

Linux grep-kommandot är ett sträng- och mönstermatchningsverktyg som visar matchande rader från flera filer. Det fungerar också med utdata från andra kommandon. Vi visar dig hur.
Innehållsförteckning
Historien bakom grep
Kommandot grep är känt i Linux och Unix cirklar av tre skäl. För det första är det oerhört användbart. För det andra rikedom av alternativ kan vara överväldigande. För det tredje skrevs den över en natt för att tillfredsställa ett särskilt behov. De två första är pang på; den tredje är något av.
Ken Thompson hade extraherat sökfunktionerna för reguljära uttryck från ed-editorn (uttalas ee-dee) och skapade ett litet program – för eget bruk – för att söka igenom textfiler. Hans avdelningschef kl Bell Labs, Doug Mcilroykontaktade Thompson och beskrev problemet en av hans kollegor, Lee McMahonstod inför.
McMahon försökte identifiera författarna till den Federalistiska tidningar genom textanalys. Han behövde ett verktyg som kunde söka efter fraser och strängar i textfiler. Thompson tillbringade ungefär en timme den kvällen för att göra sitt verktyg till ett allmänt verktyg som kunde användas av andra och döpte om det till grep. Han tog namnet från ed-kommandosträngen g/re/p , som översätts som ”global reguljära uttryckssökning.”
Du kan se Thompson prata till Brian Kernighan om greps födelse.
Enkla sökningar med grep
För att söka efter en sträng i en fil, skicka söktermen och filnamnet på kommandoraden:

Matchande linjer visas. I det här fallet är det en enda rad. Den matchande texten är markerad. Detta beror på att grep på de flesta distributioner alias till:
alias grep='grep --colour=auto'
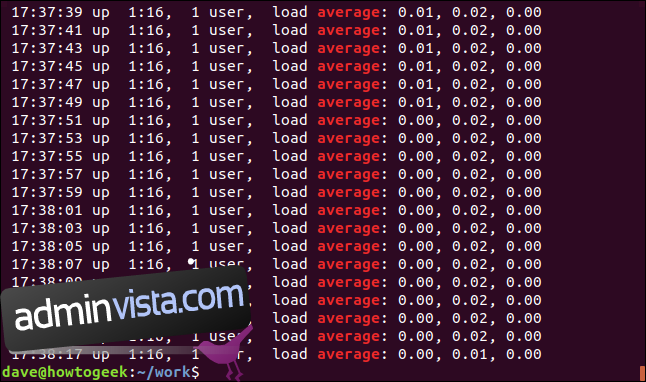
Låt oss titta på resultat där det finns flera rader som matchar. Vi letar efter ordet ”Genomsnitt” i en programloggfil. Eftersom vi inte kan komma ihåg om ordet är med gemener i loggfilen, använder vi alternativet -i (ignorera skiftläge):
grep -i Average geek-1.log

Varje matchande rad visas, med den matchande texten markerad i var och en.
Vi kan visa de icke-matchande raderna genom att använda alternativet -v (invertera matchning).
grep -v Mem geek-1.log

