Dataanalys är en fascinerande disciplin för alla som uppskattar att lösa komplexa problem och finna värdefulla insikter i till synes röriga datamängder.
Det kan liknas vid att söka efter en nål i en höstack, men dataanalytiker slipper smutsa ner sina händer. Med hjälp av avancerade verktyg och färgstarka visualiseringar dyker de ner i informationshögarna och extraherar värdefulla insikter som kan generera stort affärsvärde.
En typisk dataanalytikers verktygslåda bör omfatta minst en komponent från följande kategorier: relationsdatabaser, NoSQL-databaser, ramverk för stordata, visualiseringsverktyg, skrapverktyg, programmeringsspråk, IDE:er och verktyg för djupinlärning.
Relationsdatabaser
En relationsdatabas är organiserad i tabeller med attribut och kopplade relationer som definierar en datamodell. För att hantera data i relationsdatabaser används SQL (Structured Query Language).
Applikationer som hanterar strukturen och datan i dessa databaser kallas RDBMS (Relational DataBase Management Systems). Många sådana system finns, och de mest relevanta har nyligen fokuserat på dataanalys, med stöd för stordata och tekniker som dataanalys och maskininlärning.
SQL Server
Microsofts RDBMS har utvecklats kontinuerligt under över 20 år. Sedan 2016 erbjuder SQL Server en rad tjänster, inklusive stöd för inbäddad R-kod. SQL Server 2017 utvecklar detta genom att omdöpa R-tjänster till Machine Language Services och lägga till stöd för Python (mer om dessa språk nedan).
Dessa viktiga tillägg gör SQL Server mer tillgängligt för dataanalytiker, även de utan erfarenhet av Transact SQL, Microsoft SQL Servers egna frågespråk.
SQL Server är en kommersiell produkt. Licenser kan köpas för installation på en Windows-server (priset varierar beroende på antalet samtidiga användare) eller användas som en betaltjänst via Microsoft Azure-molnet. Microsoft SQL Server är lätt att lära sig.
MySQL
På open source-sidan är MySQL en mycket populär RDBMS. Trots att det ägs av Oracle, är det fortfarande gratis och öppen källkod under en GNU General Public License. Många webbapplikationer använder MySQL för sin datalagring, mycket tack vare dess överensstämmelse med SQL-standarden.
MySQL är populärt även tack vare enkel installation, ett stort utvecklarsamhälle, omfattande dokumentation och tredjepartsverktyg som phpMyAdmin, som underlättar den dagliga hanteringen. Även om MySQL inte har inbyggda funktioner för dataanalys, gör dess öppenhet det möjligt att integrera med nästan alla visualiserings-, rapporterings- och business intelligence-verktyg.
PostgreSQL
Ett annat RDBMS-alternativ med öppen källkod är PostgreSQL. Även om det inte är lika populärt som MySQL, är PostgreSQL känt för sin flexibilitet och utökbarhet, och sitt stöd för komplexa SQL-frågor som går utöver grundläggande SELECT-, WHERE- och GROUP BY-satser.
Dessa funktioner gör det populärt bland dataforskare. Ytterligare en fördel är dess stöd för hybridmolnmiljöer.
