Vår värld är i grunden datadriven. Genom att erhålla kraftfulla realtidsinsikter från faktisk data kan ditt företag skapa en konkurrensfördel. Dataströmningsprocesser möjliggör kontinuerlig insamling och bearbetning av information från diverse källor, vilket gör att plattformar för dataströmmar är av avgörande betydelse.
Plattformar för dataströmmar är konstruerade som skalbara, distribuerade och högpresterande system, vilket garanterar att dataströmmar behandlas på ett tillförlitligt sätt. De stödjer dataaggregering och analys, ofta levererat med en centraliserad instrumentpanel för datavisualisering.
Det finns ett brett urval av plattformar och metoder för dataströmmar – från fullständigt hanterade system som Confluent Cloud och Amazon Kinesis till öppen källkodslösningar som Arroyo och Fluvio.
Vilka är några exempel på användningsområden för dataströmmar?
Plattformar för dataströmmar täcker en rad användningsfall. Här följer en snabb översikt av några av dem:
- Identifiering av bedrägerier genom kontinuerlig analys av transaktioner, användarbeteende och mönster.
- Aktiemarknadsdata som fångas in av flera system för att möjliggöra snabba högvolymstransaktioner baserade på marknadsanalys.
- Anpassade insikter som erhålls genom marknadsdata i realtid, vilket hjälper e-handelsplattformar att rikta sina produkter till rätt målgrupper.
- En mängd sensorer i olika system genererar realtidsdata som bidrar till förutsägbar information, som till exempel väderprognoser.
Här presenteras de bästa dataplattformarna som täcker alla dina behov av realtidsanalys och databehandling.
Confluent Cloud
Confluent Cloud, en fullständig molnbaserad tjänst baserad på Apache Kafka, erbjuder motståndskraft, skalbarhet och hög prestanda. Den drivs av den specialdesignade Kora-motorn, som ger en tiofaldig förbättring av prestandan jämfört med att driva ett eget Kafka-kluster. Här följer några av dess egenskaper:
- Serverlösa kluster för skalbarhet och flexibilitet, vilket gör att du snabbt kan anpassa dig till dataströmningsbehov genom automatisk upp- och nedskalning på begäran.
- Obegränsad datalagring med bibehållen dataintegritet. Confluent Cloud kan fungera som din enda källa till sanning utan problem med hållbarhet.
- Confluent Cloud garanterar en 99,99 % drifttid, vilket är bland de högsta i branschen. Med flerzonsreplikering är du skyddad mot dataförlust eller korruption.
Stream Designer erbjuder ett användarvänligt dra-och-släpp-gränssnitt för att visuellt bygga din processpipeline. Förutom detta gör fördefinierade Kafka-anslutningar det möjligt att ansluta till valfri applikation eller dataleverantör.
Confluent Cloud erbjuder Stream Governance, den enda helt hanterade sviten för datastyrning i branschen. Med molnsäkerhet i företagsklass och efterlevnad av regler kan du skydda dina data och kontrollera åtkomsten.
Confluent Cloud erbjuder flera prisplaner och tillhandahåller även ett omfattande utbud av resurser för att hjälpa dig att snabbt komma igång.
Aiven

Aiven underlättar implementeringen av dina dataströmningsbehov genom en fullt hanterad molntjänst för Apache Kafka. Den stöder alla större molnleverantörer, inklusive AWS, Google Cloud, Microsoft Azure, Digital Ocean och UpCloud.
Konfigurera din egen Kafka-tjänst på mindre än 10 minuter med hjälp av webbkonsolen, API eller CLI. Dessutom har du möjlighet att köra tjänsten i containrar.
Förenkla hanteringen av Kafka med en fullständigt hanterad molntjänst. Du kan snabbt konfigurera din datapipeline tillsammans med en övervakningspanel. Här är några av fördelarna du får:
- Automatiska uppdateringar för ditt kluster samt hantering av versionsuppgraderingar och underhåll med bara några få klick.