Det finns ingen markering eftersom dessa är de icke-matchande raderna.
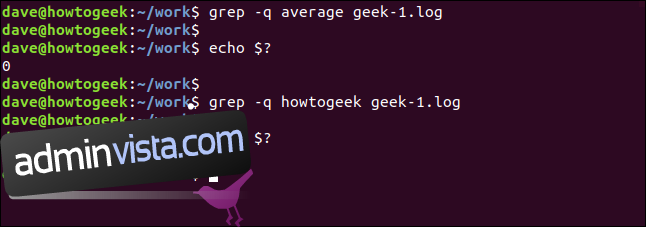
Vi kan få grep att vara helt tyst. Resultatet skickas till skalet som ett returvärde från grep. Ett resultat av noll betyder att strängen hittades, och ett resultat av ett betyder att den inte hittades. Vi kan kontrollera returkoden med hjälp av $? speciella parametrar:
grep -q average geek-1.log
echo $?
grep -q wdzwdz geek-1.log
echo $?
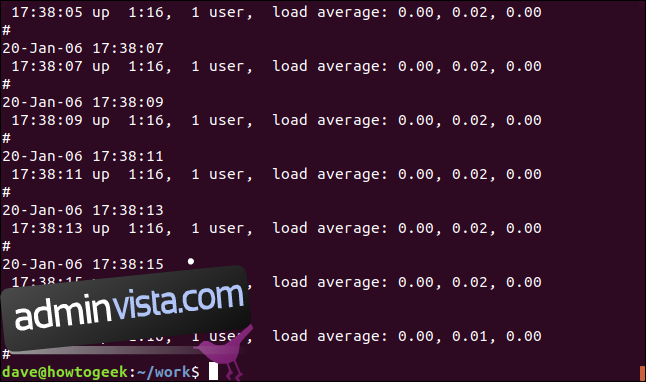
Rekursiva sökningar med grep
För att söka igenom kapslade kataloger och underkataloger, använd alternativet -r (rekursivt). Observera att du inte anger ett filnamn på kommandoraden, du måste ange en sökväg. Här söker vi i den aktuella katalogen ”.” och eventuella underkataloger:
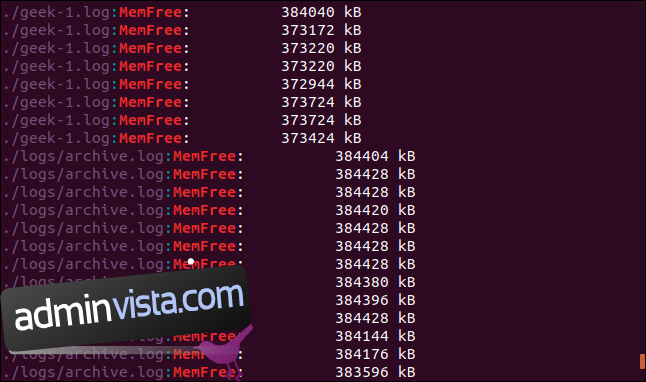
grep -r -i memfree .

Utdata inkluderar katalogen och filnamnet för varje matchande rad.
Vi kan få grep att följa symboliska länkar genom att använda alternativet -R (rekursiv dereference). Vi har en symbolisk länk i den här katalogen, kallad logs-folder. Den pekar på /home/dave/logs.
ls -l logs-folder

Låt oss upprepa vår senaste sökning med alternativet -R (rekursiv dereference):
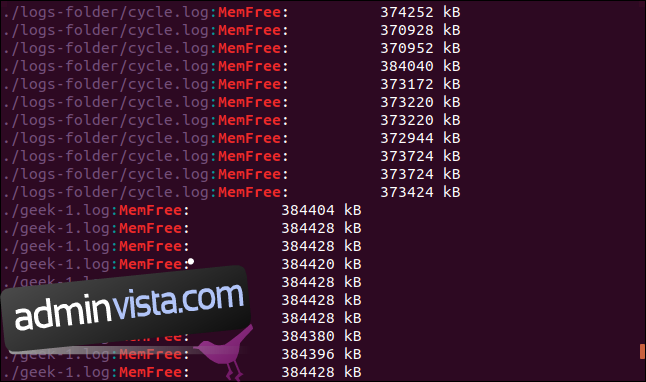
grep -R -i memfree .

