normaliserad data i en relationsdatabas.
- Ett användargränssnitt visar sedan den normaliserade och bearbetade informationen för användarna.
Låt oss granska de komponenter som en sådan arkitektur kan inkludera.
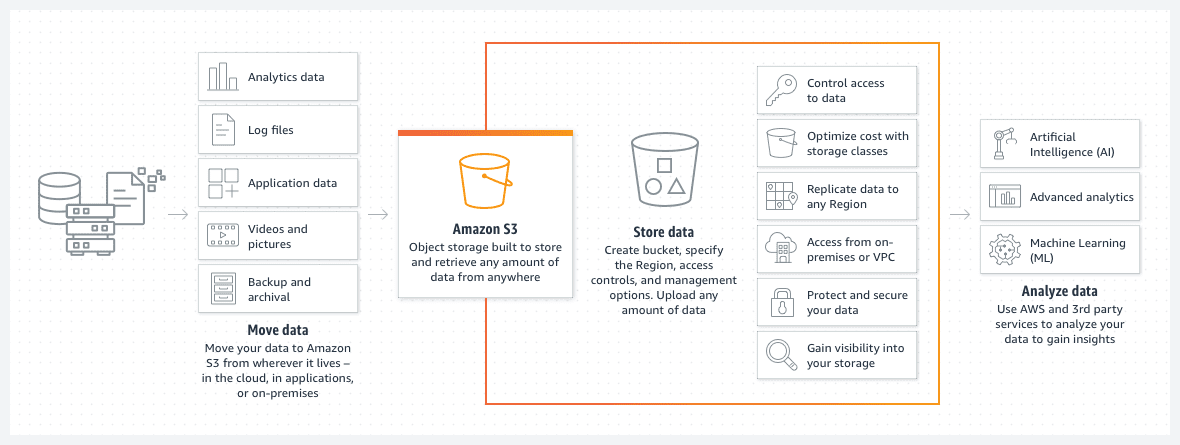
AWS S3-lagringsutrymmen
 Källa: aws.amazon.com
Källa: aws.amazon.com
Amazon S3-lagringsutrymmen är en utmärkt metod för att lagra filer eller bilder i AWS-molnet. Lagringskostnaderna i S3-lagringsutrymmen är generellt sett låga och kan minskas ytterligare genom att implementera en livscykelpolicy för S3-lagringsutrymmet.
En sådan policy flyttar automatiskt äldre filer till olika lagringsklasser inom S3, som arkiv eller djuparkiv. Dessa klasser skiljer sig åt i åtkomsthastighet, men för äldre data är detta ofta ett mindre problem. Arkiverad data är i första hand avsedd för åtkomst i brådskande situationer, snarare än för regelbunden drift.
- Du kan organisera din data i undermappar.
- Det är viktigt att ange lämpliga behörighetsbegränsningar.
- Lägg till taggar i segmenten för att underlätta identifiering och dynamisk hantering genom S3-segmentpolicyer.
- Lagringsutrymmet är serverlöst till sin design och fungerar enbart som lagringsplats för dina data.
En S3-lagringsplats är serverlös och fungerar uteslutande som ett lagringsutrymme för dina data.
