

Om du är bekant med djupinlärning har du förmodligen hört uttrycket PyTorch vs. TensorFlow mer än en gång.
PyTorch och TensorFlow är två av de mest populära ramverken för djupinlärning. Den här guiden presenterar en omfattande översikt av de framträdande egenskaperna hos dessa två ramverk – för att hjälpa dig att bestämma vilket ramverk du ska använda – för ditt nästa djupinlärningsprojekt.
I den här artikeln kommer vi först att introducera de två ramverken: PyTorch och TensorFlow. Och summera sedan funktionerna de erbjuder.
Låt oss börja!
Innehållsförteckning
Vad är PyTorch?
PyTorch är ett ramverk med öppen källkod för att bygga modeller för maskininlärning och djupinlärning för olika applikationer, inklusive naturlig språkbehandling och maskininlärning.
Det är ett Pythonic-ramverk utvecklat av Meta AI (än Facebook AI) 2016, baserat på Torch, ett paket skrivet i Lua.
Nyligen släppte Meta AI PyTorch 2.0. Den nya utgåvan erbjuder bland annat bättre stöd för distribuerad utbildning, modellkompilering och grafiska neurala nätverk (GNN).
Vad är TensorFlow?

TensorFlow introducerades 2014 och är ett ramverk för maskininlärning med öppen källkod från Google. Den levereras fullspäckad med funktioner för dataförberedelse, modelldistribution och MLOps.
Med TensorFlow får du plattformsoberoende utvecklingsstöd och direkt support för alla steg i maskininlärningslivscykeln.
PyTorch vs. TensorFlow
Både PyTorch och TensorFlow är superpopulära ramverk inom djupinlärningsgemenskapen. För de flesta applikationer som du vill arbeta med ger båda dessa ramverk inbyggt stöd.
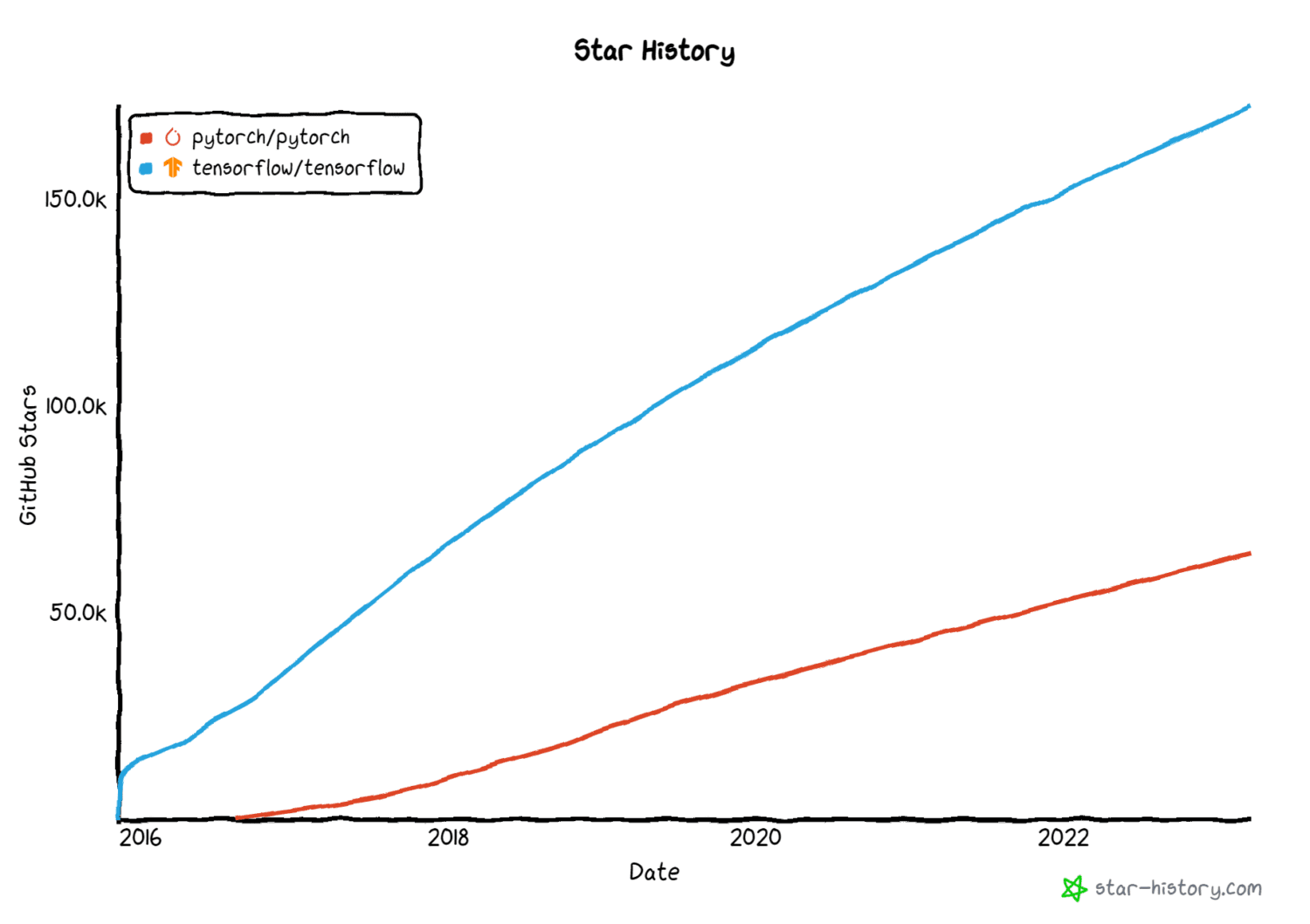 Bildkälla: star-history.com
Bildkälla: star-history.com
Här kommer vi att sammanfatta nyckelfunktionerna i både PyTorch och TensorFlow och även identifiera användningsfall där du kanske föredrar ett ramverk framför det andra.
#1. Bibliotek med datamängder och förtränade modeller
Ett ramverk för djupinlärning bör komma med batterier. Ofta vill du inte koda en modell från början. Istället kan du utnyttja förutbildade modeller och finjustera dem till ditt användningsområde.
På samma sätt vill vi att vanliga datauppsättningar ska vara lättillgängliga. Detta skulle göra det möjligt för oss att snabbt bygga experimentella modeller utan att behöva sätta upp en datainsamlingspipeline eller importera och rensa data från andra källor.
För detta ändamål skulle vi vilja att dessa ramverk kommer med både datauppsättningar och förtränade modeller så att vi kan få en grundmodell mycket snabbare.
PyTorch datamängder och modeller
PyTorch har bibliotek som torchtext, torchaudio och torchvision för NLP-, ljud- och bildbehandlingsuppgifter. Så när du arbetar med PyTorch kan du utnyttja datauppsättningarna och modellerna som tillhandahålls av dessa bibliotek, inklusive:
