

MapReduce erbjuder ett effektivt, snabbare och kostnadseffektivt sätt att skapa applikationer.
Denna modell använder avancerade koncept som parallell bearbetning, datalokalitet, etc., för att ge många fördelar för programmerare och organisationer.
Men det finns så många programmeringsmodeller och ramverk på marknaden att det blir svårt att välja.
Och när det kommer till Big Data kan du inte bara välja vad som helst. Du måste välja sådana tekniker som kan hantera stora bitar av data.
MapReduce är en bra lösning på det.
I den här artikeln kommer jag att diskutera vad MapReduce egentligen är och hur det kan vara till nytta.
Låt oss börja!
Innehållsförteckning
Vad är MapReduce?
MapReduce är en programmeringsmodell eller mjukvaruramverk inom Apache Hadoop-ramverket. Det används för att skapa applikationer som kan behandla massiva data parallellt på tusentals noder (kallade kluster eller rutnät) med feltolerans och tillförlitlighet.
Denna databehandling sker i en databas eller filsystem där data lagras. MapReduce kan arbeta med ett Hadoop File System (HDFS) för att komma åt och hantera stora datavolymer.
Detta ramverk introducerades 2004 av Google och populariseras av Apache Hadoop. Det är ett bearbetningslager eller motor i Hadoop som kör MapReduce-program utvecklade på olika språk, inklusive Java, C++, Python och Ruby.
MapReduce-programmen i cloud computing körs parallellt och är därför lämpliga för att utföra dataanalys i stor skala.
MapReduce syftar till att dela upp en uppgift i mindre, flera uppgifter med hjälp av funktionerna ”karta” och ”reducera”. Den kommer att kartlägga varje uppgift och sedan reducera den till flera likvärdiga uppgifter, vilket resulterar i mindre processorkraft och overhead på klusternätverket.
Exempel: Anta att du förbereder en måltid för ett hus fullt av gäster. Så om du försöker förbereda alla rätter och göra alla processer själv, kommer det att bli hektiskt och tidskrävande.
Men anta att du involverar några av dina vänner eller kollegor (inte gäster) för att hjälpa dig att förbereda måltiden genom att distribuera olika processer till en annan person som kan utföra uppgifterna samtidigt. I så fall förbereder du måltiden mycket snabbare och enklare medan dina gäster fortfarande är i huset.
MapReduce fungerar på liknande sätt med distribuerade uppgifter och parallell bearbetning för att möjliggöra ett snabbare och enklare sätt att slutföra en given uppgift.
Apache Hadoop tillåter programmerare att använda MapReduce för att exekvera modeller på stora distribuerade datamängder och använda avancerad maskininlärning och statistiska tekniker för att hitta mönster, göra förutsägelser, upptäcka korrelationer och mer.
Funktioner i MapReduce
Några av huvudfunktionerna i MapReduce är:
- Användargränssnitt: Du kommer att få ett intuitivt användargränssnitt som ger rimliga detaljer om varje ramaspekt. Det hjälper dig att konfigurera, tillämpa och justera dina uppgifter sömlöst.

- Nyttolast: Applikationer använder Mapper och Reducer-gränssnitt för att aktivera kartan och reducera funktioner. Mapparen mappar ingångsnyckel-värdepar till mellanliggande nyckel-värdepar. Reducer används för att reducera mellanliggande nyckel-värdepar som delar en nyckel till andra mindre värden. Den utför tre funktioner – sortera, blanda och reducera.
- Partitioner: Den styr uppdelningen av de mellanliggande kartutmatningsnycklarna.
- Reporter: Det är en funktion för att rapportera framsteg, uppdatera räknare och ställa in statusmeddelanden.
- Räknare: Det representerar globala räknare som en MapReduce-applikation definierar.
- OutputCollector: Denna funktion samlar in utdata från Mapper eller Reducer istället för mellanutgångar.
- RecordWriter: Den skriver datautdata eller nyckel-värdepar till utdatafilen.
- DistributedCache: Den distribuerar effektivt större, skrivskyddade filer som är applikationsspecifika.
- Datakomprimering: Applikationsskrivaren kan komprimera både jobbutdata och mellanliggande kartutdata.
- Dålig posthoppning: Du kan hoppa över flera dåliga poster medan du bearbetar dina kartinmatningar. Denna funktion kan styras genom klassen – SkipBadRecords.
- Felsökning: Du kommer att få möjlighet att köra användardefinierade skript och aktivera felsökning. Om en uppgift i MapReduce misslyckas kan du köra ditt felsökningsskript och hitta problemen.