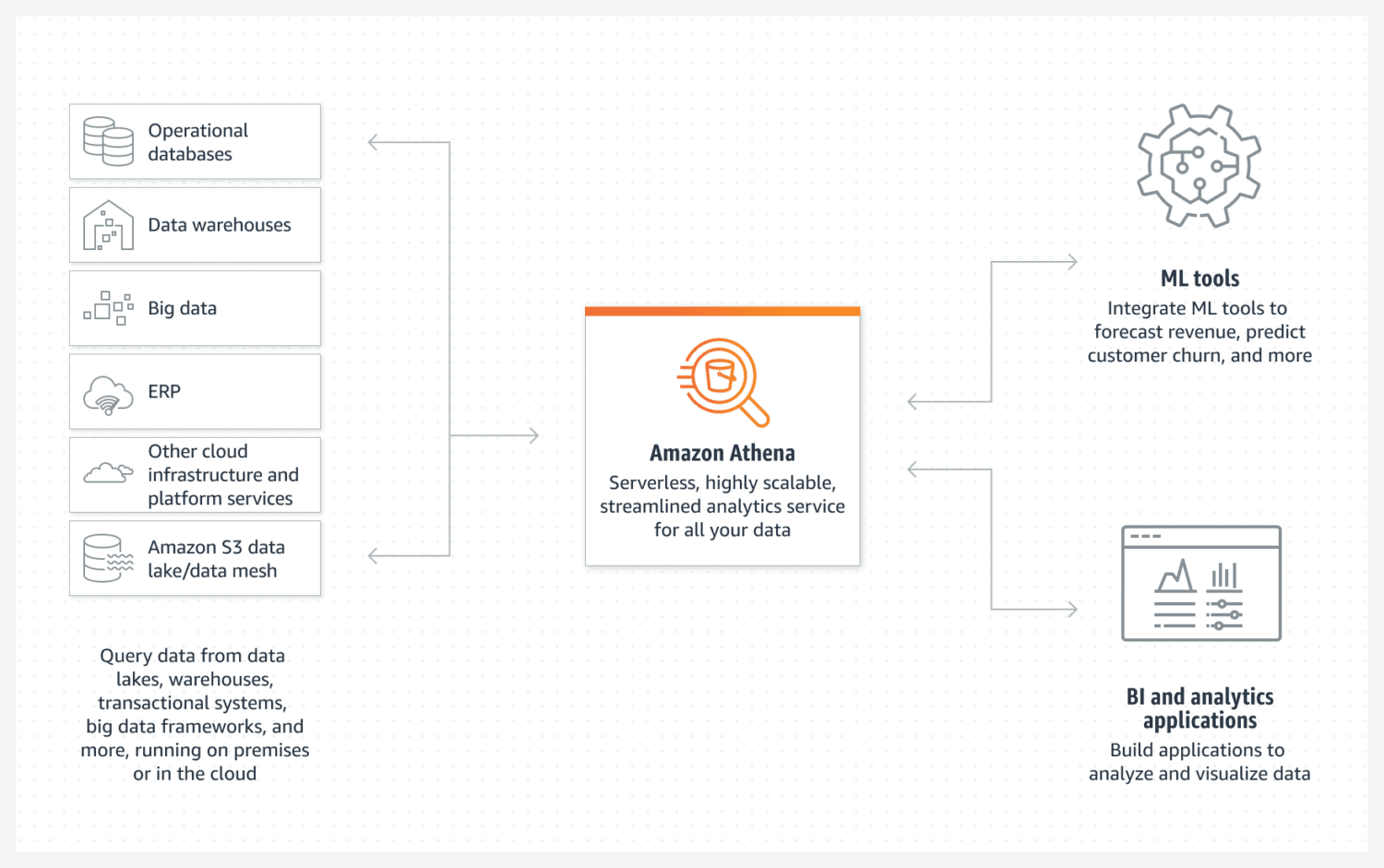
AWS Athena-databas
 Källa: aws.amazon.com
Källa: aws.amazon.com
Athena förenklar skapandet av en AWS-baserad datasjö. Det är en serverlös databas som använder S3-lagringsutrymmen för att lagra data. Dataorganisationen upprätthålls genom strukturerade filformat, som parkett eller CSV (kommaseparerade värden). S3-lagringsutrymmet innehåller filerna, och Athena hänvisar till dessa filer när data selekteras från databasen.
Det är viktigt att notera att Athena inte stödjer alla funktioner som brukar anses vara standard, som till exempel uppdateringssatser. Athena bör därför ses som ett relativt enkelt alternativ.
Däremot har det stöd för indexering och partitionering. Det kan även skalas horisontellt på ett smidigt sätt, vilket i praktiken innebär att lägga till fler lagringsutrymmen till infrastrukturen. Detta kan vara tillräckligt för de flesta fall där man behöver en enkel men funktionell datasjö.
För att uppnå optimal prestanda är det viktigt att utforma datastrukturen med fokus på framtida användning. Det är viktigt att ha en tydlig bild av hur data kommer att selekteras, eftersom det kan vara svårt att återskapa tabeller när de redan är fyllda med stora mängder data.
Athena är ett utmärkt val om du vill skapa en enkel och oföränderlig datapool som enkelt kan skalas horisontellt över tid.
