
Prometheus är ett statistikbaserat övervakningssystem med öppen källkod. Den samlar in data från tjänster och värdar genom att skicka HTTP-förfrågningar på mätvärdesändpunkter. Den lagrar sedan resultaten i en tidsseriedatabas och gör den tillgänglig för analys och larm.
Innehållsförteckning
Varför övervaka?
- Aktiverar varningar när saker går fel, helst innan de går fel. Så att någon kan titta på det.
- Det ger insikt för att möjliggöra analys, felsökning och lösning av problemet.
- Det gör att du kan se trender/förändringar över tid. Till exempel hur många aktiva sessioner vid en given tidpunkt. Detta hjälper till vid designbeslut och kapacitetsplanering.
Övervakning avser vanligtvis händelser. En händelse kan innefatta att ta emot en HTTP-förfrågan, skicka ett svar, läsa från disk, en användarinloggning. Övervakning av ett system kan innefatta profilering, loggning, spårning, mätvärden, varning och visualisering.
Blackbox vs Whitebox-övervakning
Övervakning delas in i två huvudkategorier:
Blackbox-övervakning
I Blackbox-övervakning sker övervakningen på applikations- eller värdnivå då de observeras utifrån. Detta kan vara ganska begränsande.
Whitebox-övervakning
Whitebox-övervakning innebär att övervaka det interna i en tjänst. Det skulle avslöja data om de interna komponenternas tillstånd och prestanda.
De fyra gyllene signalerna
Enligt Googleom du bara kan mäta fyra mätvärden för ditt användarinriktade system, fokusera på följande fyra, kallade de fyra gyllene signalerna:
#1. Latens
Tiden det tar att skicka en begäran – framgångsrik eller misslyckad. Det är viktigt att spåra inte bara lyckade förfrågningar utan även misslyckade.
#2. Trafik
Ett mått på hur mycket efterfrågan som ställs på ditt system. För en webbtjänst är detta vanligtvis HTTP-förfrågningar per sekund.
#3. Fel
Andelen förfrågningar som misslyckas.
#4. Mättnad
Hur full din tjänst är. Latensökning är ofta en viktig indikator på mättnad. Många system försämras i prestanda mycket innan de uppnår 100 % utnyttjande.
Prometheus-måtttyper
Prometheus-mått är av fyra huvudtyper:
#1. Disken
Värdet på en räknare kommer alltid att öka. Den kan aldrig minska, men den kan nollställas. Så om en skrapning misslyckas betyder det bara en missad datapunkt. Den kumulativa ökningen skulle vara tillgänglig vid nästa läsning. Exempel:
- Totalt antal mottagna HTTP-förfrågningar
- Antalet undantag.
#2. Mätare
En mätare är en ögonblicksbild vid en given tidpunkt. Det kan både öka eller minska. Om en datahämtning misslyckas förlorar du ett prov; nästa hämtning kan visa ett annat värde: exempel diskutrymme, minnesanvändning.
#3. Histogram
Ett histogram samplar observationer och räknar dem i konfigurerbara hinkar. De används för saker som förfrågningslängd eller svarsstorlekar. Du kan till exempel mäta förfrågans varaktighet för en specifik HTTP-förfrågan. Histogrammet kommer att ha en uppsättning hinkar, säg 1 ms, 10 ms och 25 ms. Istället för att lagra varje varaktighet för varje begäran, kommer Prometheus att lagra frekvensen av förfrågningar som faller i en viss hink.
#4. Sammanfattning
I likhet med histogramprovobservationer, begär vanligtvis varaktigheter eller svarsstorlekar. Det kommer att ge ett totalt antal observationer och en summa av alla observerade värden, så att du kan beräkna medelvärdet av observerade värden. Till exempel, på en minut hade du tre förfrågningar som tog 2,3,4 sekunder. Summan skulle vara 9 och antalet skulle vara 3. Latensen skulle vara 3 sekunder.
Komponenter i Prometheus ekosystem
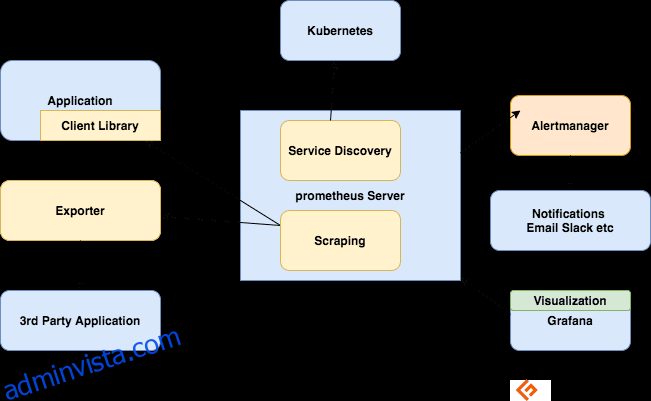
Prometheus-servern
Samlar in mätvärden, lagrar dem och gör dem tillgängliga för förfrågningar, skickar varningar baserat på de insamlade mätvärdena.
Skrapning
Prometheus är ett pull-baserat system. För att hämta mätvärden skickar Prometheus en HTTP-förfrågan som kallas en scrape. Den skickar skrapningar till mål baserat på dess konfiguration.
Varje mål (statiskt definierat eller dynamiskt upptäckt) skrapas med ett regelbundet intervall (skrapintervall). Varje skrapning läser /metrics HTTP-slutpunkten för att få det aktuella tillståndet för klientmätvärdena och behåller värdena i Prometheus tidsseriedatabase.
Det finns fler tidsseriedatabaser för övervakningslösningar som du kanske vill utforska.