Den symboliska länken följs och katalogen den pekar på söks också av grep.
Söker efter hela ord
Som standard kommer grep att matcha en rad om sökmålet visas någonstans på den raden, inklusive inuti en annan sträng. Titta på det här exemplet. Vi ska söka efter ordet ”gratis”.
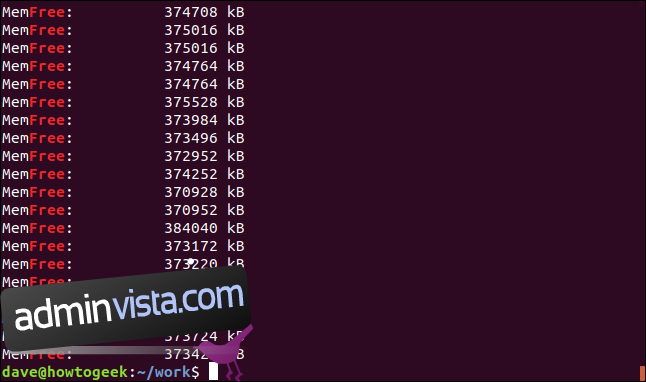
grep -i free geek-1.log

Resultaten är rader som har strängen ”fri” i sig, men de är inte separata ord. De är en del av strängen ”MemFree.”
För att tvinga grep att bara matcha separata ”ord”, använd alternativet -w (ord regexp).
grep -w -i free geek-1.log
echo $?
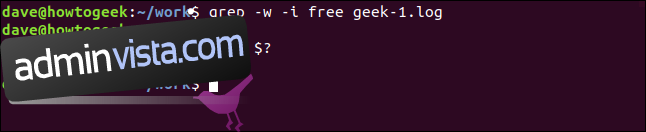
Den här gången finns det inga resultat eftersom söktermen ”gratis” inte visas i filen som ett separat ord.
Använda flera söktermer
Alternativet -E (extended regexp) låter dig söka efter flera ord. (Alternativet -E ersätter det utfasade egrep version av grep.)
Detta kommando söker efter två söktermer, ”genomsnittlig” och ”memfree”.
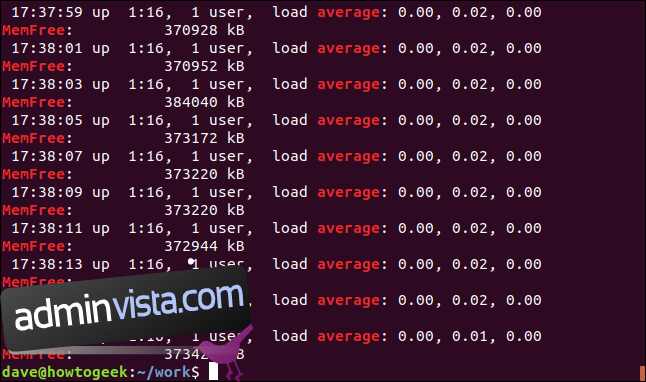
grep -E -w -i "average|memfree" geek-1.log

Alla matchande rader visas för var och en av söktermerna.
Du kan också söka efter flera termer som inte nödvändigtvis är hela ord, men de kan också vara hela ord.
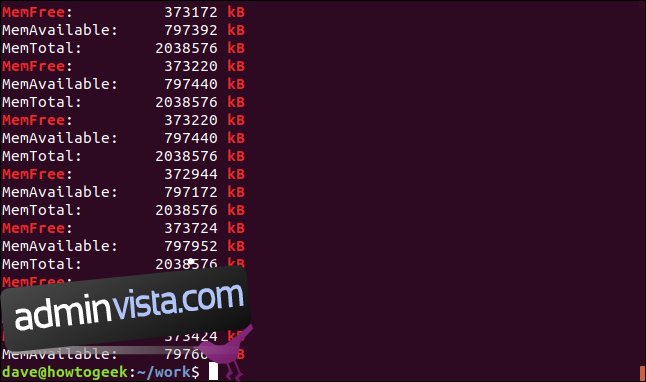
Alternativet -e (mönster) låter dig använda flera sökord på kommandoraden. Vi använder funktionen för reguljära uttrycksparenteser för att skapa ett sökmönster. Det säger åt grep att matcha något av tecknen som finns inom parentes ”[].” Detta betyder att grep kommer att matcha antingen ”kB” eller ”KB” när den söker.

