

Webbskrapning är idén att extrahera information från en webbplats och använda den för ett visst användningsfall.
Låt oss säga att du försöker extrahera en tabell från en webbsida, konvertera den till en JSON-fil och använda JSON-filen för att bygga några interna verktyg. Med hjälp av webbskrapning kan du extrahera den data du vill ha genom att rikta in dig på de specifika elementen på en webbsida. Webbskrapning med Python är ett mycket populärt val eftersom Python tillhandahåller flera bibliotek som BeautifulSoup eller Scrapy för att extrahera data effektivt.
Att ha förmågan att extrahera data effektivt är också mycket viktigt som utvecklare eller dataforskare. Den här artikeln hjälper dig att förstå hur du skrapar en webbplats effektivt och får det nödvändiga innehållet för att manipulera den efter dina behov. För den här handledningen kommer vi att använda paketet BeautifulSoup. Det är ett trendigt paket för att skrapa data i Python.
Innehållsförteckning
Varför använda Python för webbskrapning?
Python är förstahandsvalet för många utvecklare när de bygger webbskrapor. Det finns många anledningar till varför Python är förstahandsvalet, men för den här artikeln, låt oss diskutera tre främsta skälen till varför Python används för dataskrapning.
Bibliotek och Community Support: Det finns flera fantastiska bibliotek, som BeautifulSoup, Scrapy, Selenium, etc., som tillhandahåller fantastiska funktioner för att effektivt skrapa webbsidor. Det har byggt ett utmärkt ekosystem för webbskrapning, och även eftersom många utvecklare över hela världen redan använder Python kan du snabbt få hjälp när du har fastnat.
Automation: Python är känt för sina automationsmöjligheter. Mer än webbskrapning krävs om du försöker göra ett komplext verktyg som förlitar sig på skrapning. Om du till exempel vill bygga ett verktyg som spårar priset på varor i en onlinebutik, måste du lägga till en automatiseringsfunktion så att den kan spåra priserna dagligen och lägga till dem i din databas. Python ger dig möjligheten att automatisera sådana processer med lätthet.
Datavisualisering: Webbskrapning används flitigt av dataforskare. Dataforskare behöver ofta extrahera data från webbsidor. Med bibliotek som Pandas gör Python datavisualisering enklare från rådata.
Bibliotek för webbskrapning i Python
Det finns flera bibliotek tillgängliga i Python för att göra webbskrapning enklare. Låt oss diskutera de tre mest populära biblioteken här.
#1. Vacker soppa
Ett av de mest populära biblioteken för webbskrapning. BeautifulSoup har hjälpt utvecklare att skrapa webbsidor sedan 2004. Det ger enkla metoder för att navigera, söka och modifiera analysträdet. Beautifulsoup själv gör också kodningen för inkommande och utgående data. Det är välskött och har en stor gemenskap.
#2. Skramligt
Ett annat populärt ramverk för dataextraktion. Scrapy har mer än 43 000 stjärnor på GitHub. Den kan också användas för att skrapa data från API:er. Den har också några intressanta inbyggda stöd, som att skicka e-post.
#3. Selen
Selen är inte huvudsakligen ett webbskrapningsbibliotek. Istället är det ett webbläsarautomatiseringspaket. Men vi kan enkelt utöka dess funktioner för att skrapa webbsidor. Den använder WebDriver-protokollet för att styra olika webbläsare. Selen har funnits på marknaden i nästan 20 år nu. Men med Selenium kan du enkelt automatisera och skrapa data från webbsidor.
Utmaningar med Python Web Scraping
Man kan möta många utmaningar när man försöker skrapa data från webbplatser. Det finns problem som långsamma nätverk, anti-skrapningsverktyg, IP-baserad blockering, captcha-blockering, etc. Dessa problem kan orsaka enorma problem när man försöker skrapa en webbplats.
Men du kan effektivt kringgå utmaningar genom att följa några sätt. Till exempel, i de flesta fall blockeras en IP-adress av en webbplats när det finns mer än en viss mängd förfrågningar som skickas under ett visst tidsintervall. För att undvika IP-blockering måste du koda din skrapa så att den svalnar efter att ha skickat förfrågningar.

Utvecklare tenderar också att sätta honungsfällor för skrapor. Dessa fällor är vanligtvis osynliga för bara mänskliga ögon men kan krypas av en skrapa. Om du skrapar en webbplats som sätter en sådan honungskruka, måste du koda din skrapa därefter.
