

Linux uniq-kommandot går igenom dina textfiler och letar efter unika eller dubbla rader. I den här guiden tar vi upp dess mångsidighet och funktioner, samt hur du kan få ut det mesta av detta smarta verktyg.
Innehållsförteckning
Hitta matchande textrader på Linux
Det unika kommandot är snabb, flexibel och bra på vad den gör. Men som många Linux-kommandon har den några egenheter – vilket är bra, så länge du känner till dem. Om du tar steget utan lite insiderkunskap kan du mycket väl bli kvar och klia dig i huvudet åt resultatet. Vi kommer att påpeka dessa egenheter när vi går.
Uniq-kommandot är perfekt för dem i det målmedvetna, designade-att-göra-en-sak-och-göra-det-bra-lägret. Därför är den också särskilt väl lämpad att arbeta med pipes och spela sin roll i kommandopipelines. En av dess mest frekventa medarbetare är sortering eftersom uniq måste ha sorterad input att arbeta på.
Låt oss elda upp det!
Kör uniq utan alternativ
Vi har en textfil som innehåller texten till Robert Johnsons låt Jag tror att jag ska damma av min kvast. Låt oss se vad det är för unikt med det.
Vi skriver följande för att överföra utgången till mindre:
uniq dust-my-broom.txt | less

Vi får hela låten, inklusive dubbletter av rader, på mindre:
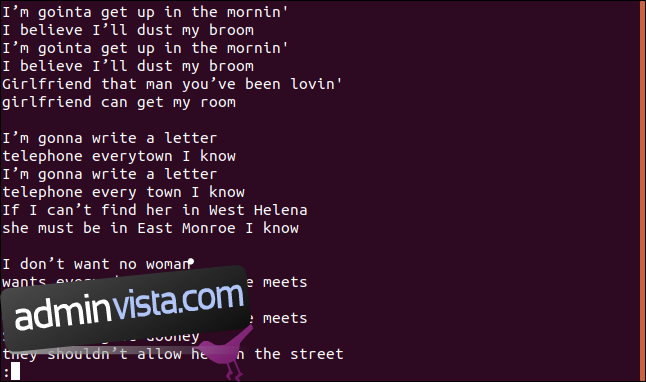
Det verkar inte vara varken de unika linjerna eller dubbla linjerna.
Rätt – för det här är den första egenheten. Om du kör uniq utan alternativ, beter sig det som om du använde alternativet -u (unika linjer). Detta säger till uniq att endast skriva ut de unika raderna från filen. Anledningen till att du ser dubbletter av linjer är att för att uniq ska betrakta en linje som en dubblett måste den ligga intill dess dubblett, vilket är där sortering kommer in.
När vi sorterar filen grupperar den dubblettraderna och uniq behandlar dem som dubbletter. Vi kommer att använda sortering på filen, skicka den sorterade utdata till uniq och sedan flytta den slutliga utdata till less.
För att göra det skriver vi följande:
sort dust-my-broom.txt | uniq | less

En sorterad lista med rader visas i mindre.
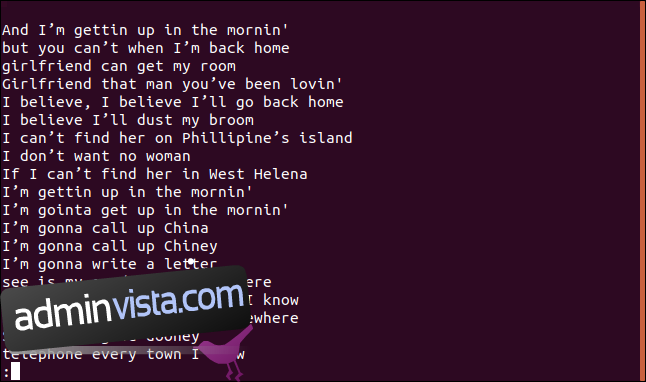
Raden, ”I believe I’ll dust my broom,” förekommer definitivt i låten mer än en gång. Faktum är att det upprepas två gånger inom låtens första fyra rader.
Så varför visas det i en lista med unika rader? Eftersom första gången en rad visas i filen är den unik; endast de efterföljande posterna är dubbletter. Du kan se det som att lista den första förekomsten av varje unik rad.
Låt oss använda sortera igen och omdirigera utdata till en ny fil. På så sätt behöver vi inte använda sortering i varje kommando.
Vi skriver följande kommando:
sort dust-my-broom.txt > sorted.txt
 sorted.txt” kommandot i ett terminalfönster.’ width=”646″ height=”57″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
sorted.txt” kommandot i ett terminalfönster.’ width=”646″ height=”57″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
Nu har vi en försorterad fil att arbeta med.
Räknar dubbletter
Du kan använda alternativet -c (count) för att skriva ut antalet gånger varje rad förekommer i en fil.
Skriv följande kommando:
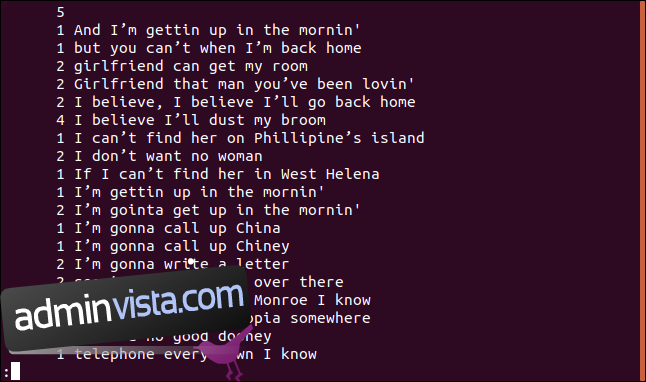
uniq -c sorted.txt | less