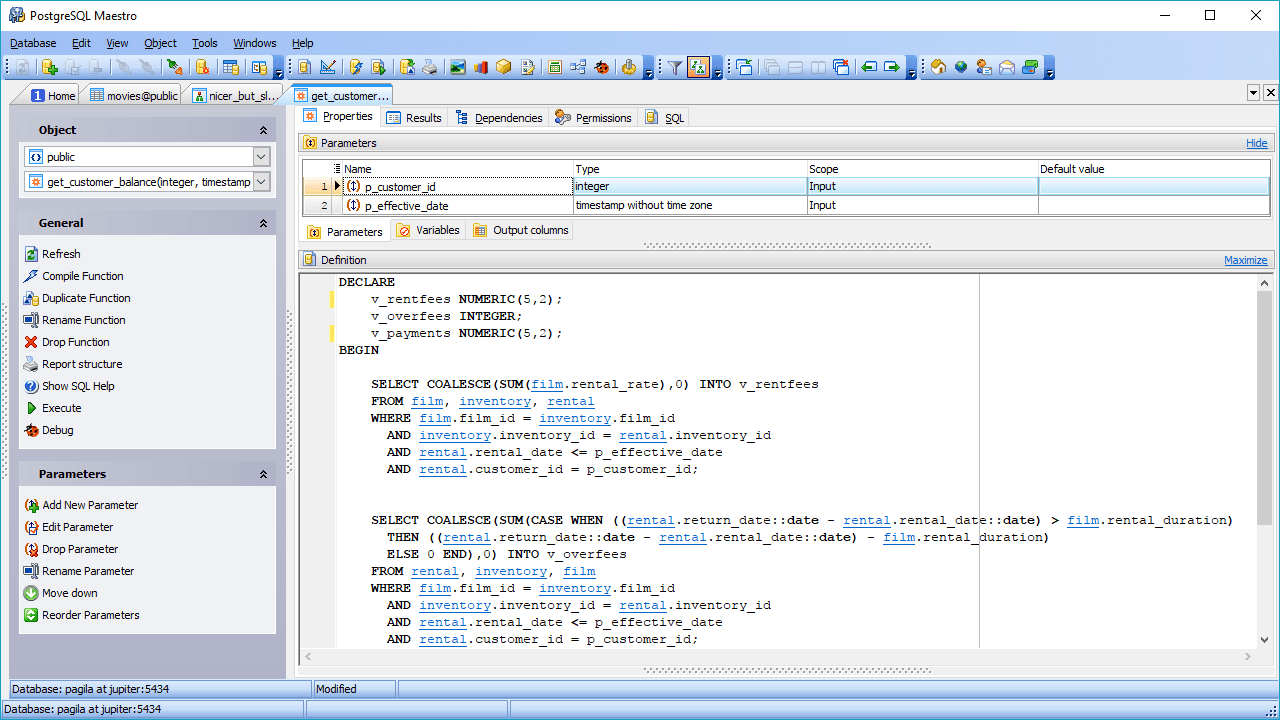
PostgreSQL kan kombinera online analytisk bearbetning (OLAP) med online transaktionsbearbetning (OLTP) och fungerar i ett läge som kallas hybrid transaktionell/analytisk bearbetning (HTAP). Det är också väl lämpat för stordata tack vare tillägget av PostGIS för geografisk data och JSON-B för dokument. PostgreSQL stödjer även ostrukturerad data, vilket gör att det kan användas för både SQL och NoSQL-databaser.
NoSQL-databaser
NoSQL-databaser, även kallade icke-relationella databaser, ger snabbare åtkomst till icke-tabellbaserad data. Exempel på detta är grafer, dokument, breda kolumner, nyckelvärden och mycket annat. NoSQL-datalager kan prioritera andra fördelar, som tillgänglighet och hastighet, framför datakonsistens.
Eftersom det inte finns någon SQL i NoSQL-databaser, kan de enbart frågas med hjälp av lågnivåspråk. Det finns inget universellt språk för NoSQL, och det finns heller inga standarder för dessa databaser. Det är därför som vissa NoSQL-databaser ironiskt nog har börjat stödja SQL.
MongoDB
MongoDB är ett populärt NoSQL-databassystem som lagrar data i JSON-dokument. Dess fokus ligger på skalbarhet och flexibilitet för ostrukturerad data, vilket betyder att det inte finns någon fast fältlista som måste följas för varje lagrat element. Data strukturen kan även ändras över tid, något som i relationsdatabaser innebär en stor risk för applikationer som körs.

MongoDB:s teknologi erbjuder indexering, ad-hoc-frågor och aggregering, vilket skapar en bra grund för dataanalys. Databasens distribuerade karaktär ger hög tillgänglighet och geografisk distribution utan sofistikerade verktyg.
Redis
Redis är ett annat open source-alternativ inom NoSQL. Det är en datastrukturlagring som arbetar i minnet och som förutom att tillhandahålla databastjänster fungerar som cacheminne och meddelandehanterare.

Redis stödjer en mängd olika datastrukturer som hash, geospatiala index, listor och sorterade uppsättningar. Det är väl lämpat för dataanalys på grund av sin höga prestanda i dataintensiva uppgifter, som att beräkna korsningar, sortera långa listor eller generera komplexa rankningar. Anledningen till Redis höga prestanda är dess in-memory-drift. Den kan konfigureras för att bevara data selektivt.
Big Data-ramverk
Tänk dig att du ska analysera data som genereras av Facebook-användare under en månad – foton, videor, meddelanden – allt. Med tanke på att mer än 500 terabyte data läggs till varje dag, är det svårt att föreställa sig volymen som representeras av en hel månad.
För att hantera så enorma datamängder effektivt behövs ett lämpligt ramverk som kan beräkna statistik i en distribuerad arkitektur. Det finns två ramverk som är marknadsledande: Hadoop och Spark.