Båda strängarna är matchade, och i själva verket innehåller vissa rader båda strängarna.
Matchande linjer exakt
-x (line regexp) kommer bara att matcha rader där hela raden matchar söktermen. Låt oss söka efter en datum- och tidsstämpel som vi vet bara visas en gång i loggfilen:
grep -x "20-Jan--06 15:24:35" geek-1.log

Den enstaka raden som matchar hittas och visas.
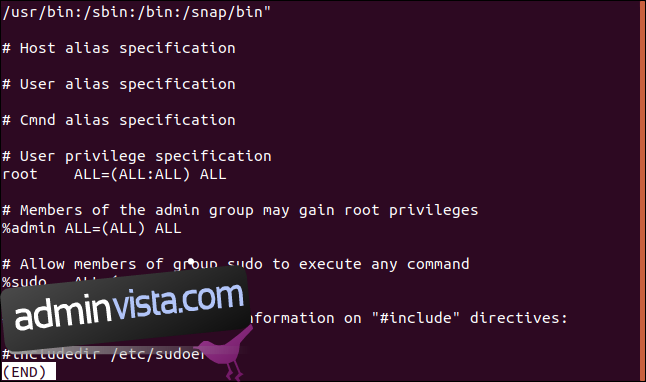
Motsatsen till det är att bara visa de linjer som inte matchar. Detta kan vara användbart när du tittar på konfigurationsfiler. Kommentarer är bra, men ibland är det svårt att se de faktiska inställningarna bland dem alla. Här är filen /etc/sudoers:
Vi kan effektivt filtrera bort kommentarsraderna så här:
sudo grep -v "https://www.wdzwdz.com/496056/how-to-use-the-grep-command-on-linux/#" /etc/sudoers
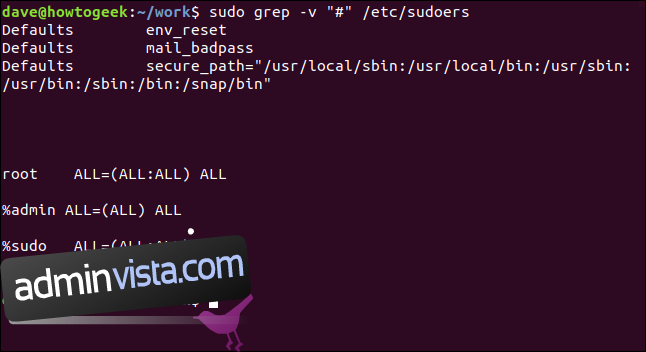
Det är mycket lättare att analysera.
Visar endast matchande text
Det kan finnas ett tillfälle då du inte vill se hela matchande rad, bara den matchande texten. Alternativet -o (endast matchande) gör just det.
grep -o MemFree geek-1.log

Visningen reduceras till att bara visa texten som matchar söktermen, istället för hela matchande raden.

Räkna med grep
grep handlar inte bara om text, det kan också ge numerisk information. Vi kan få grep att räknas för oss på olika sätt. Om vi vill veta hur många gånger en sökterm förekommer i en fil kan vi använda alternativet -c (count).
grep -c average geek-1.log

grep rapporterar att söktermen förekommer 240 gånger i den här filen.
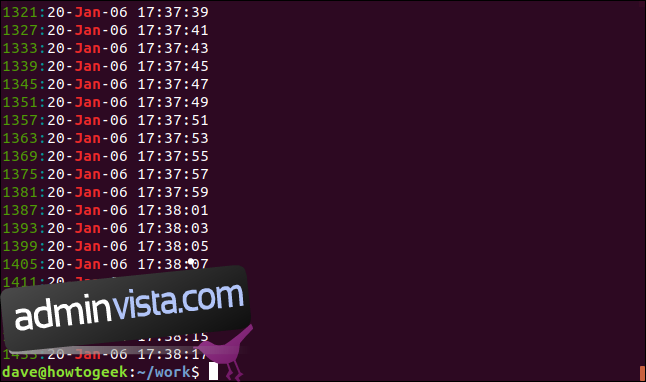
Du kan få grep att visa radnumret för varje matchande rad genom att använda alternativet -n (radnummer).
grep -n Jan geek-1.log

