Är du intresserad av att utöka din programmeringskompetens med nya datastrukturer? Då är det dags att börja utforska datastrukturer i Python.
När man lär sig ett nytt programmeringsspråk är det centralt att förstå de grundläggande datatyperna och de inbyggda datastrukturerna som språket erbjuder. Denna guide kommer att introducera dig till datastrukturer i Python och täcka följande områden:
- Fördelarna med att använda datastrukturer
- De inbyggda datastrukturerna i Python, såsom listor, tupler, ordböcker och uppsättningar
- Hur man implementerar abstrakta datatyper som stackar och köer.
Låt oss dyka in i det direkt!
Varför är datastrukturer värdefulla?
Innan vi granskar de specifika datastrukturerna, ska vi först undersöka varför datastrukturer är så användbara:
- Effektiv datahantering: Rätt val av datastruktur kan avsevärt öka effektiviteten vid datahantering. Om du exempelvis behöver lagra en samling objekt av samma typ, med snabba uppslagningstider och enhetlig placering, kan en array vara det bästa valet.
- Optimerad minnesanvändning: I större projekt kan en specifik datastruktur vara mer minneseffektiv än en annan för att lagra samma data. I Python, till exempel, kan både listor och tupler användas för att lagra datamängder av liknande eller olika typer. Men om du är säker på att datamängden inte kommer att ändras, kan du välja en tuple, som generellt sett kräver mindre minne än en lista.
- Strukturerad kod: Användning av lämpliga datastrukturer för en given funktionalitet gör koden mer överskådlig. Andra utvecklare som läser din kod förväntar sig att du använder vissa datastrukturer baserat på det avsedda beteendet. Till exempel, om du behöver en nyckel-värde-association med snabba uppslags- och insättningstider, är en ordbok (dictionary) ett passande val.
Listor
Listor är en av de viktigaste datastrukturerna i Python när det gäller att skapa dynamiska arrayer, både i kodningsintervjuer och i vanliga tillämpningar.
Python-listor är föränderliga och dynamiska behållardatatyper, vilket innebär att du kan lägga till eller ta bort element direkt från listan utan att behöva skapa en ny kopia.
När du använder Python-listor:
- Att komma åt ett element med hjälp av dess index är en konstant tidsoperation.
- Att lägga till ett element i slutet av listan är en konstant tidsoperation.
- Att infoga ett element på en specifik position i listan är en linjär tidsoperation.
Det finns flera listmetoder som underlättar vanliga uppgifter på ett effektivt sätt. Exemplet nedan visar hur dessa operationer kan utföras på en exempel lista:
>>> nums = [5,4,3,2] >>> nums.append(7) >>> nums [5, 4, 3, 2, 7] >>> nums.pop() 7 >>> nums [5, 4, 3, 2] >>> nums.insert(0,9) >>> nums [9, 5, 4, 3, 2]
Python-listor stöder även slicing (att dela upp listan i delar) och medlemskapskontroll med hjälp av operatorn ’in’:
>>> nums[1:4] [5, 4, 3] >>> 3 in nums True
Listdatastrukturen är inte bara smidig och enkel utan den tillåter oss även att lagra element av olika datatyper. Python erbjuder även en dedikerad array-datastruktur för att lagra element av samma datatyp effektivt. Vi kommer att utforska detta mer i detalj senare i guiden.
Tupler
Tupler är en annan populär inbyggd datastruktur i Python. De liknar Python-listor på så sätt att man kan komma åt element via index och dela upp dem, men tupler är oföränderliga, vilket betyder att de inte kan ändras efter att de har skapats. Följande exempel illustrerar detta med en tuple som heter ’nums’:
>>> nums = (5,4,3,2) >>> nums[0] 5 >>> nums[0:2] (5, 4) >>> 5 in nums True >>> nums[0] = 7 # Ogiltig operation! Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment
Så när du behöver en oföränderlig samling av data som ska behandlas effektivt, kan du överväga att använda en tuple. Om samlingen behöver vara föränderlig är en lista ett bättre alternativ.
📋 Fördjupa dig i likheterna och skillnaderna mellan Python-listor och tupler.
Arrayer
Arrayer är en mindre känd datastruktur i Python. De påminner om listor i de operationer de stöder, som att komma åt element via index i konstant tid och att infoga element på en specifik position i linjär tid.