Hadoop
Hadoop är ett ramverk för stordata som hanterar komplexiteten i att hämta, bearbeta och lagra stora datamängder. Hadoop arbetar i en distribuerad miljö bestående av datorkluster som kör enkla algoritmer. En orkestreringsalgoritm, kallad MapReduce, delar upp stora uppgifter i små delar och distribuerar dessa små uppgifter mellan tillgängliga kluster.

Hadoop är lämpligt för datalager som kräver snabb åtkomst, hög tillgänglighet och kostnadseffektivitet. Men det kräver en Linux-administratör med djup Hadoop-kunskap för att underhålla och driva ramverket.
Spark
Hadoop är inte det enda ramverket för stordatahantering. Ett annat stort namn är Spark. Spark utvecklades för att överträffa Hadoop i analyshastighet och användarvänlighet. Spark är betydligt snabbare än Hadoop, med en hastighet på upp till 10 gånger snabbare på disk och 100 gånger snabbare i minnet. Dessutom kräver det färre maskiner för att hantera samma datamängd.

Utöver hastighet erbjuder Spark även stöd för strömningsbearbetning, eller realtidsbearbetning, som innebär kontinuerlig inmatning och utmatning av data.
Visualiseringsverktyg
Det finns ett skämt bland dataanalytiker att om man ”tortyrerar” data tillräckligt länge, kommer den att avslöja vad du behöver veta. ”Tortyr” i detta fall betyder att manipulera data genom att transformera och filtrera den, för att sedan kunna visualisera den bättre. Det är här visualiseringsverktyg kommer in i bilden. Dessa verktyg tar förbehandlad data från olika källor och visar de dolda insikterna i grafisk form.
Det finns hundratals visualiseringsverktyg. Det mest använda är fortfarande Microsoft Excel och dess diagramfunktion. Excel-diagram är tillgängliga för alla som använder Excel, men deras funktionalitet är begränsad. Detsamma gäller andra kalkylarksprogram som Google Sheets och Libre Office. Men här talar vi om mer specialiserade verktyg för business intelligence (BI) och dataanalys.
Power BI
Microsoft lanserade Power BI, en visualiseringsapplikation som kan ta data från olika källor, som textfiler, databaser, kalkylark och onlinetjänster, inklusive Facebook och Twitter, och använda den för att skapa instrumentpaneler fyllda med diagram, tabeller och kartor. Instrumentpanelsobjekten är interaktiva och gör det möjligt att klicka på en dataserie för att använda den som filter för andra objekt på panelen.
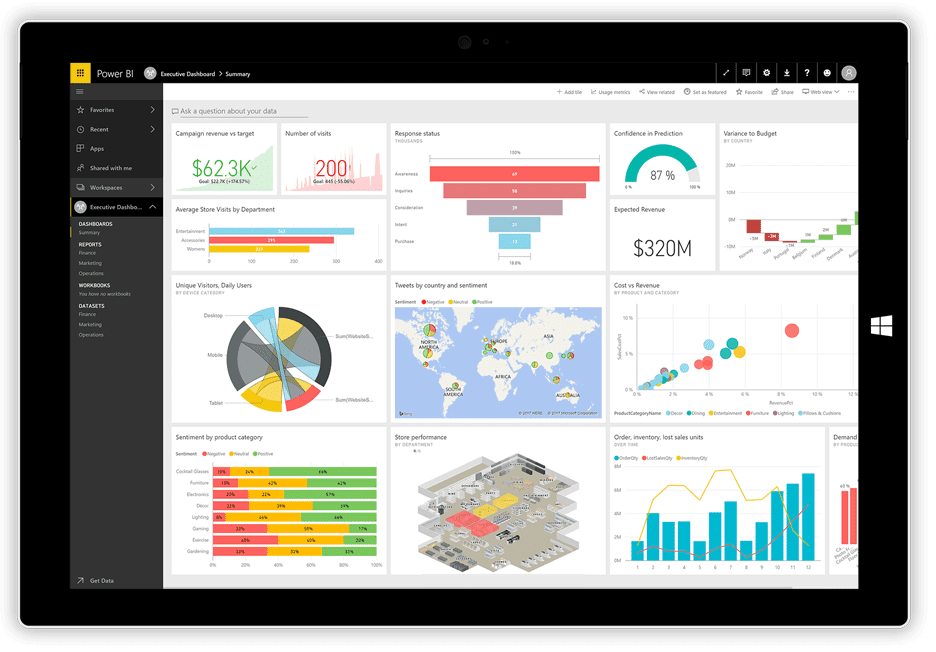
Power BI är en kombination av en Windows-app (en del av Office 365-sviten), en webbapp och en onlinetjänst för publicering och delning av instrumentpaneler. Tjänsten gör det möjligt att skapa och hantera behörigheter för att styra vem som kan se instrumentpanelerna.