- Aiven erbjuder en drifttid på 99,99 % med minimala avbrott.
- Skala lagringsutrymmet, lägg till fler Kafka-noder eller distribuera till olika regioner.
Aivens månatliga prisplan börjar från 200 dollar och varierar beroende på din plats och vilken molnleverantör du väljer.
Arroyo
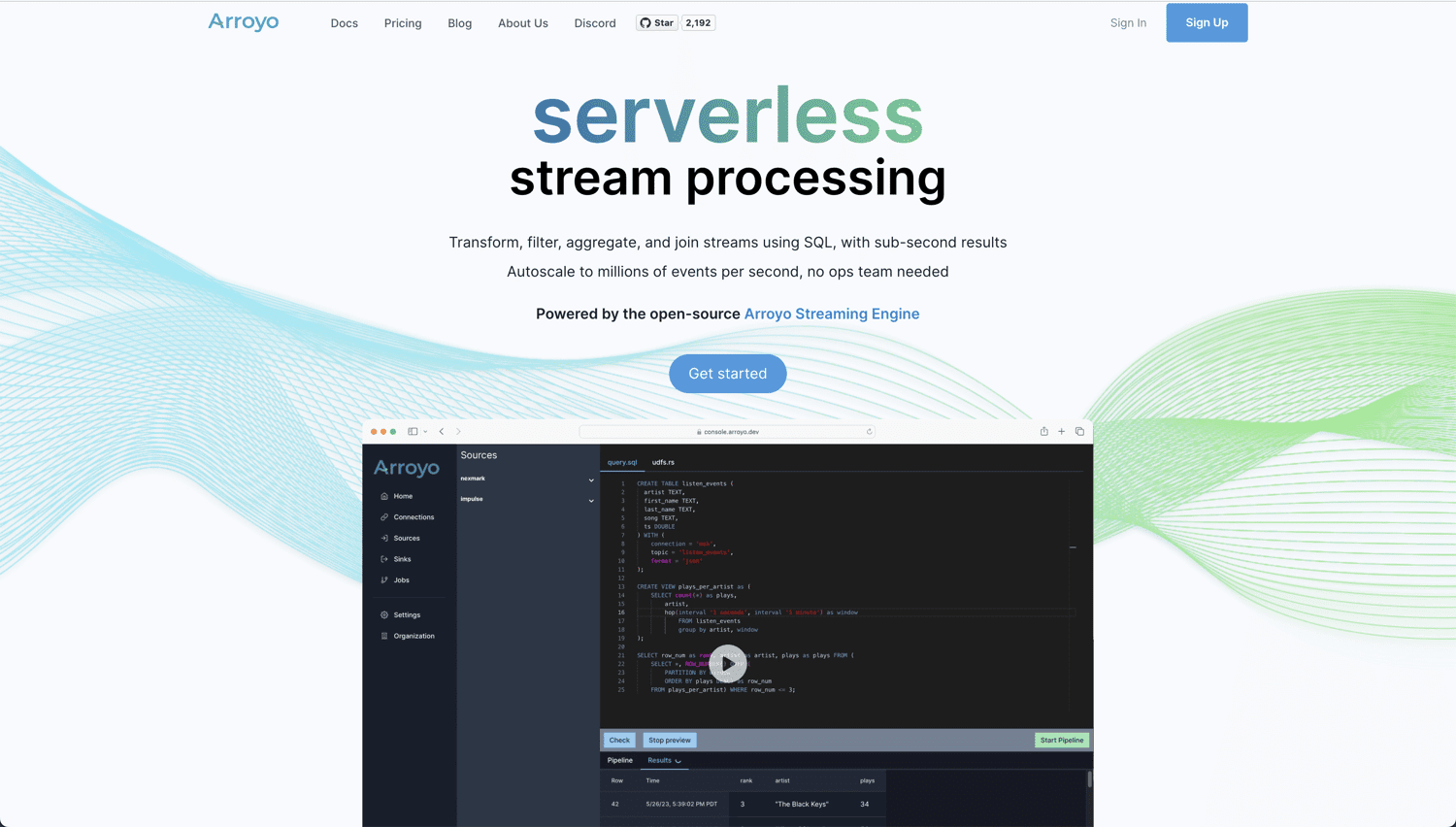
Om du söker en fullständigt molnbaserad lösning med öppen källkod för realtidsanalys och databearbetning är Arroyo ett utmärkt val. Det drivs av Arroyo Streaming Engine, en distribuerad strömbehandlingslösning som utmärker sig inom realtidsdatasökning med resultat inom en sekund.