Den viktigaste skillnaden mellan listor och arrayer är att arrayer lagrar element av en och samma datatyp. Därför är de mer sammanhållna och minneseffektiva.
För att skapa en array kan vi använda konstruktorn ’array()’ från den inbyggda array-modulen. Konstruktorn ’array()’ tar en sträng som specificerar datatypen för elementen och de faktiska elementen. Här skapar vi ’nums_f’, en array med flyttal:
>>> from array import array
>>> nums_f = array('f',[1.5,4.5,7.5,2.5])
>>> nums_f
array('f', [1.5, 4.5, 7.5, 2.5])
Du kan komma åt element i en array via index (på samma sätt som med listor):
>>> nums_f[0] 1.5
Arrayer är föränderliga, så du kan ändra deras innehåll:
>>> nums_f[0]=3.5
>>> nums_f
array('f', [3.5, 4.5, 7.5, 2.5])
Du kan dock inte ändra ett element så att det får en annan datatyp:
>>> nums_f[0]='zero' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str
Strängar
I Python är strängar oföränderliga samlingar av Unicode-tecken. Till skillnad från språk som C, har Python ingen dedikerad teckentyp. En enskild karaktär representeras som en sträng med längden ett.
Som tidigare nämnts är strängar oföränderliga:
>>> str_1 = 'python' >>> str_1[0] = 'c' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Python-strängar stöder slicing och en mängd metoder för att formatera dem. Här är några exempel:
>>> str_1[1:4] 'yth' >>> str_1.title() 'Python' >>> str_1.upper() 'PYTHON' >>> str_1.swapcase() 'PYTHON'
⚠ Kom ihåg att alla operationer ovan returnerar en kopia av strängen, utan att ändra den ursprungliga strängen. Om du är intresserad kan du kolla in guiden om strängoperationer i Python.
Uppsättningar
I Python är uppsättningar (set) samlingar av unika och hashbara objekt. Du kan utföra standardoperationer på uppsättningar som union, snitt och skillnad:
>>> set_1 = {3,4,5,7}
>>> set_2 = {4,6,7}
>>> set_1.union(set_2)
{3, 4, 5, 6, 7}
>>> set_1.intersection(set_2)
{4, 7}
>>> set_1.difference(set_2)
{3, 5}
Uppsättningar är föränderliga som standard, vilket betyder att du kan lägga till och ta bort element:
>>> set_1.add(10)
>>> set_1
{3, 4, 5, 7, 10}
📚 Läs mer om Uppsättningar i Python: En komplett guide med kodexempel
Frysta uppsättningar
Om du behöver en oföränderlig uppsättning kan du använda en fryst uppsättning (frozenset). Du kan skapa en fryst uppsättning från en existerande uppsättning eller andra itererbara objekt.
>>> frozenset_1 = frozenset(set_1)
>>> frozenset_1
frozenset({3, 4, 5, 7, 10})
Eftersom ’frozenset_1’ är en fryst uppsättning, får vi ett fel om vi försöker lägga till element (eller på annat sätt ändra den):
>>> frozenset_1.add(15) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no attribute 'add'
Ordböcker
En Python-ordbok fungerar som en hash-karta. Ordböcker används för att lagra nyckel-värde-par. Nycklarna i ordboken måste vara hashbara, vilket innebär att objektets hashvärde inte ändras.
Du kan snabbt komma åt värden med hjälp av nycklar, infoga nya objekt och ta bort existerande objekt. Det finns metoder för att hantera dessa operationer:
>>> favorites = {'book':'Orlando'}
>>> favorites
{'book': 'Orlando'}
>>> favorites['author']='Virginia Woolf'
>>> favorites
{'book': 'Orlando', 'author': 'Virginia Woolf'}
>>> favorites.pop('author')
'Virginia Woolf'
>>> favorites
{'book': 'Orlando'}
OrderedDict
Även om en Python-ordbok tillhandahåller en nyckel-värde-mappning, är den i sig en oordnad datastruktur. Från och med Python 3.7 bevaras infogningsordningen för element, men du kan göra detta mer explicit genom att använda ’OrderedDict’ från ’collections’-modulen.