Tableau
Tableau är ett annat alternativ för att skapa interaktiva instrumentpaneler. Det erbjuder en skrivbordsversion, en webbversion och en onlinetjänst för att dela instrumentpaneler. Tableau ska fungera ”naturligt med hur du tänker” och är lätt att använda även för icke-tekniska personer, tack vare många handledningar och onlinevideor.
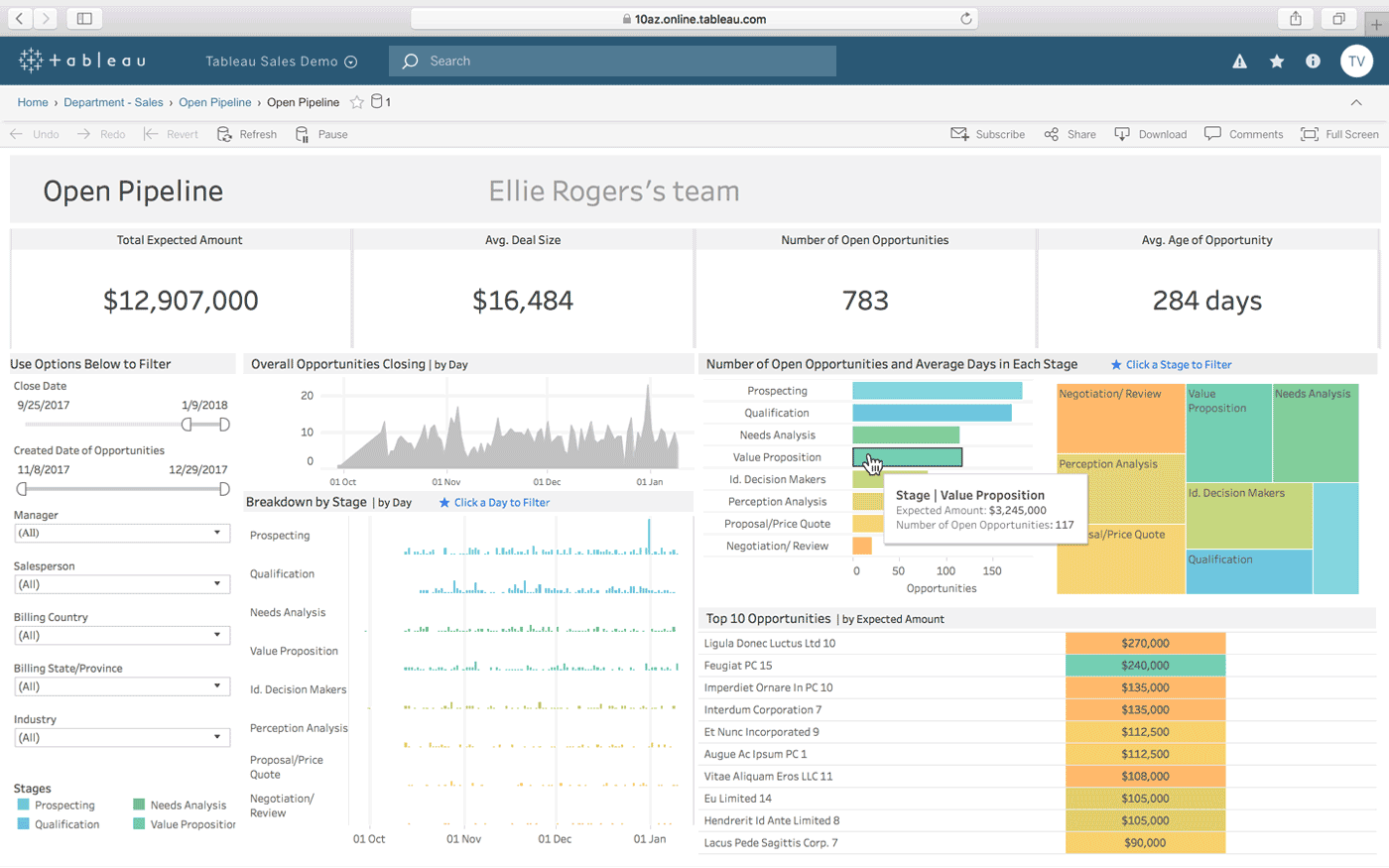
Några av Tableaus mest framstående funktioner är dess obegränsade dataanslutningar, möjligheten att arbeta med både livedata och in-memory-data, samt dess mobiloptimerade design.