Arroyo är utformat för att göra realtidsbearbetning lika enkelt som batchbearbetning. Det användarvänliga gränssnittet innebär att du inte behöver vara expert för att bygga din pipeline. Här är vad du får med Arroyo:
- Inbyggt stöd för en rad olika anslutningar, inklusive Kafka, Pulsar, Redpanda, WebSockets och Server Sent Events.
- Efter datainmatning och bearbetning kan resultaten skickas till flera olika system som Kafka, Amazon S3 och Postgres.
- En modern, effektiv och högpresterande kompilator som konverterar SQL-förfrågningar för maximal effektivitet.
- Dataflödet för dina dataplattformar kan skalas horisontellt för att stödja miljontals händelser per sekund.
Du kan köra din egen värdinstans av Arroyo, vilket är kostnadsfritt, eller använda Arroyo Cloud som kostar från 200 dollar per månad. Det bör dock noteras att Arroyo för närvarande är i alfaversion och kan sakna vissa funktioner.
Amazon Kinesis

Amazon Kinesis Data Streams gör det möjligt att samla in och bearbeta stora dataströmmar för snabb och kontinuerlig datainmatning. Det erbjuder betydande skalbarhet, hållbarhet och kostnadseffektivitet. Här är några av de viktigaste funktionerna:
- Amazon Kinesis körs i AWS-molnet i ett serverlöst läge på begäran. Du kan starta Kinesis Data Streams med några få klick från AWS Management Console.
- Kinesis kan köras i upp till 3 tillgänglighetszoner (AZ). Det erbjuder också 365 dagars datalagring.
- Kinesis Data Streams tillåter upp till 20 konsumenter. Varje konsument har dedikerad läskapacitet och kan publicera inom 70 millisekunder efter datainmatning.
- Säkerheten säkerställs genom kryptering av data med hjälp av serverkryptering.
- Som en del av AWS kan Kinesis smidigt integreras med andra AWS-tjänster som Cloudwatch, DynamoDB och AWS Lambda.
Med Amazon Kinesis betalar du för det du använder. Med 1000 poster per sekund och 3 KB per post skulle den dagliga kostnaden för ett on-demand-läge uppskattas till cirka 30,61 USD. Du kan använda AWS-kalkylatorn för att beräkna din användningsbaserade kostnad.
Databricks

Om du söker en enda dataplattform för både batch- och strömbehandling är Databricks Lakehouse-plattform ett utmärkt val. Den erbjuder även realtidsanalys, maskininlärning och applikationer på en och samma plattform.
Databricks Lakehouse-plattform har sin egen datavy som kallas Delta Live Tables (DLT) med följande fördelar:
- DLT gör det enkelt att definiera din kompletta datapipeline.
- Automatisk datakvalitetstestning samt övervakning av datakvalitet över tid.
- DLT:s förbättrade autoskalning hanterar oregelbundna arbetsbelastningar.
Du får det bästa stället att köra dina Apache Spark-arbetsbelastningar, med Spark Structured Streaming som kärnteknik. Tillsammans med detta ingår Delta Lake, den enda lagringsplattformen med öppen källkod som stöder både streaming- och batchdata.
Med Databricks Lakehouse-plattform kan du testa tjänsten kostnadsfritt i 14 dagar, efter vilken du automatiskt prenumererar på den plan du har använt.