Som visas nedan bevarar ’OrderedDict’ ordningen för nycklarna:
>>> from collections import OrderedDict
>>> od = OrderedDict()
>>> od['first']='one'
>>> od['second']='two'
>>> od['third']='three'
>>> od
OrderedDict([('first', 'one'), ('second', 'two'), ('third', 'three')])
>>> od.keys()
odict_keys(['first', 'second', 'third'])
Defaultdict
Nyckelfel är vanliga när man arbetar med Python-ordböcker. Om man försöker komma åt en nyckel som inte finns i ordboken får man ett ’KeyError’-undantag.
Genom att använda ’defaultdict’ från ’collections’-modulen, kan du hantera detta inbyggt. När man försöker komma åt en nyckel som inte finns i ordboken, läggs nyckeln till och initieras med ett standardvärde enligt den standardfabriksfunktion som anges.
>>> from collections import defaultdict >>> prices = defaultdict(int) >>> prices['carrots'] 0
Stackar
En stack är en LIFO-datastruktur (Last-In, First-Out). Följande operationer kan utföras på en stack:
- Lägg till element i toppen av stacken: push-operation
- Ta bort element från toppen av stacken: pop-operation
Här är en illustration av hur push- och pop-operationerna fungerar i en stack:
Hur man implementerar en stack med en lista
I Python kan vi implementera en stack med hjälp av en lista.
Operation på stacken | Motsvarande listoperation
——————–|———————————-
Push till stackens topp | Lägg till i slutet av listan med metoden ’append()’
Pop från stackens topp| Ta bort och returnera det sista elementet med metoden ’pop()’
Följande kodavsnitt visar hur vi kan efterlikna beteendet hos en stack med hjälp av en Python-lista:
>>> l_stk = [] >>> l_stk.append(4) >>> l_stk.append(3) >>> l_stk.append(7) >>> l_stk.append(2) >>> l_stk.append(9) >>> l_stk [4, 3, 7, 2, 9] >>> l_stk.pop() 9
Hur man implementerar en stack med en Deque
Ett annat sätt att implementera en stack är genom att använda en ’deque’ från ’collections’-modulen. Deque står för double-ended queue, och den stöder tillägg och borttagning av element från båda ändarna.
För att efterlikna en stack kan vi:
- Lägga till element i slutet av dequen med metoden ’append()’ och
- Ta bort det senast tillagda elementet med metoden ’pop()’.
>>> from collections import deque >>> stk = deque() >>> stk.append(4) >>> stk.append(3) >>> stk.append(7) >>> stk.append(2) >>> stk.append(9) >>> stk deque([4, 3, 7, 2, 9]) >>> stk.pop() 9
Köer
En kö är en FIFO-datastruktur (First-In, First-Out). Element läggs till i slutet av kön och tas bort från början (huvudet på kön) enligt följande illustration:
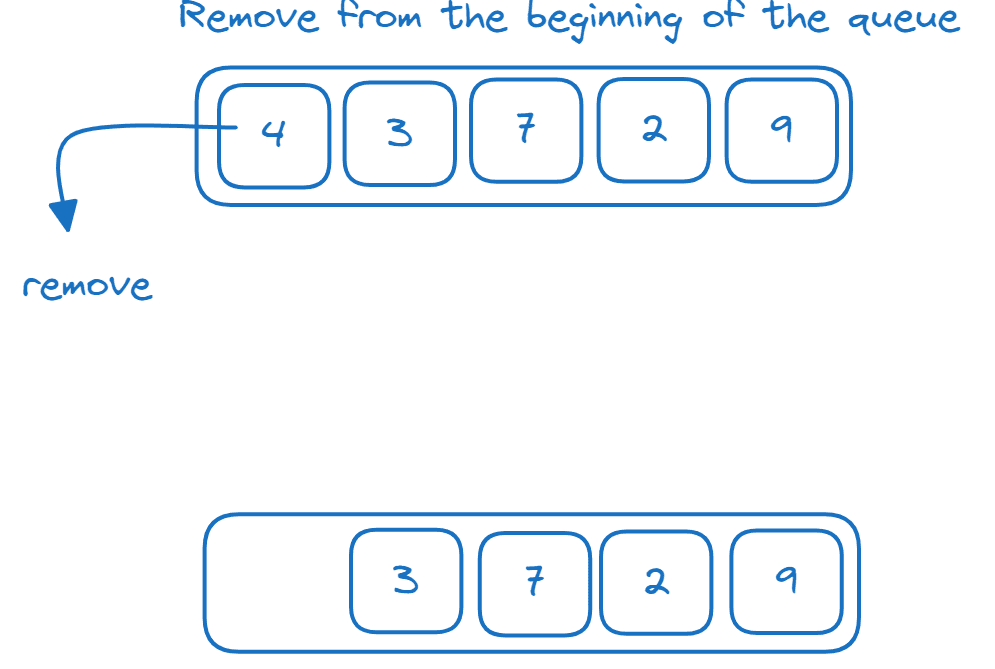
Vi kan implementera en kö med hjälp av en ’deque’:
- Lägg till element i slutet av kön med metoden ’append()’.