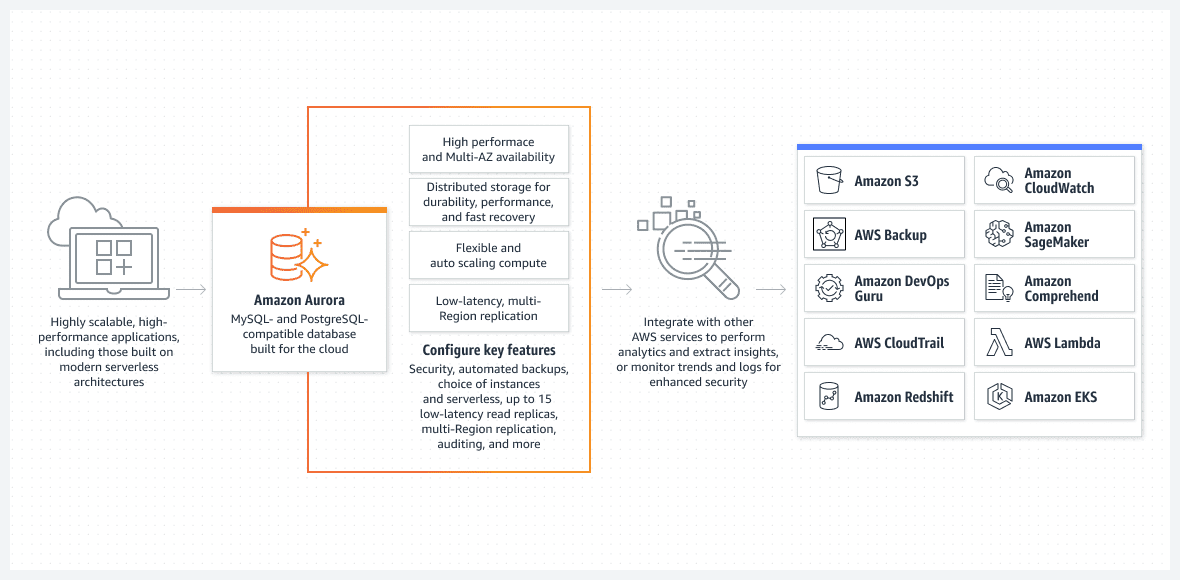
AWS Aurora-databas
 Källa: aws.amazon.com
Källa: aws.amazon.com
Athena DB är utmärkt för att lagra obearbetad data. Detta är lämpligt för att maximera återanvändningen av originalinnehållet. Däremot kan det vara långsamt att leverera selekterade resultat till en frontend-app.
Aurora-databasen, som kan köras i serverlöst läge, är ett av de bästa alternativen för enkel installation.
Aurora är en avancerad relationsdatabaslösning i AWS och den utvecklas kontinuerligt.
Aurora är unik eftersom den kan köras i serverlöst läge, vilket skiljer den från andra relationstjänster. Så här fungerar serverlöst läge:
- Aurora-klustret konfigureras via AWS-konsolen. Du måste ange standardnivåer för CPU och RAM samt det maximala intervallet för automatisk skalning. Dessa inställningar påverkar Aurora-klustrets kapacitet att dynamiskt lägga till eller ta bort resurser. AWS beslutar om att skala upp eller ner baserat på databasens nuvarande användning.
- Aurora-klustret startar enbart när användaren eller en process skickar en faktisk förfrågan. Exempelvis kan detta ske när schemalagd batchbearbetning startar, eller när applikationen gör ett backend-API-anrop för att hämta data från databasen. Databasen öppnas automatiskt och förblir aktiv under en viss period efter att begäran slutförts.
- Aurora-klustret stängs automatiskt ned om ingen aktivitet sker i databasen.
Det är värt att betona att serverlös Aurora DB endast körs när den behöver utföra faktiska uppgifter. Det automatiskt startade klustret stängs ned igen om ingen aktivitet sker. Du betalar enbart för den tid databasen faktiskt är aktiv.
Den serverlösa Aurora-databasen hanteras helt av AWS och kräver ingen administratör.
AWS Amplify
Amplify är en serverlös plattform som möjliggör snabb distribution av frontend-applikationer byggda med JavaScript och React-bibliotek. Det finns inget behov av att konfigurera klusterservrar. Koden kan distribueras direkt via AWS-konsolen eller med en automatiserad DevOps-pipeline.
Backend-API:er kan anropas för att komma åt data i databaserna. Genom dessa anrop kan man nå den faktiska datan i frontend-applikationen. Huvudansvaret för backend-prestanda ligger hos utvecklingsteamet. Genom att skapa effektiva urvalssatser direkt i API-anropen kan du minimera risken för långsam respons i användargränssnittet.
AWS Step Functions
 Källa: aws.amazon.com
Källa: aws.amazon.com
Även om alla huvudkomponenter i ett system är serverlösa, innebär inte detta nödvändigtvis en helt serverlös arkitektur. Detta är endast möjligt om alla batchprocesser mellan komponenterna är serverlösa.