Varje rad börjar med antalet gånger den raden förekommer i filen. Du kommer dock att märka att den första raden är tom. Detta talar om för dig att det finns fem tomma rader i filen.
Om du vill att utdata sorteras i numerisk ordning kan du mata ut utdata från uniq till sortering. I vårt exempel kommer vi att använda alternativen -r (omvänd) och -n (numerisk sortering) och överföra resultaten till mindre.
Vi skriver följande:
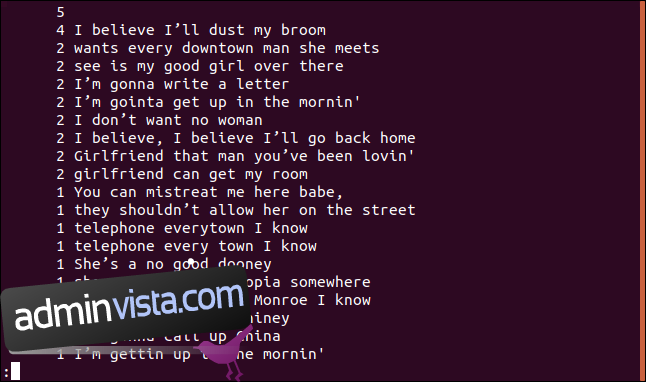
uniq -c sorted.txt | sort -rn | less

Listan sorteras i fallande ordning baserat på frekvensen av varje rads utseende.
Lista endast dubbletter av rader
Om du bara vill se raderna som upprepas i en fil kan du använda alternativet -d (upprepad). Oavsett hur många gånger en rad dupliceras i en fil, listas den bara en gång.
För att använda det här alternativet skriver vi följande:
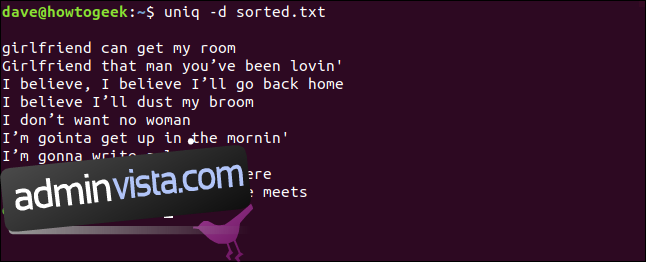
uniq -d sorted.txt

De dubblerade raderna är listade åt oss. Du kommer att märka den tomma raden överst, vilket betyder att filen innehåller dubbla tomma rader – det är inte ett utrymme som lämnas av uniq för att kosmetiskt kompensera för listningen.
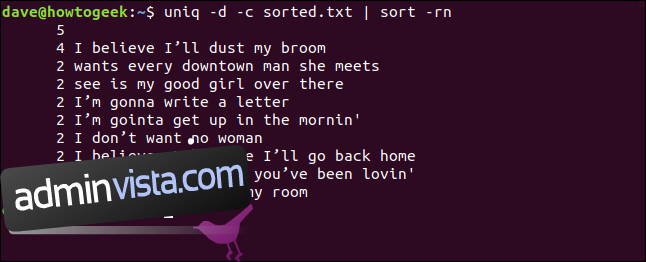
Vi kan också kombinera alternativen -d (upprepad) och -c (räkna) och skicka utdata genom sortering. Detta ger oss en sorterad lista över de rader som visas minst två gånger.
Skriv följande för att använda det här alternativet:
uniq -d -c sorted.txt | sort -rn
Lista alla dubblerade rader
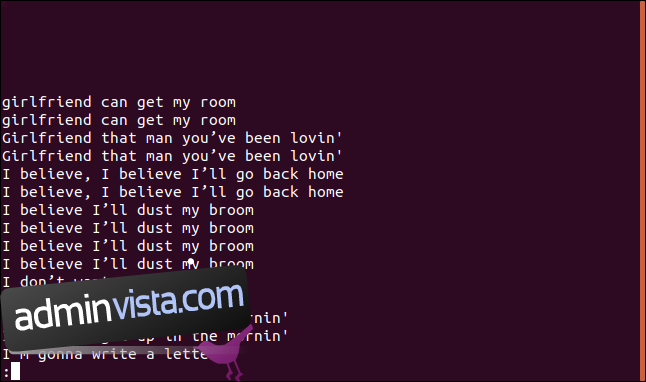
Om du vill se en lista över varje duplicerad rad, samt en post för varje gång en rad visas i filen, kan du använda alternativet -D (alla duplicerade rader).
För att använda det här alternativet skriver du följande:
uniq -D sorted.txt | less