- torchtext.dataset och torchtext.modeller för datauppsättningar och bearbetning för bearbetningsuppgifter för naturligt språk
- torchvision.datasets och torchvision.models tillhandahåller bilddatauppsättningar och förtränade modeller för datorseendeuppgifter
- torchaudio.datasets och torchaudio.models för datauppsättningar och förtränade modellvikter och verktyg för maskininlärning på ljud
TensorFlow-datauppsättningar och modeller
Dessutom kan du leta efter både PyTorch- och TensorFlow-modeller i HuggingFace Model Hub.
#2. Support för implementering
I debatten om PyTorch vs. TensorFlow är stöd för implementering ofta i centrum.
En maskininlärningsmodell som fungerar utmärkt i din lokala utvecklingsmiljö är en bra utgångspunkt. Men för att få värde från maskininlärningsmodeller är det viktigt att distribuera dem till produktion och övervaka dem kontinuerligt.
I det här avsnittet tar vi en titt på funktioner som både PyTorch och TensorFlow erbjuder för att distribuera maskininlärningsmodeller till produktion.
TensorFlow Extended (TFX)
TensorFlow Extended, förkortat tfx, är ett distributionsramverk som är baserat på TensorFlow. Den tillhandahåller funktionalitet som hjälper dig att orkestrera och underhålla pipelines för maskininlärning. Den tillhandahåller bland annat funktioner för datavalidering och datatransformation.
Med TensorFlow Serving kan du distribuera maskininlärningsmodeller i produktionsmiljöer.
TorchServe
Det finns en vanlig åsikt att PyTorch är populärt i forskarvärlden medan TensorFlow är populärt i branschen. På senare tid har dock båda dessa ramverk funnit en utbredd användning.
Liksom TensorFlow Serving tillhandahåller PyTorch TorchServe, ett lättanvänt ramverk som gör det enkelt att serva PyTorch-modeller i produktion. Dessutom kan du också använda TensorFlow Lite för att distribuera maskininlärningsmodeller på mobila och andra avancerade enheter.
Trots att båda ramverken tillhandahåller distributionsstöd, stöder TensorFlow inbyggt modelldistribution. Det är därför det föredragna valet i produktionsmiljöer.
#3. Funktioner för modelltolkbarhet
Du kan bygga modeller för djupinlärning för applikationer som används inom domäner som hälsovård och finans. Men om modellerna är svarta lådor som producerar en given etikett eller förutsägelse, finns det en utmaning att tolka modellens förutsägelser.
Detta ledde till tolkningsbar maskininlärning (eller förklarabar ML) för att komma på metoder för att förklara hur neurala nätverk och andra maskininlärningsmodeller fungerar.
Därför är tolkningsbarhet superviktigt för djupinlärning och för att bättre förstå hur neurala nätverk fungerar. Och vi ska se vilka funktioner PyTorch och TensorFlow erbjuder för detsamma.
PyTorch Captum
PyTorch Captum, modelltolkbarhetsbiblioteket för PyTorch, tillhandahåller flera funktioner för modelltolkbarhet.