Qlik Data Streaming (CDC)

CDC eller Change Data Capture är en teknik som används för att informera andra system om varje dataförändring. Qlik Data Streaming (CDC) är en enkel och universell lösning som gör att du smidigt kan flytta data från källa till destination i realtid. Du kan hantera allt via ett enkelt grafiskt gränssnitt.
Qlik Data Streaming (CDC) tillhandahåller en strömlinjeformad och automatiserad konfiguration. Det gör det enkelt att konfigurera, kontrollera och övervaka din datatpipeline i realtid.
Du får stöd från en mängd olika källor, destinationer och plattformar. Detta gör det möjligt att inte bara mata in en mängd olika data utan även synkronisera lokala, moln- och hybriddatamängder.
Qlik Enterprise Manager är ditt centrala kommando-center där du enkelt kan skala upp och övervaka dataflödet genom varningar.
Det finns flexibla distributionsalternativ för hur du vill driva din CDC-pipeline. Du kan välja mellan följande:
Du kan komma igång med en kostnadsfri provperiod utan att behöva ladda ned eller installera något.
Fluvio

Söker du en molnbaserad strömningslösning med öppen källkod som har låg latens och hög prestanda? Fluvio uppfyller dessa krav. Du får också möjlighet att utföra beräkningar med SmartModules, vilket utökar funktionaliteten hos Fluvio-plattformen.
Fluvio har en distribuerad strömbehandling med kontroller för att förhindra dataförlust och driftavbrott. Dessutom finns det integrerat API-stöd för populära programmeringsspråk som Rust, Node.js, Python, Java och Go. Här är några av de fördelar som plattformen erbjuder:
- Möjligheten att kombinera beräkning med strömning i ett enhetligt kluster ger minimala fördröjningar.
- Fluvio laddar dynamiskt anpassade moduler för att utöka beräkningsmöjligheterna.
- Hög skalbarhet som sträcker sig från små IoT-enheter till flerkärniga system.
- Automatiska återställningsfunktioner med deklarativ hantering, avstämning och replikering.
- En kraftfull CLI för effektivitet, eftersom plattformen utvecklades med utvecklargemenskapen i åtanke.
Oavsett om det är på din bärbara dator, i företagets datacenter eller i valfritt offentligt moln, kan du installera Fluvio på valfri plattform.
Eftersom Fluvio är öppen källkod tillkommer inga kostnader för att använda tjänsten.
Cloudera Stream Processing (CSP)

Cloudera Stream Processing (CSP) drivs av Apache Flink och Apache Kafka och ger dig möjligheter att analysera din strömmande data och få insikter. Det har inbyggt stöd för standardtekniker som SQL och REST. Du får dessutom en komplett strömhanteringslösning kombinerad med tillståndsberoende bearbetning som är byggd för företag.
Cloudera Stream Processing läser och analyserar stora mängder realtidsdata för att generera resultat med låg latens. Plattformen erbjuder stöd för multi-cloud- och hybridmoln, tillsammans med de verktyg som krävs för att skapa sofistikerad datadriven analys. Här är några av de verktyg och funktioner som ingår:
- Med stöd för miljontals meddelanden per sekund kan du hänga med i ständigt föränderliga krav med hjälp av mycket skalbar strömning.
- Streams Messaging Manager erbjuder en heltäckande översikt över hur data rör sig genom din databehandlingspipeline.
- Streams Replication Manager erbjuder replikering, tillgänglighet och katastrofåterställning.
- Schema Registry minskar schemarelaterade fel och avbrott genom att du kan hantera allt i ett gemensamt arkiv.
- Cloudera SDX erbjuder enhetlig kontroll och styrning över alla komponenter med centraliserad säkerhet som tillämpas automatiskt.
Med Cloudera Stream Processing kan du sätta upp din strömbehandlingspipeline på den molnplattform du väljer, oavsett om det är AWS, Azure eller Google Cloud Platform, på mindre än 10 minuter.