- Använd metoden ’popleft()’ för att ta bort element från början av kön.
>>> from collections import deque >>> q = deque() >>> q.append(4) >>> q.append(3) >>> q.append(7) >>> q.append(2) >>> q.append(9) >>> q.popleft() 4
Högar
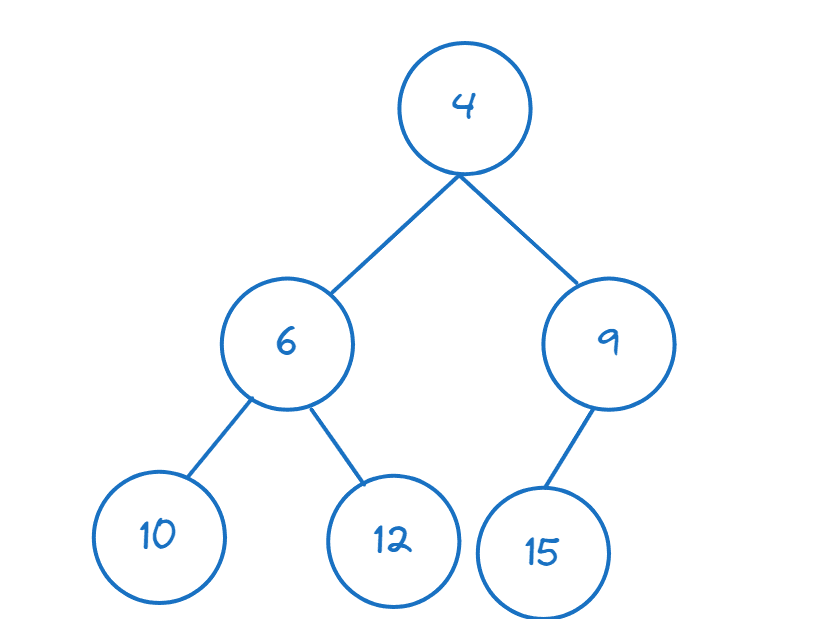
I det här avsnittet ska vi undersöka binära högar, med fokus på min-högar.
En min-hög är ett fullständigt binärt träd. Låt oss definiera vad ett fullständigt binärt träd innebär:
- Ett binärt träd är en datastruktur där varje nod har maximalt två underordnade noder. I en min-hög är varje nod mindre än sina underordnade.
- Termen ”fullständigt” betyder att trädet är helt fyllt, förutom möjligen den sista nivån. Om den sista nivån är delvis fylld, fylls den från vänster till höger.
Eftersom varje nod har maximalt två underordnade, och varje nod är mindre än sina underordnade, är roten det minsta elementet i en min-hög.