Dessa funktioner inkluderar tillskrivningsmetoder som:
- Integrerade övertoningar
- LIME, SHAP
- DeepLIFT
- GradCAM och varianter
- Metoder för lagertillskrivning
TensorFlow Explain (tf-explain)
Tensorflow Explain (tf-explain) är ett bibliotek som tillhandahåller funktionalitet för tolkning av neurala nätverk, inklusive:
- Integrerade övertoningar
- GradCAM
- SmoothGrad
- Vaniljgradienter och mer.
Hittills har vi sett funktionerna för tolkning. Låt oss gå vidare till en annan viktig aspekt – integritet.
#4. Stöd för integritetsbevarande maskininlärning
Användbarheten av maskininlärningsmodeller är beroende av tillgång till verklig data. Detta kommer dock med nackdelen att integriteten för data går förlorad. Nyligen har det skett betydande framsteg kring integritetsbevarande maskininlärningstekniker som differentiell integritet och federerad inlärning.
PyTorch Opacus
Differentiellt privat modellträning säkerställer att individuella poster samtidigt som du lär dig användbar information om datasetet som helhet.

Och PyTorch Opacus låter dig träna modeller med differentiell integritet. För att lära dig hur man implementerar differentiellt privat modellträning, kolla in introduktionen till Opacus.
TensorFlow Federated
Federerat lärande tar bort behovet av en centraliserad datainsamlings- och bearbetningsenhet. I en förenad miljö lämnar data aldrig ägaren eller lokalen. Därför underlättar federerat lärande bättre datastyrning.
TensorFlow Federated tillhandahåller funktionalitet för att träna maskininlärningsmodeller på decentraliserad data.
#5. Enkel inlärning
PyTorch är ett Pythonic djupinlärningsramverk. Att koda bekvämt i PyTorch kräver mellanliggande Python-färdigheter, inklusive ett bra grepp om objektorienterade programmeringskoncept som arv.
Å andra sidan, med TensorFlow, kan du använda Keras API. Detta högnivå-API abstraherar bort några av implementeringsdetaljerna på låg nivå. Som ett resultat, om du precis har börjat med att bygga modeller för djupinlärning, kanske du tycker att Keras är lättare att använda.
PyTorch vs. TensorFlow: En översikt
Hittills har vi diskuterat funktionerna i PyTorch och TensorFlow. Här är en omfattande jämförelse:
FeaturePyTorchTensorFlowDatauppsättningar och förtränade modeller i torchtext, touch-ljud och torchvisionBibliotek med datauppsättningar och förtränade modellerDatauppsättningar och förtränade modeller i torchtext, torchaudio och torchvisionDeploymentTorchServe för att betjäna maskininlärningsmodeller TensorFlow-modeller TensorFlow-Servning och förtränade modeller för inlärningsmodeller TensorFlow-Servning och förutbildade modeller. Bevara Machine LearningPyTorch Opacus för differentiellt privat modellträning
Lärresurser
Till sist, låt oss avsluta vår diskussion med att gå igenom några användbara resurser för att lära oss PyTorch och TensorFlow. Det här är inte en uttömmande lista utan en lista över körsbärsplockade resurser som kommer att få dig att snabbt komma igång med dessa ramverk.
#1. Deep Learning med PyTorch: En 60-minuters blixt
Den 60 minuter långa blitzhandledningen på PyTorchs officiella webbplats är en utmärkt nybörjarvänlig resurs för att lära dig PyTorch.

Denna handledning hjälper dig att komma igång med Pytorchs grunder som tensorer och autografer, och bygga ett grundläggande neuralt nätverk för bildklassificering med PyTorch.
#2. Deep Learning med PyTorch: Noll till GAN

Deep Learning with PyTorch: Zero to GANs av Jovian.ai är en annan omfattande resurs för att lära sig djupinlärning med PyTorch. Under cirka sex veckor kan du lära dig:
- PyTorch grunderna: tensorer och gradienter
- Linjär regression i PyTorch
- Bygga djupa neurala nätverk, ConvNets och ResNets i PyTorch
- Bygga generativa kontradiktoriska nätverk (GAN)
#3. TensorFlow 2.0 komplett kurs
Om du är ute efter att få kläm på TensorFlow, kommer TensorFlow 2.0 Complete Course på freeCodeCamps communitykanal att vara till hjälp.

#4. TensorFlow – Python Deep Learning Neural Network API av DeepLizard
En annan bra TensorFlow-kurs för nybörjare är från DeepLizard. I den här nybörjarvänliga TensorFlow-kursen lär du dig grunderna för djupinlärning, inklusive:
- Laddar och förbearbetar dataset
- Bygga vanilj neurala nätverk
- Bygga konvolutionella neurala nätverk (CNN)
Slutsats
Sammanfattningsvis hjälpte den här artikeln dig att få en översikt över PyTorch och TensorFlow på hög nivå. Att välja det optimala ramverket beror på projektet du arbetar med. Dessutom skulle detta kräva att du tar hänsyn till stödet för implementering, förklarabarhet och mer.
Är du en Python-programmerare som vill lära dig dessa ramverk? Om så är fallet kan du överväga att utforska en eller flera av resurserna som delas ovan.
Och om du är intresserad av NLP, kolla in den här listan över kurser i naturlig språkbehandling att ta. Lycka till med lärandet!