Listan innehåller en post för varje duplicerad rad.
Om du använder alternativet –grupp, skrivs varje duplicerad rad ut med en tom rad antingen före (prepend) eller efter varje grupp (lägg till), eller både före och efter (båda) varje grupp.
Vi använder append som vår modifierare, så vi skriver följande:
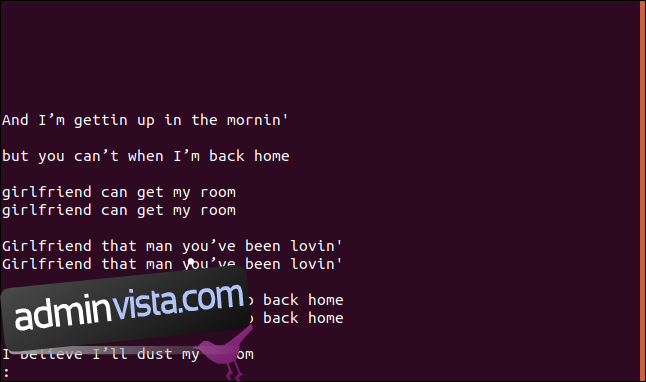
uniq --group=append sorted.txt | less

Grupperna är åtskilda av tomma rader för att göra dem lättare att läsa.
Kontrollera ett visst antal tecken
Som standard kontrollerar uniq hela längden på varje rad. Om du vill begränsa kontrollerna till ett visst antal tecken kan du dock använda alternativet -w (kontrollera tecken).
I det här exemplet upprepar vi det sista kommandot, men begränsar jämförelserna till de tre första tecknen. För att göra det skriver vi följande kommando:
uniq -w 3 --group=append sorted.txt | less