Captcha är ett annat allvarligt problem med skrapor. De flesta webbplatser använder numera en captcha för att skydda botåtkomst till sina sidor. I ett sådant fall kan du behöva använda en captcha-lösare.
Skrapa en webbplats med Python
Som vi diskuterade kommer vi att använda BeautifulSoup för att skrota en webbplats. I den här handledningen kommer vi att skrapa Ethereums historiska data från Coingecko och spara tabelldata som en JSON-fil. Låt oss gå vidare till att bygga skrapan.
Det första steget är att installera BeautifulSoup and Requests. För den här handledningen kommer jag att använda Pipenv. Pipenv är en virtuell miljöhanterare för Python. Du kan också använda Venv om du vill, men jag föredrar Pipenv. Att diskutera Pipenv ligger utanför ramen för denna handledning. Men om du vill lära dig hur Pipenv kan användas, följ den här guiden. Eller, om du vill förstå Python virtuella miljöer, följ den här guiden.
Starta Pipenv-skalet i din projektkatalog genom att köra kommandot pipenv-skalet. Det kommer att lansera ett subshell i din virtuella miljö. Nu, för att installera BeautifulSoup, kör följande kommando:
pipenv install beautifulsoup4
Och för att installera förfrågningar, kör kommandot som liknar ovanstående:
pipenv install requests
När installationen är klar, importera de nödvändiga paketen till huvudfilen. Skapa en fil som heter main.py och importera paketen enligt nedan:
from bs4 import BeautifulSoup import requests import json
Nästa steg är att hämta innehållet på den historiska datasidan och analysera dem med hjälp av HTML-tolken som finns i BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
I ovanstående kod nås sidan med hjälp av get-metoden som är tillgänglig i förfrågningsbiblioteket. Det analyserade innehållet lagras sedan i en variabel som kallas soppa.
Den ursprungliga skrapdelen börjar nu. Först måste du identifiera tabellen korrekt i DOM. Om du öppnar den här sidan och inspekterar den med hjälp av utvecklarverktygen som finns tillgängliga i webbläsaren, ser du att tabellen har dessa klasser tabell tabell-randig text-sm text-lg-normal.
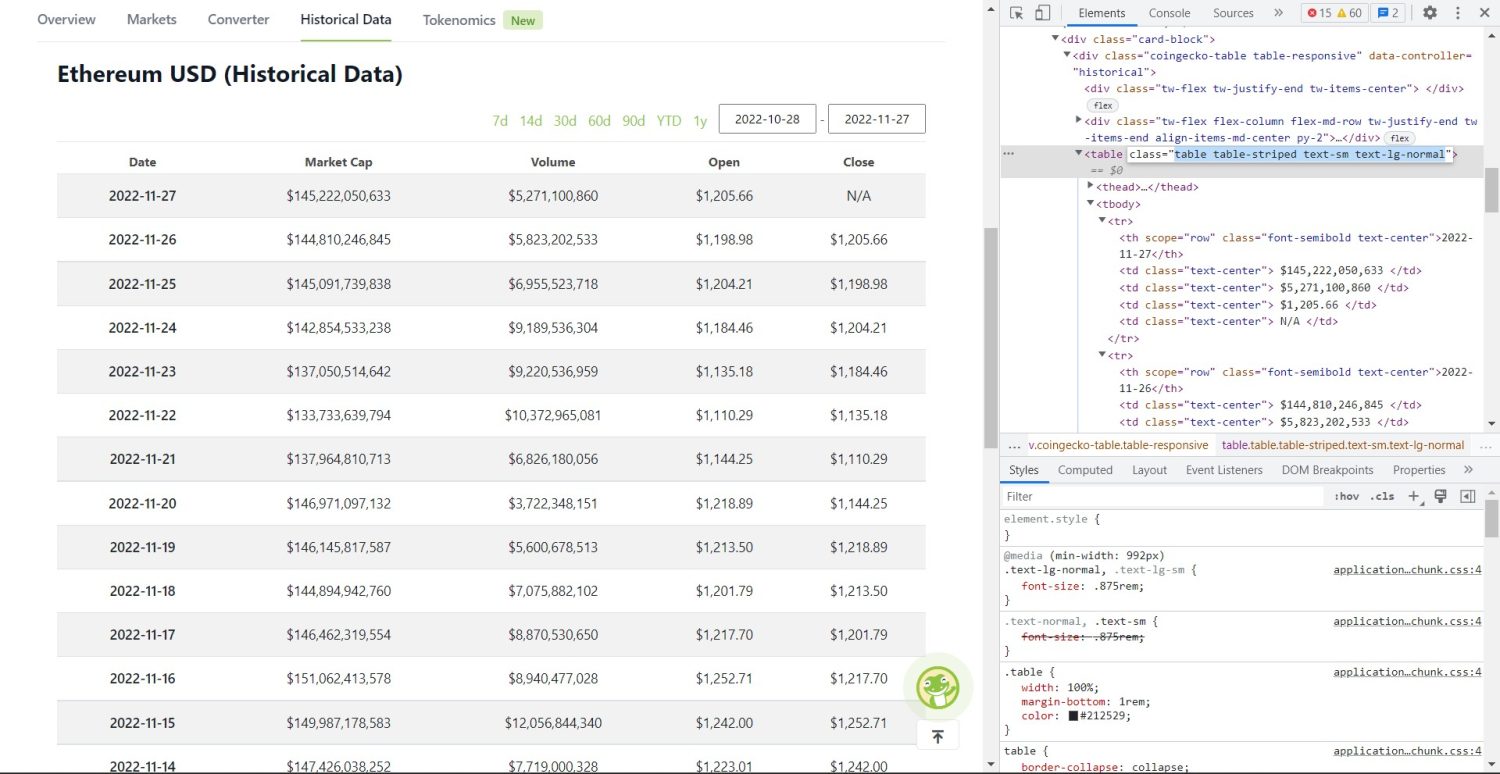 Coingecko Ethereum Historisk datatabell
Coingecko Ethereum Historisk datatabell
För att rikta in den här tabellen korrekt kan du använda sökmetoden.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
I koden ovan hittas först tabellen med metoden soup.find, sedan genom att använda metoden find_all, genomsöks alla tr-element i tabellen. Dessa tr-element lagras i en variabel som heter table_data. Tabellen har några få element för titeln. En ny variabel som heter table_headings initieras för att behålla titlarna i en lista.