MapReduce Architecture
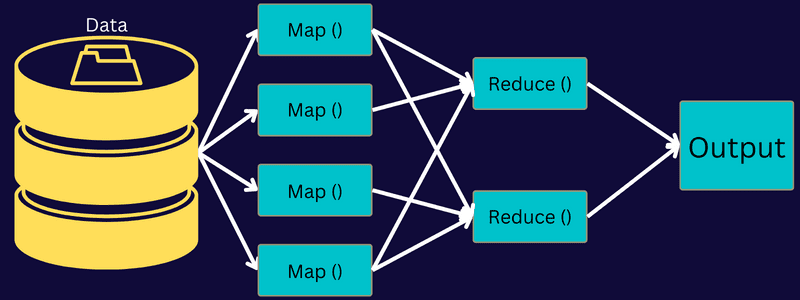
Låt oss förstå arkitekturen i MapReduce genom att gå djupare in i dess komponenter:
- Jobb: Ett jobb i MapReduce är den faktiska uppgift som MapReduce-klienten vill utföra. Den består av flera mindre uppgifter som tillsammans bildar den slutliga uppgiften.
- Jobbhistorikserver: Det är en demonprocess för att lagra och spara all historisk data om en applikation eller uppgift, till exempel loggar som genereras efter eller före exekvering av ett jobb.
- Klient: En klient (program eller API) tar med ett jobb till MapReduce för exekvering eller bearbetning. I MapReduce kan en eller flera klienter kontinuerligt skicka jobb till MapReduce Manager för bearbetning.
- MapReduce Master: En MapReduce Master delar upp ett jobb i flera mindre delar, vilket säkerställer att uppgifter fortskrider samtidigt.
- Jobbdelar: Underjobben eller jobbdelarna erhålls genom att dela upp det primära jobbet. De bearbetas och kombineras till slut för att skapa den slutliga uppgiften.
- Indata: Det är datamängden som matas till MapReduce för uppgiftsbearbetning.
- Utdata: Det är det slutliga resultatet som erhålls när uppgiften har bearbetats.
Så vad som verkligen händer i den här arkitekturen är att kunden skickar in ett jobb till MapReduce Master, som delar upp det i mindre, lika delar. Detta gör att jobbet kan bearbetas snabbare eftersom mindre uppgifter tar kortare tid att bearbeta istället för större uppgifter.
Se dock till att uppgifterna inte delas upp i för små uppgifter, för om du gör det kan du behöva möta en större omkostnad för att hantera splittringar och slösa bort mycket tid på det.
Därefter görs jobbdelarna tillgängliga för att fortsätta med kart- och reduceringsuppgifterna. Vidare har uppgifterna Karta och Förminska ett lämpligt program baserat på det användningsfall som teamet arbetar med. Programmeraren utvecklar den logikbaserade koden för att uppfylla kraven.
Efter detta matas indata till kartuppgiften så att kartan snabbt kan generera utdata som ett nyckel-värdepar. Istället för att lagra dessa data på HDFS, används en lokal disk för att lagra data för att eliminera risken för replikering.
När uppgiften är klar kan du slänga resultatet. Därför kommer replikering att bli en overkill när du lagrar utdata på HDFS. Utdata från varje kartuppgift kommer att matas till reduceringsuppgiften, och kartutdata kommer att tillhandahållas till maskinen som kör reduceringsuppgiften.
Därefter kommer utdata att slås samman och skickas till reduceringsfunktionen som definierats av användaren. Slutligen kommer den reducerade utmatningen att lagras på en HDFS.
Dessutom kan processen ha flera Map and Reduce-uppgifter för databehandling beroende på slutmålet. Map and Reduce-algoritmerna är optimerade för att hålla tids- eller rymdkomplexiteten minimal.
Eftersom MapReduce i första hand involverar Map- och Reduce-uppgifter, är det relevant att förstå mer om dem. Så låt oss diskutera faserna i MapReduce för att få en tydlig uppfattning om dessa ämnen.
Faser av MapReduce
Karta
Ingångsdata mappas till utdata- eller nyckel-värdeparen i denna fas. Här kan nyckeln referera till id för en adress medan värdet kan vara det faktiska värdet för den adressen.