Radnumret för varje matchande rad visas i början av raden.
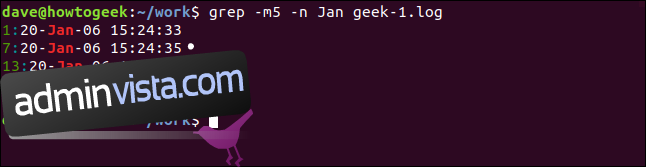
För att minska antalet resultat som visas, använd alternativet -m (max antal). Vi kommer att begränsa utdata till fem matchande rader:
grep -m5 -n Jan geek-1.log
Lägger till sammanhang
Att kunna se några ytterligare rader – eventuellt icke-matchande rader – för varje matchande rad är ofta användbart. det kan hjälpa dig att skilja vilka av de matchade linjerna som är de du är intresserad av.
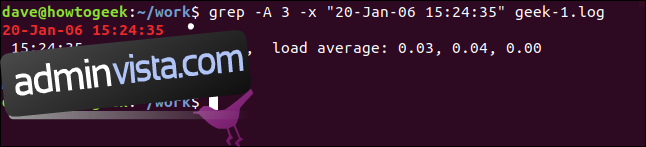
För att visa några rader efter den matchande raden, använd alternativet -A (efter kontext). Vi ber om tre rader i detta exempel:
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
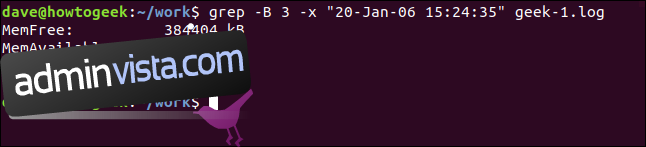
För att se några linjer från före den matchande raden, använd alternativet -B (sammanhang före).
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
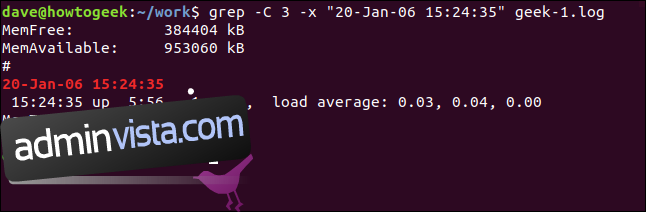
Och för att inkludera linjer från före och efter den matchande raden använd alternativet -C (sammanhang).
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
Visar matchande filer
För att se namnen på filerna som innehåller söktermen, använd alternativet -l (filer med matchning). För att ta reda på vilka C-källkodsfiler som innehåller referenser till sl.h-huvudfilen, använd det här kommandot:
grep -l "sl.h" *.c

Filnamnen är listade, inte de matchande raderna.

Och naturligtvis kan vi leta efter filer som inte innehåller söktermen. Alternativet -L (filer utan matchning) gör just det.
grep -L "sl.h" *.c

Start och slut på rader
Vi kan tvinga grep att bara visa matchningar som är antingen i början eller slutet av en rad. Operatorn ”^” för reguljära uttryck matchar början på en rad. Praktiskt taget alla rader i loggfilen kommer att innehålla mellanslag, men vi ska söka efter rader som har ett mellanslag som sitt första tecken:
grep "^ " geek-1.log

Raderna som har ett mellanslag som första tecken – i början av raden – visas.
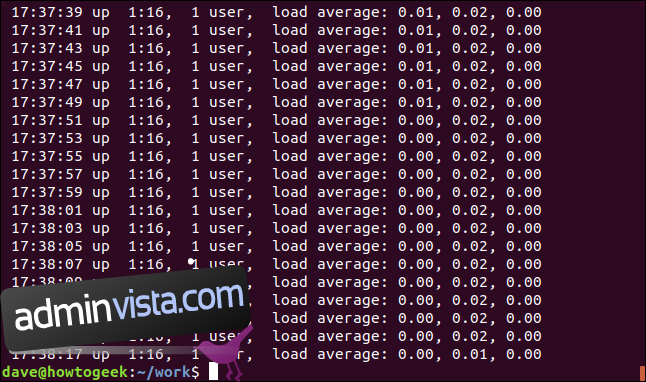
För att matcha slutet av raden, använd ”$” reguljära uttrycksoperator. Vi ska söka efter rader som slutar med ”00”.
grep "00$" geek-1.log