En for-loop körs sedan för den första raden i tabellen. På den här raden genomsöks alla element med th, och deras textvärde läggs till i listan table_headings. Texten extraheras med textmetoden. Om du skriver ut variabeln table_headings nu kommer du att kunna se följande utdata:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Nästa steg är att skrapa resten av elementen, skapa en ordlista för varje rad och sedan lägga till raderna i en lista.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Detta är den väsentliga delen av koden. För varje tr i variabeln table_data genomsöks först de th elementen. De e elementen är det datum som visas i tabellen. Dessa th element lagras inuti en variabel th. På samma sätt lagras alla td-element i td-variabeln.
En tom ordboksdata initieras. Efter initieringen går vi igenom intervallet av td-element. För varje rad uppdaterar vi först det första fältet i ordboken med den första posten i th. Koden table_headings[0]: th[0].text tilldelar ett nyckel-värdepar av datum och det första elementet.
Efter initialisering av det första elementet tilldelas de andra elementen med data.update({table_headings[i+1]: td[i].text.replace(’n’, ”)}). Här extraheras td elements text först med hjälp av textmetoden, och sedan ersätts alla n med metoden ersätt. Värdet tilldelas sedan det i+1:e elementet i listan table_headings eftersom det i:te elementet redan är tilldelat.
Sedan, om dataordbokens längd överstiger noll, lägger vi till ordboken till listan table_details. Du kan skriva ut listan table_details för att kontrollera. Men vi kommer att skriva värdena en JSON-fil. Låt oss ta en titt på koden för detta,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Vi använder metoden json.dump här för att skriva värdena i en JSON-fil som heter table.json. När skrivningen är klar skriver vi ut data som sparats i json-filen… i konsolen.
Kör nu filen med följande kommando,
python run main.py
Efter en tid kommer du att kunna se data som sparats i JSON-fil… text i konsolen. Du kommer också att se en ny fil som heter table.json i arbetsfilkatalogen. Filen kommer att se ut som följande JSON-fil:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Du har framgångsrikt implementerat en webbskrapa med Python. För att se hela koden kan du besöka denna GitHub-repo.
Slutsats
Den här artikeln diskuterade hur du kan implementera en enkel Python-skrapa. Vi diskuterade hur BeautifulSoup kan användas för att snabbt skrapa data från webbplatsen. Vi diskuterade också andra tillgängliga bibliotek och varför Python är förstahandsvalet för många utvecklare för att skrapa webbplatser.
Du kan också titta på dessa ramverk för webbskrapning.