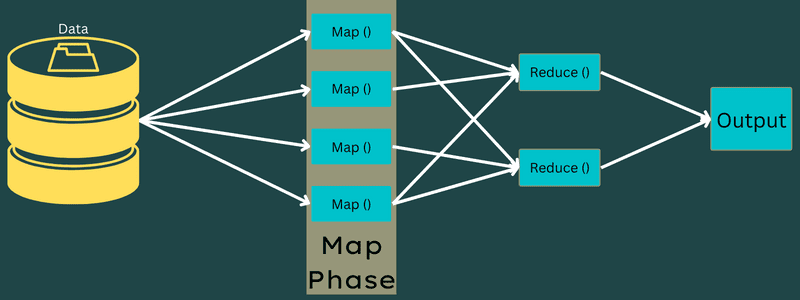
Det finns bara en men två uppgifter i denna fas – uppdelningar och kartläggning. Splits betyder deldelarna eller jobbdelarna uppdelade från huvudjobbet. Dessa kallas också för ingångsdelningar. Så en ingångsdelning kan kallas en ingångsbit som konsumeras av en karta.
Därefter sker kartläggningsuppgiften. Det anses vara den första fasen när man kör ett kartreduceringsprogram. Här kommer data som finns i varje split att skickas till en kartfunktion för att bearbeta och generera utdata.
Funktionen – Map() körs i minnesförrådet på de ingående nyckel-värde-paren, vilket genererar ett mellanliggande nyckel-värde-par. Detta nya nyckel-värdepar kommer att fungera som indata som ska matas till funktionen Reduce() eller Reducer.
Minska
De mellanliggande nyckel-värdeparen som erhålls i mappningsfasen fungerar som indata för funktionen Reducer eller Reducer. I likhet med kartläggningsfasen är två uppgifter inblandade – blanda och minska.
Så de erhållna nyckel-värdeparen sorteras och blandas för att matas till Reducer. Därefter grupperar eller aggregerar Reducer data enligt dess nyckel-värdepar baserat på reduceringsalgoritmen som utvecklaren har skrivit.
Här kombineras värdena från blandningsfasen för att returnera ett utdatavärde. Denna fas summerar hela datasetet.
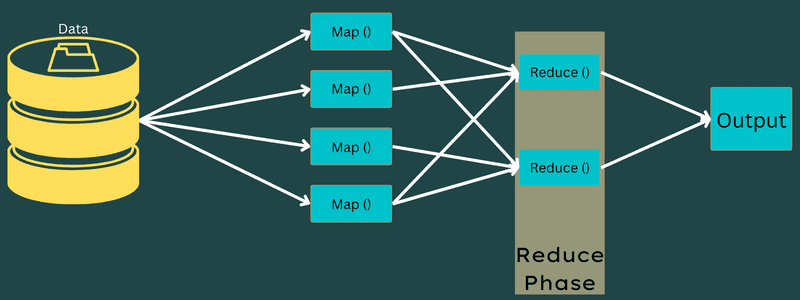
Nu kontrolleras hela processen för att köra Map and Reduce-uppgifter av vissa enheter. Dessa är:
- Jobbspårare: Med enkla ord fungerar en jobbspårare som en mästare som ansvarar för att utföra ett inskickat jobb helt. Jobbspåraren hanterar alla jobb och resurser i ett kluster. Dessutom schemalägger jobbspåraren varje karta som läggs till på uppgiftsspåraren som körs på en specifik datanod.
- Flera uppgiftsspårare: Med enkla ord fungerar flera uppgiftsspårare som slavar som utför uppgiften enligt instruktionerna från Job Tracker. En uppgiftsspårare är utplacerad på varje nod separat i klustret som utför Map- och Reduce-uppgifterna.
Det fungerar eftersom ett jobb kommer att delas upp i flera uppgifter som kommer att köras på olika datanoder från ett kluster. Jobbspåraren ansvarar för att koordinera uppgiften genom att schemalägga uppgifterna och köra dem på flera datanoder. Därefter utför uppgiftsspåraren som sitter på varje datanod delar av jobbet och ser efter varje uppgift.
Dessutom skickar uppgiftsspårarna lägesrapporter till jobbspåraren. Uppgiftsspåraren skickar också regelbundet en ”hjärtslag”-signal till jobbspåraren och meddelar dem om systemets status. I händelse av något misslyckande kan en jobbspårare schemalägga jobbet på en annan uppgiftsspårare.
Utdatafas: När du når den här fasen kommer du att ha de sista nyckel-värdeparen genererade från Reducer. Du kan använda en utdataformaterare för att översätta nyckel-värdeparen och skriva dem till en fil med hjälp av en skivskrivare.
Varför använda MapReduce?
Här är några av fördelarna med MapReduce, och förklarar varför du måste använda det i dina big data-applikationer:
Parallell bearbetning
Du kan dela upp ett jobb i olika noder där varje nod samtidigt hanterar en del av detta jobb i MapReduce. Så att dela upp större uppgifter i mindre minskar komplexiteten. Dessutom, eftersom olika uppgifter körs parallellt i olika maskiner istället för en enda maskin, tar det betydligt mindre tid att bearbeta data.