Klientbibliotek
För att övervaka en tjänst måste du lägga till instrumentering i din kod. Det finns klientbibliotek tillgängliga för alla populära språk och körtider. När du använder dessa bibliotek kan din kod börja avge mätvärden när du har lagt till några rader kod. Detta kallas direkt instrumentering. Dessa bibliotek gör att du kan definiera interna mätvärden och även exponera dem via en HTTP-slutpunkt. När Prometheus skrapar måtten HTTP-slutpunkt, skickar klientbiblioteket mätvärdena till servern.
Officiella klientbibliotek erbjuds av Prometheus för Go, Java, Python och Ruby. Prometheus har ett öppet ekosystem. Det finns också communitybyggda klientbibliotek tillgängliga för C, PHP, Node.js, C#/.NET och många andra.
Exportörer
Många applikationer exponerar mätvärden i icke-Prometheus-format. För dessa och för applikationer som du inte äger eller som du inte har tillgång till kod för kan du inte lägga till instrumentering direkt. Till exempel MySQL, Kafka, JMX, HAProxy och NGINX server. I dessa scenarier använder du dig av exportörer.
En exportör är ett verktyg som du distribuerar tillsammans med applikationen du vill ha statistik från. En exportör fungerar som en proxy mellan applikationen och Prometheus. Den kommer att ta emot förfrågningar från Prometheus-servern, samla in data från åtkomstloggarna, felloggar för applikationen, omvandla den till rätt format och slutligen återgå till Prometheus-servern.
Några av de populära exportörerna är:
- Windows – för Windows-servermått
- Nod – för Linux-servermått
- Svart låda – för DNS- och webbplatsprestandastatistik
- JMX – för Java-baserad applikationsstatistik
När applikationerna har instrumenterats, eller exportörerna är på plats, måste du berätta för Prometheus var de är. Detta kan göras med statisk konfiguration. När det gäller dynamiska miljöer kan detta inte göras; därför används tjänsteupptäckt.
Varning
Varning med Prometheus består av två delar –
Varningsregler skickar varningar till Alertmanager.
Alertmanager hanterar sedan dessa varningar. Den skickar ut meddelanden med hjälp av många färdiga integrationer som e-post, Slack, Hipchat och PagerDuty. Alertmanager kan också utföra tystnad eller aggregering för att minska antalet aviseringar.
Här är guiden för att övervaka Linux-servern med Prometheus och Dashboard.
Visualisera med Dashboards
Prometheus har ett antal API:er som använder PromQL-frågor för att producera rådata för visualiseringar.
Även om Prometheus inkluderar en uttryckswebbläsare som kan användas för ad hoc-frågor, är det bästa tillgängliga verktyget Grafana. Grafana är helt integrerad med Prometheus och kan producera en mängd olika instrumentpaneler.
Du måste konfigurera Prometheus som datakälla för Grafana.
Du kan lägga till instrumentpaneler genom att:
- Importera community-byggda instrumentpaneler
- Bygg din egen
- Använda en fördefinierad instrumentpanel.
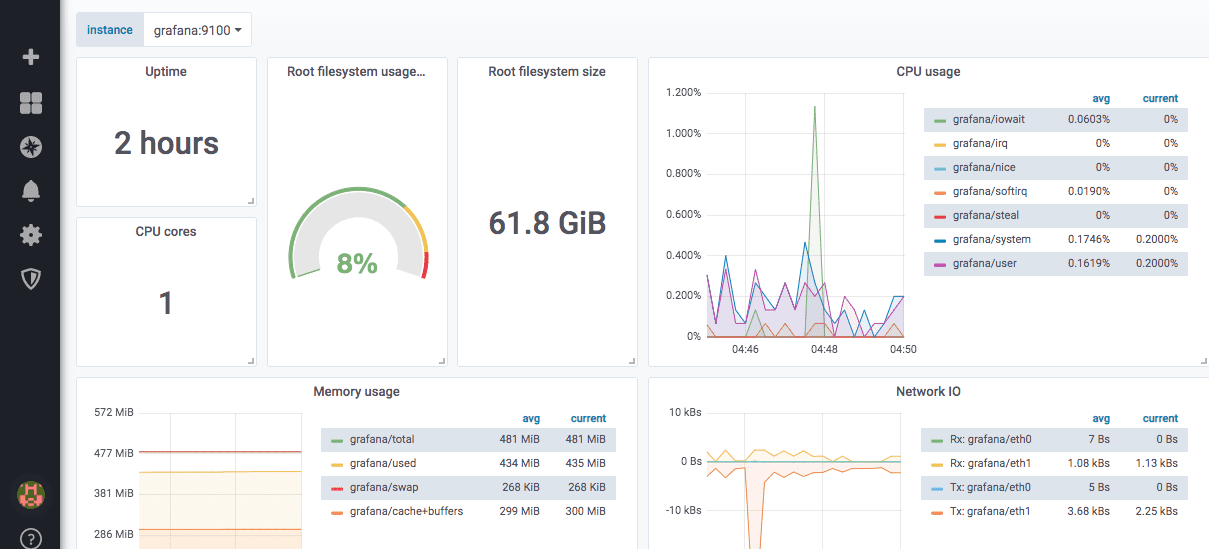
Så här ser en fördefinierad nodexportörinstrumentpanel ut:
Grafana har en worldPing-modul som låter dig övervaka webbplats- och DNS-prestandastatistik över hela världen.
Sammanfattning
Prometheus har väldigt få krav. Det kan vara ganska enkelt att köra eftersom det är en enda binär med en konfigurationsfil. Den kan hantera tusentals mål och få i sig miljontals prover per sekund. Prometheus är utformad för att spåra systemets övergripande system, hälsa, beteende.
Grafana är det bästa tillgängliga verktyget för visualisering av mätvärden och integreras sömlöst med Prometheus.