
Lär dig allt du behöver veta om utforskande dataanalys, en kritisk process som används för att upptäcka trender och mönster och sammanfatta datamängder med hjälp av statistiska sammanfattningar och grafiska representationer.
Som alla projekt är ett datavetenskapligt projekt en lång process som kräver tid, bra organisation och noggrann respekt för flera steg. Exploratory data analysis (EDA) är ett av de viktigaste stegen i denna process.
Därför kommer vi i den här artikeln kort att titta på vad explorativ dataanalys är och hur du kan utföra den med R!
Innehållsförteckning
Vad är Exploratory Data Analysis?
Explorativ dataanalys undersöker och studerar egenskaperna hos en datamängd innan den skickas till en ansökan, oavsett om det är enbart affärsmässigt, statistiskt eller maskininlärning.
Denna sammanfattning av informationens karaktär och dess huvudsakliga särdrag görs vanligtvis med visuella metoder, såsom grafiska representationer och tabeller. Övningen genomförs i förväg just för att bedöma potentialen för dessa data, som kommer att få en mer komplex behandling i framtiden.
EDA tillåter därför:
- Formulera hypoteser för användningen av denna information;
- Utforska dolda detaljer i datastrukturen;
- Identifiera saknade värden, extremvärden eller onormala beteenden;
- Upptäck trender och relevanta variabler som helhet;
- Kasta bort irrelevanta variabler eller variabler som är korrelerade med andra;
- Bestäm den formella modelleringen som ska användas.
Vad är skillnaden mellan beskrivande och utforskande dataanalys?
Det finns två typer av dataanalys, deskriptiv analys och explorativ dataanalys, som går hand i hand, trots att de har olika mål.
Medan den första fokuserar på att beskriva beteendet hos variabler, till exempel medelvärde, median, läge, etc.
Den explorativa analysen syftar till att identifiera samband mellan variabler, extrahera preliminära insikter och styra modelleringen till de vanligaste maskininlärningsparadigmen: klassificering, regression och klustring.
Gemensamt kan båda handla om grafisk representation; dock är det endast explorativ analys som syftar till att ge handlingsbara insikter, det vill säga insikter som framkallar handling från beslutsfattaren.
Slutligen, medan explorativ dataanalys försöker lösa problem och komma med lösningar som kommer att styra modelleringsstegen, syftar beskrivande analys, som namnet antyder, endast till att producera en detaljerad beskrivning av datasetet i fråga.
Beskrivande analysUtforskande dataanalys Analyserar beteende Analyserar beteende och relation Ger en sammanfattning Leder till specifikationer och åtgärder Organiserar data i tabeller och grafer Organiserar data i tabeller och graferHar inte betydande förklaringskraftHar betydande förklaringsförmåga
Några praktiska användningsfall av EDA
#1. Digital marknadsföring
Digital marknadsföring har utvecklats från en kreativ process till en datadriven process. Marknadsorganisationer använder utforskande dataanalys för att fastställa resultaten av kampanjer eller ansträngningar och för att vägleda konsumentinvesteringar och inriktningsbeslut.
Demografiska studier, kundsegmentering och andra tekniker tillåter marknadsförare att använda stora mängder konsumentköp, undersökningar och paneldata för att förstå och kommunicera strategimarknadsföring.
Undersökande webbanalys gör det möjligt för marknadsförare att samla in information på sessionsnivå om interaktioner på en webbplats. Google Analytics är ett exempel på ett gratis och populärt analysverktyg som marknadsförare använder för detta ändamål.
Undersökande tekniker som ofta används i marknadsföring inkluderar modellering av marknadsföringsmix, prissättnings- och marknadsföringsanalyser, försäljningsoptimering och utforskande kundanalys, t.ex. segmentering.
#2. Exploratory Portfolio Analysis
En vanlig tillämpning av explorativ dataanalys är explorativ portföljanalys. En bank eller lånebyrå har en samling konton av varierande värde och risk.
Konton kan skilja sig åt beroende på innehavarens sociala status (rik, medelklass, fattig, etc.), geografiskt läge, nettoförmögenhet och många andra faktorer. Långivaren måste balansera avkastningen på lånet med risken för fallissemang för varje lån. Frågan blir då hur man värderar portföljen som helhet.
Det lägsta risklånet kan vara för mycket rika människor, men det finns ett mycket begränsat antal rika människor. Å andra sidan kan många fattiga låna ut, men med större risk.
Den explorativa dataanalyslösningen kan kombinera tidsserieanalys med många andra problem för att bestämma när man ska låna ut pengar till dessa olika segment av låntagare eller utlåningstakten. Ränta debiteras medlemmar i ett portföljsegment för att täcka förluster bland medlemmarna i det segmentet.