QlikView
QlikView har ett rent och enkelt användargränssnitt som hjälper analytiker att upptäcka insikter genom lättförståeliga visuella element.
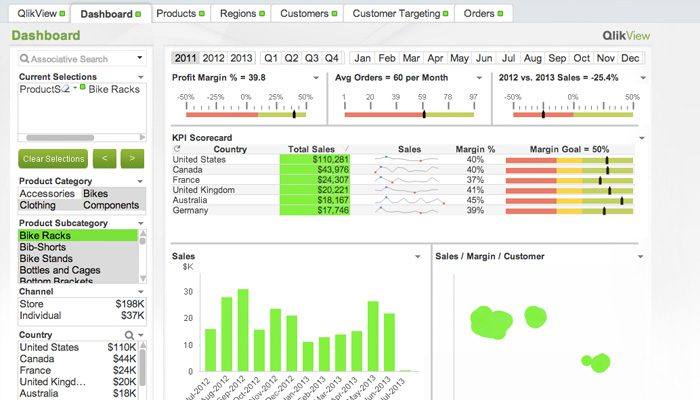
QlikView är känt som en flexibel business intelligence-plattform. Det tillhandahåller en funktion som heter Associative Search som hjälper dig att fokusera på de viktigaste uppgifterna.
Med QlikView kan du samarbeta med andra i realtid och genomföra jämförande analyser. All relevant data kan kombineras till en app, med säkerhetsfunktioner som begränsar åtkomsten till datan.
Skrapverktyg
I internets barndom började sökmotorer att ”crawla” nätverket och samla in information. Med tiden utvecklades tekniken och termen webbcrawling ersattes av webbskrapning, men betydelsen är fortfarande densamma: att automatiskt extrahera information från webbplatser. Webbskrapning använder automatiserade processer, eller bots, som hoppar från webbsida till webbsida, extraherar data och exporterar den i olika format, eller infogar den i databaser för vidare analys.
Nedan följer en sammanfattning av tre populära webbskrapverktyg.
Octoparse
Octoparse webbskrapa har intressanta funktioner, inklusive verktyg för att hämta information från webbplatser som inte är lätta för skrapbots. Det är en skrivbordsapplikation som inte kräver någon kodning, med ett användarvänligt gränssnitt som möjliggör visualisering av utvinningsprocessen genom en grafisk arbetsflödesdesigner.
Tillsammans med den fristående applikationen, erbjuder Octoparse en molnbaserad tjänst som påskyndar datautvinningsprocessen med 4-10 gånger jämfört med skrivbordsapplikationen. Skrivbordsversionen av Octoparse är gratis, medan molntjänsten är en betaltjänst.
Content Grabber
Om du letar efter ett skrapverktyg med många funktioner, bör du titta närmare på Content Grabber. Till skillnad från Octoparse kräver Content Grabber avancerad programmeringskunskap. I utbyte får du skriptredigering, felsökningsgränssnitt och andra avancerade funktioner. Med Content Grabber kan du använda .Net-språk för att skriva reguljära uttryck.
Verktyget erbjuder ett API (Application Programming Interface) som gör det möjligt att lägga till skrapfunktioner till dina skrivbords- och webbapplikationer. Utvecklare behöver tillgång till Content Grabber Windows-tjänsten för att kunna använda API:et.
ParseHub
Denna skrapa kan hantera en mängd olika typer av innehåll, som forum, kommentarer, kalendrar och kartor. Den hanterar även sidor med autentisering, Javascript och Ajax. ParseHub kan användas som en webbapp eller ett skrivbordsprogram som kan köras på Windows, macOS och Linux.
Liksom Content Grabber rekommenderas viss programmeringskunskap för att få ut det mesta av ParseHub. Det finns en gratisversion, begränsad till 5 projekt och 200 sidor per körning.
Programmeringsspråk
Precis som SQL är utformat för att fungera med relationsdatabaser, finns det andra språk som är speciellt skapade för dataanalys. Dessa språk ger utvecklare möjlighet att skriva program för att hantera omfattande dataanalyser, inklusive statistik och maskininlärning.