Här är ett exempel på en min-hög:
I Python hjälper ’heapq’-modulen oss att bygga högar och utföra operationer på högen. Vi kan importera de funktioner som behövs från ’heapq’ så här:
>>> from heapq import heapify, heappush, heappop
Om du har en lista eller ett annat itererbart objekt kan du bygga en hög från den genom att anropa ’heapify()’:
>>> nums = [11,8,12,3,7,9,10] >>> heapify(nums)
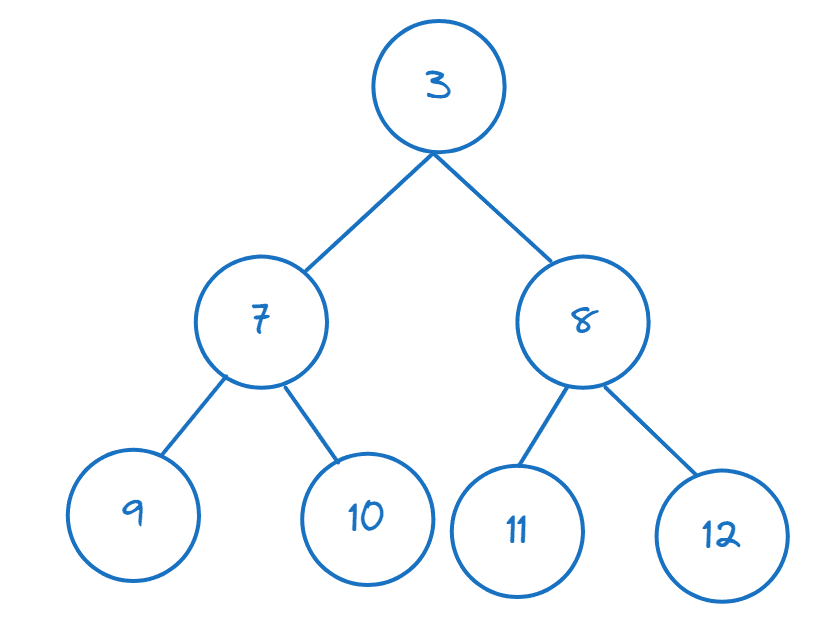
Du kan kontrollera att det första elementet (roten) är det minsta genom att komma åt det via index:
>>> nums[0] 3
Om du nu infogar ett element i högen kommer noderna att omorganiseras så att min-hög-egenskapen bibehålls.
>>> heappush(nums,1)
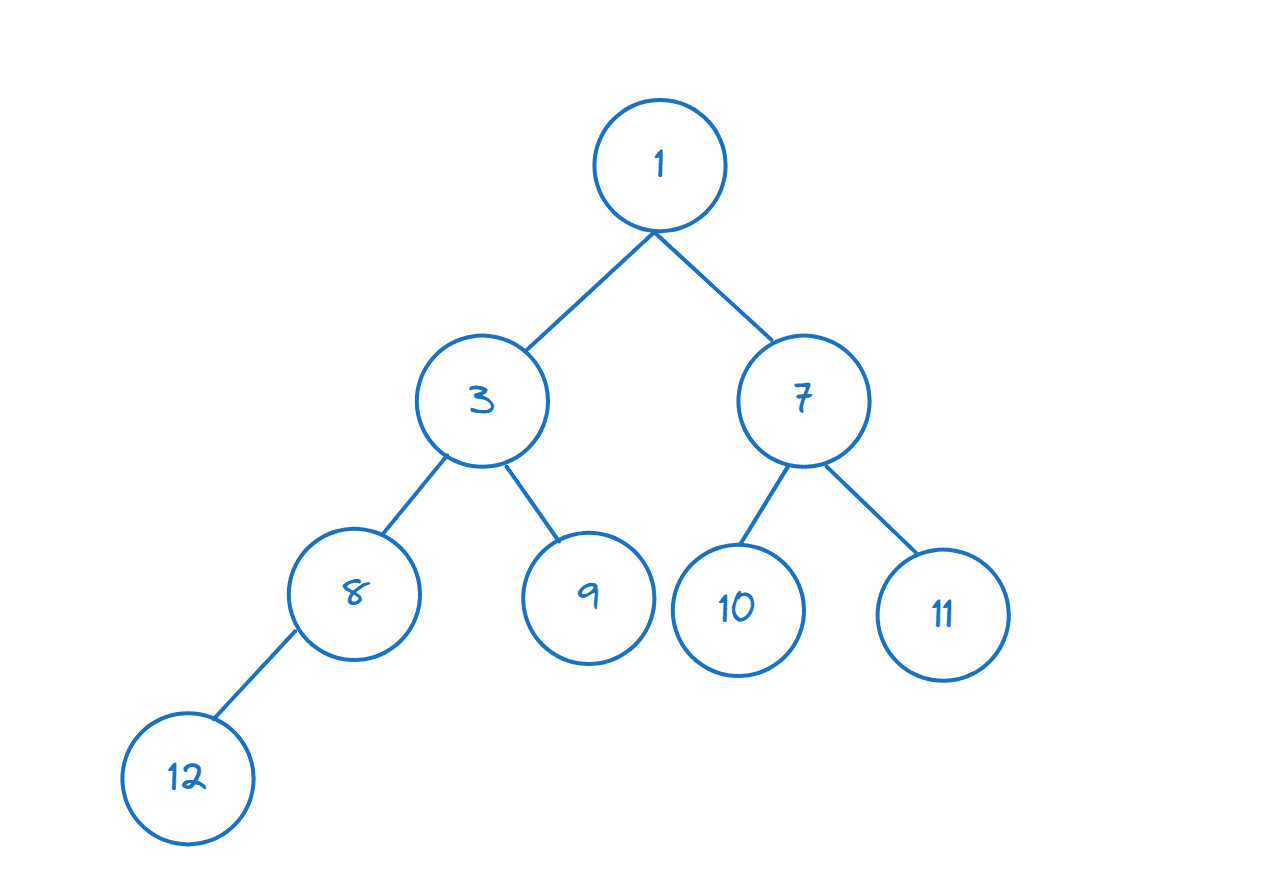
Efter att ha infogat 1 (1 < 3) ser vi att ’nums[0]’ nu returnerar 1, som nu är det minsta elementet (och rotnoden).