Datalokalitet
I MapReduce kan du flytta bearbetningsenheten till data, inte tvärtom.
På traditionellt sätt fördes uppgifterna till bearbetningsenheten för bearbetning. Men med den snabba tillväxten av data började denna process innebära många utmaningar. Några av dem var högre kostnader, mer tidskrävande, belastande av masternoden, frekventa fel och minskad nätverksprestanda.
Men MapReduce hjälper till att övervinna dessa problem genom att följa ett omvänt tillvägagångssätt – föra en bearbetningsenhet till data. På så sätt distribueras data mellan olika noder där varje nod kan bearbeta en del av den lagrade datan.
Som ett resultat ger det kostnadseffektivitet och minskar bearbetningstiden eftersom varje nod arbetar parallellt med sin motsvarande datadel. Dessutom, eftersom varje nod bearbetar en del av denna data, kommer ingen nod att vara överbelastad.
säkerhet

MapReduce-modellen erbjuder högre säkerhet. Det hjälper till att skydda din applikation från obehörig data samtidigt som klustersäkerheten förbättras.
Skalbarhet och flexibilitet
MapReduce är ett mycket skalbart ramverk. Det låter dig köra applikationer från flera maskiner, med hjälp av data med tusentals terabyte. Det erbjuder också flexibiliteten att bearbeta data som kan vara strukturerade, semi-strukturerade eller ostrukturerade och av alla format och storlekar.
Enkelhet
Du kan skriva MapReduce-program i alla programmeringsspråk som Java, R, Perl, Python och mer. Därför är det lätt för vem som helst att lära sig och skriva program samtidigt som man säkerställer att deras databehandlingskrav uppfylls.
Användningsfall av MapReduce
- Fulltextindexering: MapReduce används för att utföra fulltextindexering. Dess Mapper kan kartlägga varje ord eller fras i ett enda dokument. Och Reducer används för att skriva alla mappade element till ett index.
- Beräkna sidrankningen: Google använder MapReduce för att beräkna sidrankningen.
- Logganalys: MapReduce kan analysera loggfiler. Det kan dela upp en stor loggfil i olika delar eller dela upp medan kartläggaren söker efter tillgängliga webbsidor.
Ett nyckel-värdepar kommer att matas till reduceraren om en webbsida upptäcks i loggen. Här kommer webbsidan att vara nyckeln och indexet ”1” är värdet. Efter att ha gett ut ett nyckel-värdepar till Reducer, kommer olika webbsidor att samlas. Slutresultatet är det totala antalet träffar för varje webbsida.

- Omvänd webblänksgraf: Ramverket hittar också användning i omvänd webblänksgraf. Här ger Map() URL-målet och källan och tar input från källan eller webbsidan.
Därefter sammanställer Reduce() listan över varje källadress som är kopplad till måladressen. Slutligen matar den ut källorna och målet.
- Ordräkning: MapReduce används för att räkna hur många gånger ett ord förekommer i ett visst dokument.
- Global uppvärmning: Organisationer, regeringar och företag kan använda MapReduce för att lösa problem med global uppvärmning.
Till exempel kanske du vill veta om havets ökade temperaturnivå på grund av den globala uppvärmningen. För detta kan du samla in tusentals data över hela världen. Data kan vara hög temperatur, låg temperatur, latitud, longitud, datum, tid, etc. Detta kommer att ta flera kartor och minska uppgifter för att beräkna utdata med MapReduce.
- Läkemedelsförsök: Traditionellt arbetade datavetare och matematiker tillsammans för att formulera ett nytt läkemedel som kan bekämpa en sjukdom. Med spridning av algoritmer och MapReduce kan IT-avdelningar i organisationer enkelt ta itu med problem som endast hanterades av Supercomputers, Ph.D. vetenskapsmän, etc. Nu kan du inspektera effektiviteten av ett läkemedel för en grupp patienter.
- Andra applikationer: MapReduce kan bearbeta även storskalig data som annars inte passar i en relationsdatabas. Den använder också datavetenskapliga verktyg och gör det möjligt att köra dem över olika, distribuerade datamängder, vilket tidigare bara var möjligt på en enda dator.
Som ett resultat av MapReduces robusthet och enkelhet hittar den tillämpningar inom militären, näringslivet, vetenskapen, etc.
Slutsats
MapReduce kan visa sig vara ett teknikgenombrott. Det är inte bara en snabbare och enklare process utan också kostnadseffektiv och mindre tidskrävande. Med tanke på dess fördelar och ökande användning kommer den sannolikt att uppleva en högre användning inom branscher och organisationer.
Du kan också utforska några bästa resurser för att lära dig Big Data och Hadoop.