SQL anses också vara en viktig färdighet för dataanalytiker, eftersom många organisationer fortfarande lagrar data i relationsdatabaser. ”Riktiga” dataanalysspråk är R och Python.
Python

Python är ett högnivå, tolkat, allmänt programmeringsspråk, lämpligt för snabb applikationsutveckling. Det har en enkel syntax som möjliggör en brant inlärningskurva och lägre kostnader för programunderhåll. Det finns många anledningar till att det är det föredragna språket för dataanalys: skriptpotential, tydlighet, portabilitet och prestanda.
Det här språket är en bra startpunkt för dataanalytiker som planerar att experimentera mycket innan de börjar med den tuffa datahanteringen, och för de som vill utveckla kompletta applikationer.
R
R-språket används främst för statistisk databehandling och diagram. Även om det inte är avsett för att utveckla fullfjädrade applikationer, har R blivit populärt på senare år för sin potential inom datautvinning och dataanalys.

Tack vare ett ständigt växande bibliotek av fritt tillgängliga paket som utökar dess funktionalitet, kan R utföra olika dataanalysuppgifter, inklusive linjär/icke-linjär modellering, klassificering, statistiska tester osv.
Det är inte ett enkelt språk att lära sig, men när du väl har vant dig vid det, kommer du att kunna utföra statistiska beräkningar som ett proffs.
IDE:er
Om du seriöst funderar på att arbeta med dataanalys, måste du noggrant välja en integrerad utvecklingsmiljö (IDE) som passar dina behov, eftersom du och din IDE kommer att arbeta mycket tillsammans.
En ideal IDE bör samla alla de verktyg du behöver i ditt dagliga arbete som kodare: en textredigerare med syntaxmarkering och autokomplettering, en kraftfull felsökare, en objektläsare och enkel åtkomst till externa verktyg. Dessutom måste den vara kompatibel med det språk du föredrar, så det är en bra idé att välja IDE efter att ha bestämt vilket språk du kommer att använda.
Spyder
Denna generiska IDE är främst avsedd för forskare och analytiker som också behöver koda. Den fokuserar inte enbart på IDE-funktioner utan ger också verktyg för datautforskning/visualisering och interaktiv körning, som man kan hitta i ett vetenskapligt paket. Redigeraren i Spyder har stöd för flera språk och klasswebbläsare, fönsterdelning, hopp till definition, autokomplettering och till och med ett verktyg för kodanalys.
Felsökaren hjälper dig att spåra varje kodrad interaktivt, och en profilerare hjälper dig att hitta och eliminera ineffektivitet.
PyCharm
Om du programmerar i Python är chansen stor att din IDE blir PyCharm. Den har en smart kodredigerare med smart sökning, kodkomplettering samt felidentifiering och -rättning. Med ett enda klick kan du hoppa från kodredigeraren till ett valfritt kontextrelaterat fönster, som tester, supermetoder, implementeringar och deklarationer. PyCharm stödjer Anaconda och många vetenskapliga paket som NumPy och Matplotlib.
PyCharm erbjuder integration med de viktigaste versionskontrollsystemen samt med en testkörare, en profilerare och en felsökare. Dessutom integreras den även med Docker och Vagrant, för plattformsoberoende utveckling och containerisering.
RStudio
För dataanalytiker som föredrar R, bör IDE-valet vara RStudio, på grund av dess många funktioner. Du kan installera det på Windows, macOS eller Linux, eller så kan du köra det från en webbläsare om du inte vill installera det lokalt. Båda versionerna erbjuder godbitar som syntaxmarkering, smart indrag och kodkomplettering. Det finns en integrerad datavisning som är praktisk när du behöver visa tabelldata.
Felsökningsläget gör det möjligt att se hur data uppdateras dynamiskt när ett program eller skript körs steg för steg. För versionshantering integrerar RStudio med SVN och Git. En trevlig bonus är möjligheten att skapa interaktiv grafik med Shiny och ger-bibliotek.
Din personliga verktygslåda
Nu har du förhoppningsvis en klar bild av de verktyg du behöver känna till för att lyckas med dataanalys. Vi hoppas också att vi har gett dig tillräckligt med information för att bestämma vilket som är det mest praktiska alternativet inom varje verktygskategori. Nu är det upp till dig. Dataanalys är ett blomstrande område för att utveckla en karriär. Men om du vill lyckas måste du hålla jämna steg med de förändringar som sker inom trender och teknik, eftersom de uppkommer nästan dagligen.