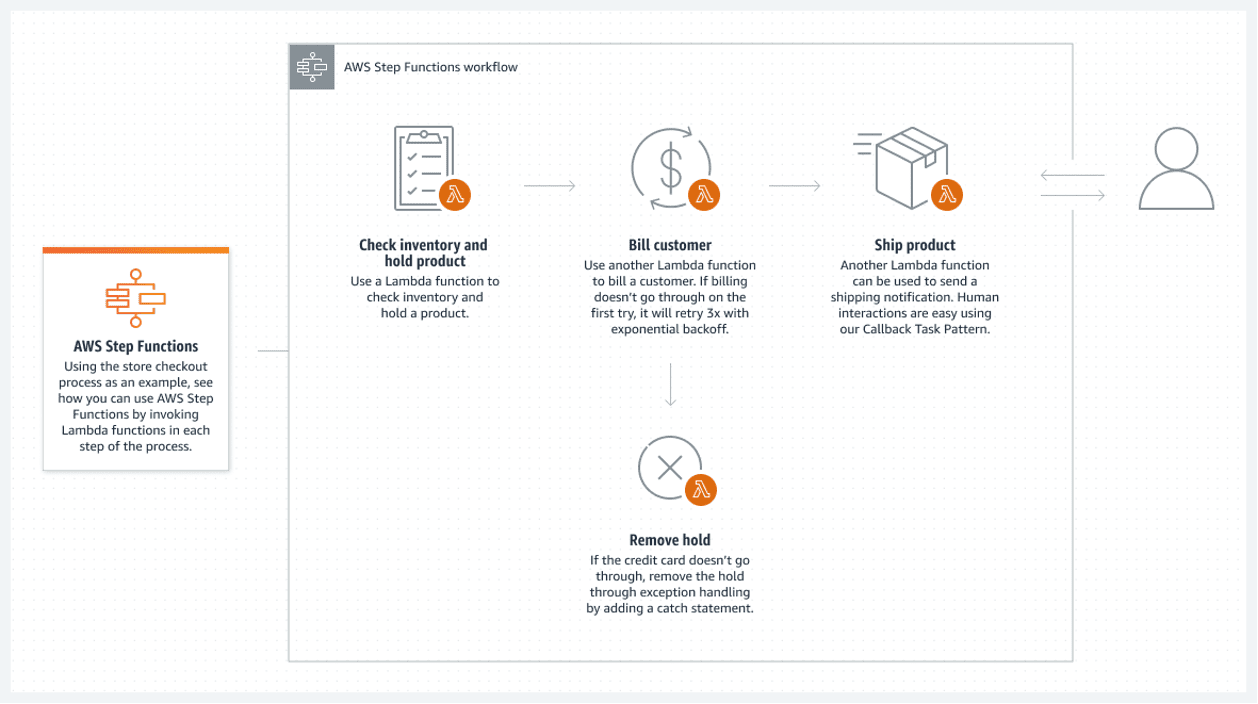
AWS Step Functions erbjuder en optimal lösning inom AWS-molnet. En ansluten lista av AWS Lambda-funktioner utgör en stegfunktion. Dessa funktioner skapar ett flödesschema med tydliga start- och sluttillstånd. En lambda-funktion, vanligen skriven i Python eller Node JS, är en körbar kodbit som bearbetar det som krävs.
Följande är ett exempel på hur en stegfunktion kan utföras:
Detta serverlösa flöde har en stor nackdel: varje lambdafunktion kan endast köras i maximalt 15 minuter. Genom att dela upp flödet i mindre lambdafunktioner kan detta problem minimeras.
Det är möjligt att anropa flera lambdafunktioner samtidigt i ett steg, vilket i praktiken innebär att man kan parallellisera ett steg med flera lambda som körs simultant. Man måste dock vänta tills all parallell lambda-bearbetning är färdig innan man fortsätter till nästa lambda-bearbetning.
Sammanfattning
Serverlös arkitektur erbjuder en unik möjlighet att skapa en molnplattform som täcker hela systemlandskapet. Denna plattform är horisontellt skalbar och erbjuder låga driftskostnader.
Detta är en idealisk lösning för projekt med en begränsad budget och ett utmärkt alternativ när produktionsbelastningen inte är känd i förväg. Detta är särskilt viktigt efter att man har fått tillgång till alla användare. Trots detta kan projektteamen få en helhetsbild av hur systemet fungerar utan att behöva kompromissa.
Denna lösning är dock inte tillämplig för alla användningsfall, speciellt inte de som kräver hög CPU-användning. AWS-molnet utvecklas kontinuerligt när det gäller serverlösa användningsfall. Det är viktigt att göra grundlig research innan man bestämmer sig för ett serverlöst alternativ för sitt nästa AWS-molnprojekt.
Du kan ta del av mer information om de bästa serverlösa databaserna för moderna applikationer här.