#3. Utforskande riskanalys
Prediktiva modeller inom bankväsendet utvecklas för att ge säkerhet om riskpoäng för enskilda kunder. Kreditpoäng är utformade för att förutsäga en individs brottsliga beteende och används ofta för att bedöma varje sökandes kreditvärdighet.
Dessutom genomförs riskanalyser inom den vetenskapliga världen och försäkringsbranschen. Det används också i stor utsträckning i finansiella institutioner som online-betalningsgatewayföretag för att analysera om en transaktion är äkta eller bedräglig.
För detta ändamål använder de kundens transaktionshistorik. Det är vanligare vid kreditkortsköp; när det uppstår en plötslig ökning i kundtransaktionsvolymen får kunden ett bekräftelsesamtal om han initierade transaktionen. Det hjälper också till att minska förluster på grund av sådana omständigheter.
Exploratory Data Analysis med R
Det första du behöver för att utföra EDA med R är att ladda ner R base och R Studio (IDE), följt av att installera och ladda följande paket:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
För den här handledningen kommer vi att använda en ekonomisk datauppsättning som är inbyggd med R och tillhandahåller årliga ekonomiska indikatorer för den amerikanska ekonomin, och ändra dess namn till econ för enkelhetens skull:
econ <- ggplot2::economics
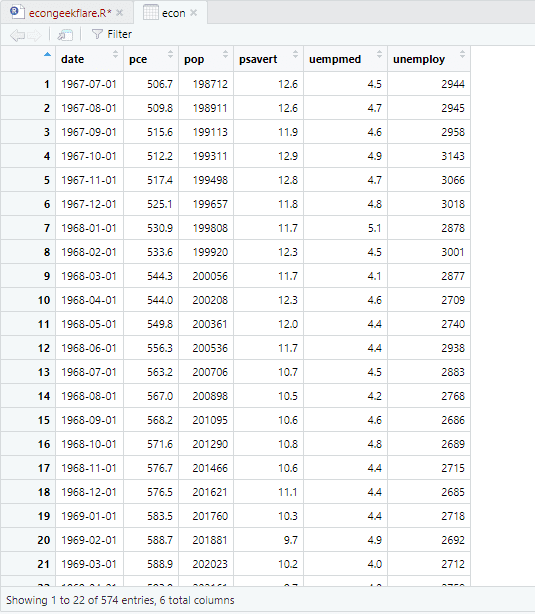
För att utföra den beskrivande analysen kommer vi att använda paketet skimr, som beräknar denna statistik på ett enkelt och välpresenterat sätt:
#Descriptive Analysis skimr::skim(econ)

Du kan också använda sammanfattningsfunktionen för beskrivande analys:
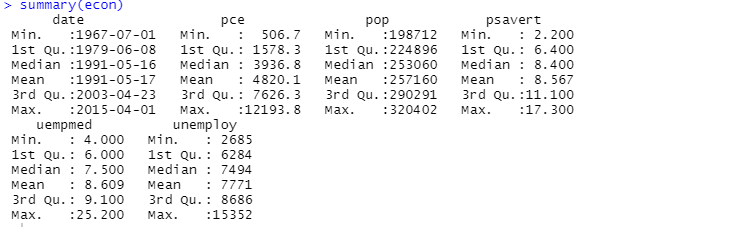
Här visar den beskrivande analysen 547 rader och 6 kolumner i datasetet. Minimivärdet är för 1967-07-01, och det högsta är för 2015-04-01. På samma sätt visar den också medelvärdet och standardavvikelsen.
Nu har du en grundläggande uppfattning om vad som finns inuti econ-datauppsättningen. Låt oss rita ett histogram av variabeln uempmed för att bättre titta på data:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
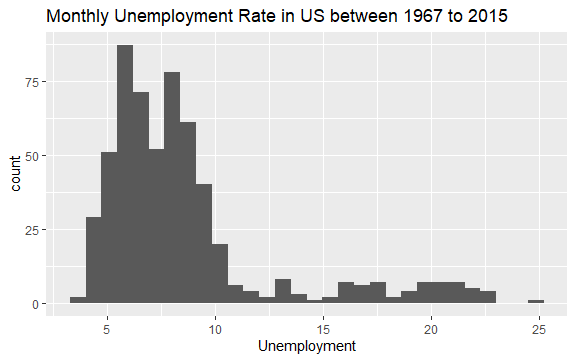
Histogrammets fördelning visar att det har en långsträckt svans till höger; det vill säga, det finns möjligen några observationer av denna variabel med mer ”extrema” värden. Frågan uppstår: under vilken period ägde dessa värden rum och vad är trenden för variabeln?