Striim Cloud
Behöver din dataplattform och realtidsanalys stöd för en rad olika dataproducenter och konsumenter? Striim Cloud, som har inbyggt stöd för över 100 anslutningar, kan vara det perfekta valet. Du kan enkelt integrera med dina befintliga datalager och strömma realtidsdata med en fullständigt hanterad SaaS-plattform som är designad för molnet.
Striim Cloud har ett enkelt dra-och-släpp-gränssnitt som inte bara hjälper dig att bygga din pipeline utan också ger insikter i dina data. Det stöder de mest populära analysverktygen, inklusive Google BigQuery, Snowflake, Azure Synapse och Databricks. Utöver detta får du följande:
- Striims schemautvecklingsfunktioner hanterar datastrukturförändringar. Du kan konfigurera funktionen för automatisk upplösning eller manuell intervention.
- Striim är byggt på en distribuerad strömmande SQL-plattform som gör det möjligt att köra kontinuerliga frågor.
- Striim erbjuder hög skalbarhet och genomströmning, vilket innebär att du kan skala din pipeline utan att behöva planera eller betala extra.
- Metoden ”ReadOnlyWriteMany” gör det möjligt att lägga till och ta bort nya destinationer utan att påverka dina datalager.
Du betalar endast för det du använder. Striims utvecklingsmiljö är kostnadsfri och gör det möjligt att testa plattformen med 10 miljoner händelser per månad. En molnlösning för företag börjar på 2 500 dollar per månad.
VK Streaming Data Platform
Med en hög standard på dataprodukter och insikter hjälper Vertical Knowledge (VK) individer och företag att fatta välgrundade beslut i stor skala. VK Streaming Data Platform gör det möjligt att bearbeta stora mängder data via en webbaserad dataströmningsmiljö.
Få handlingskraftiga insikter med automatisk dataidentifiering. Här är några av de viktigaste fördelarna med VK:s Streaming Data Platform:
- VK:s robusta infrastruktur skyddar mot skadligt innehåll, vilket ger en stabil cybersäkerhet. Du kan även ladda ned data i en virtuell miljö.
- Automatiserade dataströmmar underlättar arbetet med flera datakällor.