>>> nums[0] 1
Du kan ta bort element från min-högen genom att anropa funktionen ’heappop()’ enligt följande:
>>> while nums: ... print(heappop(nums)) ...
# Output 1 3 7 8 9 10 11 12
Max-högar i Python
Nu när du har lärt dig om min-högar, hur tror du att vi kan implementera en max-hög?
Vi kan konvertera en min-hög-implementering till en max-hög genom att multiplicera varje tal med -1. Negerade tal ordnade i en min-hög motsvarar de ursprungliga talen ordnade i en max-hög.
I Python-implementeringen kan vi multiplicera elementen med -1 när vi lägger till dem i högen med metoden ’heappush()’:
>>> maxHeap = [] >>> heappush(maxHeap,-2) >>> heappush(maxHeap,-5) >>> heappush(maxHeap,-7)
Rotnoden (multiplicerad med -1) kommer att vara det maximala elementet:
>>> -1*maxHeap[0] 7
När du tar bort element från högen, använd ’heappop()’ och multiplicera resultatet med -1 för att få tillbaka det ursprungliga värdet:
>>> while maxHeap: ... print(-1*heappop(maxHeap)) ...
# Output 7 5 2
Prioriterade köer
Låt oss avsluta diskussionen genom att undersöka prioriterade köer i Python.
Vi vet att element i en vanlig kö tas bort i samma ordning som de anländer. Men en prioriterad kö hanterar element enligt deras prioritet, vilket är användbart för exempelvis schemaläggning. Elementet med högst prioritet returneras först.
Vi kan använda nycklar för att definiera prioritet. Här kommer vi att använda numeriska vikter för nycklarna.
Hur man implementerar prioriterade köer med Heapq
Här är ett exempel på hur man kan implementera en prioriterad kö med ’heapq’ och en Python-lista:
>>> from heapq import heappush,heappop >>> pq = [] >>> heappush(pq,(2,'write')) >>> heappush(pq,(1,'read')) >>> heappush(pq,(3,'code')) >>> while pq: ... print(heappop(pq)) ...
När man tar bort element från kön, hanteras det element med högst prioritet först (1, ’read’), därefter (2, ’write’) och sedan (3, ’code’).
# Output (1, 'read') (2, 'write') (3, 'code')
Hur man implementerar prioriterade köer med PriorityQueue
För att implementera en prioriterad kö kan vi också använda klassen ’PriorityQueue’ från modulen ’queue’. Denna klass använder också en hög internt.
Här är motsvarande implementering av en prioriterad kö med ’PriorityQueue’:
>>> from queue import PriorityQueue >>> pq = PriorityQueue() >>> pq.put((2,'write')) >>> pq.put((1,'read')) >>> pq.put((3,'code')) >>> pq <queue.PriorityQueue object at 0x00BDE730> >>> while not pq.empty(): ... print(pq.get()) ...
# Output (1, 'read') (2, 'write') (3, 'code')
Sammanfattning
I den här guiden har du lärt dig om de olika inbyggda datastrukturerna i Python. Vi har också undersökt de operationer som stöds av dessa datastrukturer och de inbyggda metoderna för att utföra dem.
Vi har även gått igenom andra datastrukturer som stackar, köer och prioriterade köer, samt hur man implementerar dessa i Python med hjälp av funktioner från ’collections’-modulen.
Kolla gärna in listan med nybörjarvänliga Python-projekt härnäst.