Det mest direkta sättet att identifiera trenden för en variabel är genom ett linjediagram. Nedan genererar vi ett linjediagram och lägger till en utjämningslinje:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
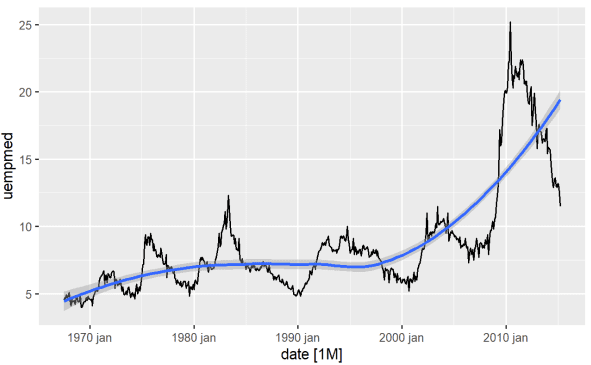
Med hjälp av denna graf kan vi identifiera att det under den senaste perioden, i de senaste observationerna från 2010, finns en tendens till en ökning av arbetslösheten, som överträffar den historia som observerats under tidigare decennier.
En annan viktig punkt, särskilt i ekonometriska modelleringssammanhang, är seriens stationaritet; det vill säga är medelvärdet och variansen konstanta över tid?
När dessa antaganden inte är sanna i en variabel säger vi att serien har en enhetsrot (icke-stationär) så att de stötar som variabeln utsätts för genererar en permanent effekt.
Det verkar ha varit fallet för variabeln i fråga, arbetslöshetens varaktighet. Vi har sett att variabelns fluktuationer har förändrats avsevärt, vilket har starka implikationer relaterade till ekonomiska teorier som handlar om cykler. Men, med avvikelse från teorin, hur kontrollerar vi praktiskt om variabeln är stationär?
Prognospaketet har en utmärkt funktion som gör det möjligt att tillämpa tester, såsom ADF, KPSS och andra, som redan returnerar antalet skillnader som krävs för att serien ska vara stationär:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Här visar p-värdet större än 0,05 att data är icke-stationära.
En annan viktig fråga i tidsserier är identifieringen av möjliga korrelationer (det linjära sambandet) mellan de fördröjda värdena i serien. ACF- och PACF-korrelogrammen hjälper till att identifiera den.
Eftersom serien inte har säsongsvariationer utan har en viss trend tenderar de initiala autokorrelationerna att vara stora och positiva eftersom observationerna nära i tid också ligger nära i värde.
Således tenderar autokorrelationsfunktionen (ACF) för en trendad tidsserie att ha positiva värden som sakta minskar när fördröjningarna ökar.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
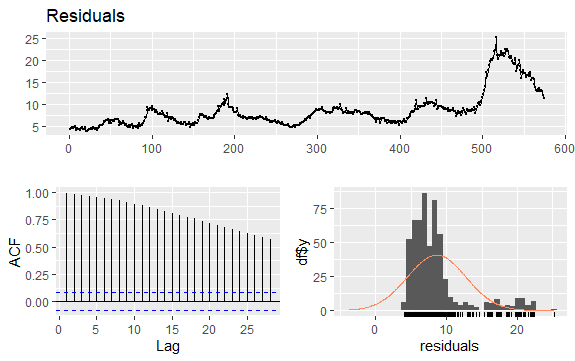
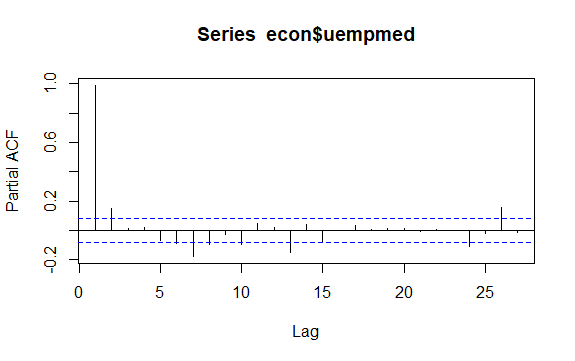
Slutsats
När vi får tag på data som är mer eller mindre rena, det vill säga redan rensade, frestas vi genast att dyka in i modellkonstruktionsstadiet för att rita de första resultaten. Du måste motstå denna frestelse och börja göra utforskande dataanalys, vilket är enkelt men ändå hjälper oss att dra kraftfulla insikter i datan.
Du kan också utforska några bästa resurser för att lära dig statistik för datavetenskap.