Resultaten och grupperingarna vi får är ganska olika.
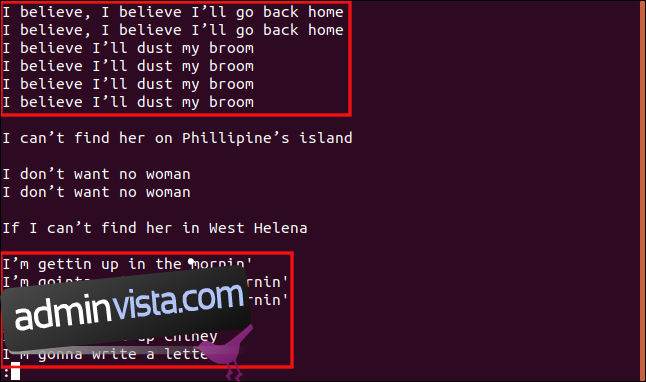
Alla rader som börjar med ”I b” grupperas tillsammans eftersom de delarna av raderna är identiska, så de anses vara dubbletter.
På samma sätt behandlas alla rader som börjar med ”Jag är” som dubbletter, även om resten av texten är annorlunda.
Ignorera ett visst antal tecken
Det finns vissa fall där det kan vara fördelaktigt att hoppa över ett visst antal tecken i början av varje rad, till exempel när rader i en fil är numrerade. Eller säg att du behöver uniq för att hoppa över en tidsstämpel och börja kontrollera raderna från tecken sex istället för från det första tecknet.
Nedan finns en version av vår sorterade fil med numrerade rader.
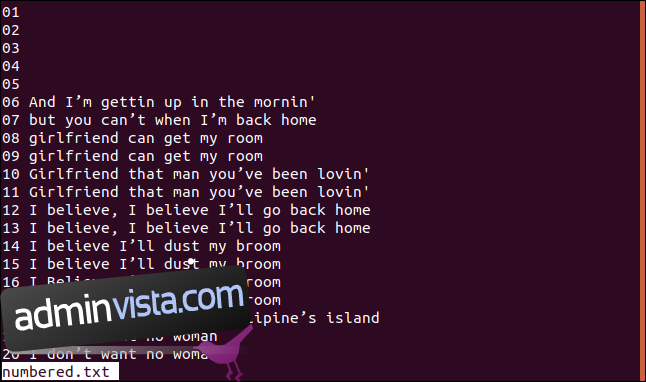
Om vi vill att uniq ska starta sina jämförelsekontroller vid tecken tre, kan vi använda alternativet -s (hoppa över tecken) genom att skriva följande:
uniq -s 3 -d -c numbered.txt
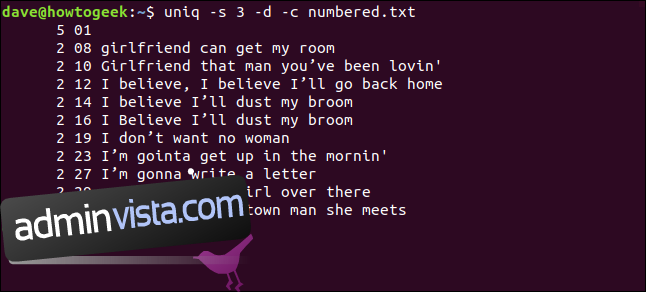
Raderna upptäcks som dubbletter och räknas korrekt. Observera att radnumren som visas är de för den första förekomsten av varje dubblett.
Du kan också hoppa över fält (en rad tecken och lite blanksteg) istället för tecken. Vi använder alternativet -f (fält) för att tala om för uniq vilka fält som ska ignoreras.
Vi skriver följande för att säga till uniq att ignorera det första fältet:
uniq -f 1 -d -c numbered.txt
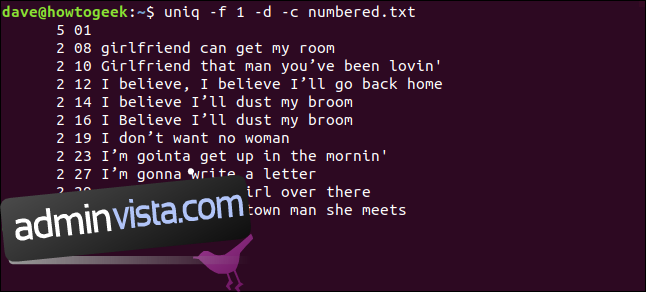
Vi får samma resultat som vi fick när vi sa till uniq att hoppa över tre tecken i början av varje rad.
Ignorerar fallet
Som standard är uniq skiftlägeskänsligt. Om samma bokstav visas med kapitlet och med gemener, anser uniq att raderna är olika.
Kolla till exempel utdata från följande kommando:
uniq -d -c sorted.txt | sort -rn
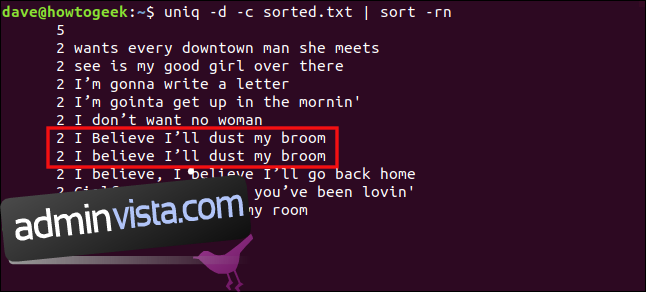
Raderna ”I Believe I’ll dust my broom” och ”I believe I’ll dust my broom” behandlas inte som dubbletter på grund av skillnaden i skiftläge på ”B” i ”tro”.
Om vi inkluderar alternativet -i (ignorera skiftläge) kommer dessa rader att behandlas som dubbletter. Vi skriver följande:
uniq -d -c -i sorted.txt | sort -rn
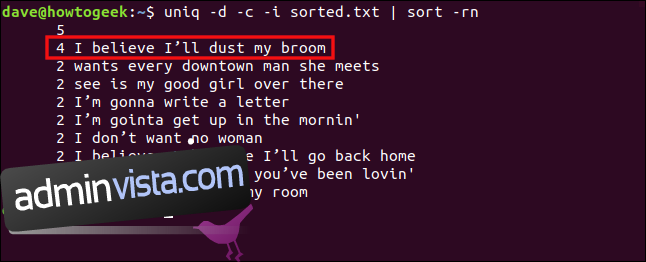
Raderna behandlas nu som dubbletter och grupperas tillsammans.
Linux ställer en mängd specialverktyg till ditt förfogande. Liksom många av dem är uniq inte ett verktyg du kommer att använda varje dag.
Det är därför en stor del av att bli skicklig i Linux är att komma ihåg vilket verktyg som kommer att lösa ditt nuvarande problem, och var du kan hitta det igen. Om du övar kommer du dock vara på god väg.
Eller så kan du alltid bara söka How-To Geek – vi har förmodligen en artikel om det.