Displayen visar raderna som har ”00” som sina sista tecken.
Använda Pipes med grep
Naturligtvis kan du skicka indata till grep , skicka utdata från grep till ett annat program och ha grep inbäddat i mitten av en rörkedja.
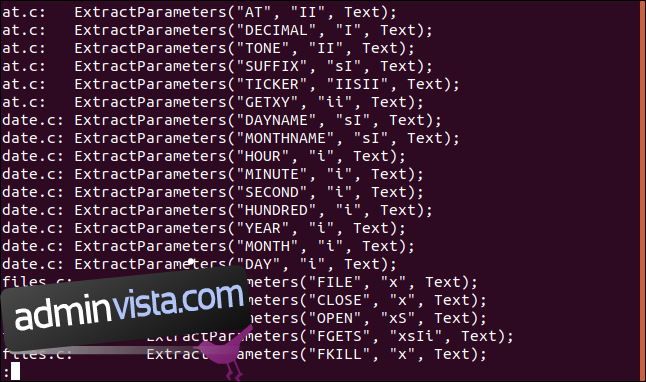
Låt oss säga att vi vill se alla förekomster av strängen ”ExtractParameters” i våra C-källkodsfiler. Vi vet att det kommer att bli en hel del, så vi rör utdata till färre:
grep "ExtractParameters" *.c | less

Resultatet presenteras i mindre.
Detta låter dig bläddra igenom fillistan och använda less sökfunktion.
Om vi piper utdata från grep till wc och använder alternativet -l (linjer), vi kan räkna antalet rader i källkodsfilerna som innehåller ”ExtractParameters”. (Vi skulle kunna uppnå detta genom att använda alternativet grep -c (count), men det här är ett snyggt sätt att visa att grep utgår.)
grep "ExtractParameters" *.c | wc -l

Med nästa kommando överför vi utdata från ls till grep och piper utdata från grep till sort . Vi listar filerna i den aktuella katalogen och väljer de med strängen ”Aug” i dem, och sortera dem efter filstorlek:
ls -l | grep "Aug" | sort +4n
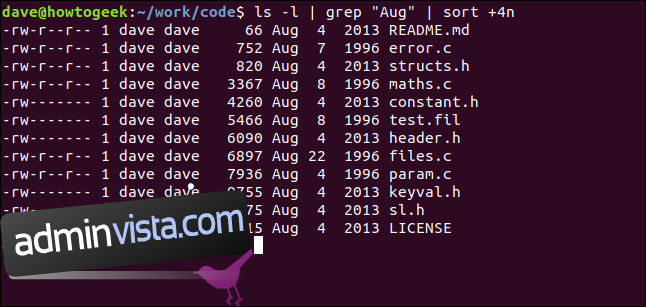
Låt oss bryta ner det:
ls -l: Utför en lång formatlista över filerna med hjälp av ls.
grep ”Aug”: Välj raderna från ls-listan som har ”Aug” i dem. Observera att detta också skulle hitta filer som har ”Aug” i sina namn.
sort +4n: Sortera utdata från grep i den fjärde kolumnen (filstorlek).
Vi får en sorterad lista över alla filer som ändrats i augusti (oavsett år), i stigande ordning efter filstorlek.
grep: Mindre ett kommando, mer av en allierad
grep är ett fantastiskt verktyg att ha till ditt förfogande. Den är från 1974 och är fortfarande stark eftersom vi behöver vad den gör, och ingenting gör den bättre.
Att koppla grep med några reguljära uttryck-fu tar det verkligen till nästa nivå.