- Snabb datainsamling minskar manuella processer, som ofta är tidskrävande.
- Generera djupa datainsikter genom att köra parallella pipelines från flera källor, vilket möjliggör globala resultat för utvalda sökord.
- Du kan exportera datainsamlingarna i rått JSON- eller CSV-format eller använda API:er för integration med tredjepartssystem.
HStream-plattform
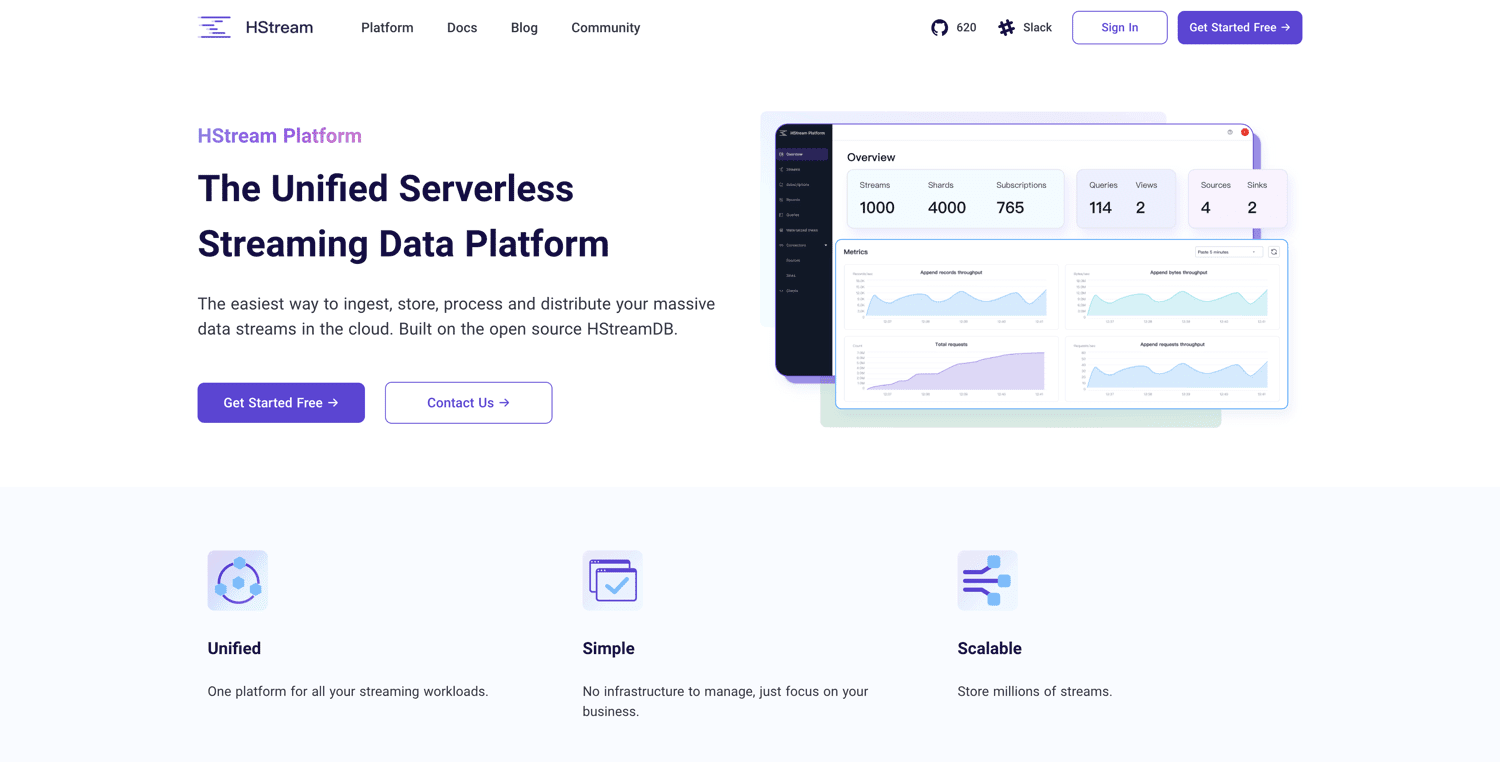
Den HStream-plattformen är byggd på öppen källkod HStreamDB och erbjuder en serverlös plattform för strömmande data. Du kan ta in stora mängder data och på ett tillförlitligt sätt lagra miljontals dataströmmar. HStreamDB är lika snabb som Kafka och gör det även möjligt att spela upp historisk data.
Du kan använda SQL för att filtrera, transformera, aggregera och även kombinera flera datavyer för att få realtidsinsikter i din data. Med HStream-plattformen kan du börja i liten skala och göra flexibla anpassningar. Här är några av de viktigaste funktionerna:
- Eftersom plattformen är serverlös är den redo att användas från start.
- Inget behov av Kafka för dina strömningsbehov.
- Strömbehandling med standard SQL.
- Anslutning till olika system, som databaser, datalager eller datasjöar. Du behöver alltså inte några ytterligare ETL-verktyg.
- Effektiv hantering av all arbetsbelastning i en enhetlig strömningsplattform.
- Den molnbaserade arkitekturen gör att du kan skala dina dator- och lagringsbehov oberoende av varandra.
HStream-plattformen är för närvarande i offentlig beta. Det är kostnadsfritt att använda – allt du behöver göra är att registrera dig.
Slutsats
Valet av en lämplig dataströmningsplattform beror på din skala, behov av olika anslutningar, drifttid och tillförlitlighet.
Vissa plattformar är fullständigt hanterade tjänster, medan andra är öppen källkod och ger dig olika anpassningsmöjligheter. Ta en titt på dina behov och din budget och välj den som bäst passar dig.
Funderar du på hur du bäst kan använda all denna data? Testa AI-drivna verktyg för dataprediktion och prognoser för företag.