
Att bygga ett automatiserat mjukvarusystem innebar att sätta upp flera servrar med dedikerad CPU-konfiguration, minne, lagring och andra resurser under många år. Därefter bildades ett team av administratörer för att hantera dessa system. Sedan tog utvecklingsteamet över infrastrukturen och började skapa processer som kopplar samman servrarna.
Denna process kan vara komplicerad eftersom den involverar många olika grupper som arbetar tillsammans mot ett gemensamt mål. Dessa intressekonflikter kan då bli ett problem.
Det kan också bli ganska kostsamt. Detta kräver att du har administratörer på din lönelista. Servrar, som körs kontinuerligt, förbrukar resurser trots att de inte används.
För att bibehålla bästa prestanda över tid behöver du en automatisk skalningslösning som automatiskt skalar serverresurserna.
Molnplattformen har en fördel: den låter dig skapa en end-to-end-arkitektur utan att behöva konfigurera serverkluster. Ur ett förvaltningsperspektiv finns det inget att underhålla.
Detta är ett kostnadseffektivt alternativ för nystartade företag och faserna för minsta livskraftiga produkt (MVP) i projekt. Det är en bra utgångspunkt om det är svårt att förutse framtida produktionsbelastningar och användaraktivitet. Det är här det kan vara svårt att bestämma konfigurationen av klusterservrar.
Automatiseringen av processer genom serverlösa molntjänster är det som gör att serverlös arkitektur sticker ut. Den kopplar samman tjänster och ger resultat som liknar traditionella klusterservrar.
Detta är ett exempel på att bygga en sådan arkitektur med enbart inbyggda AWS-tjänster.
Innehållsförteckning
Plocka upp tjänsterna Serverlöst flöde
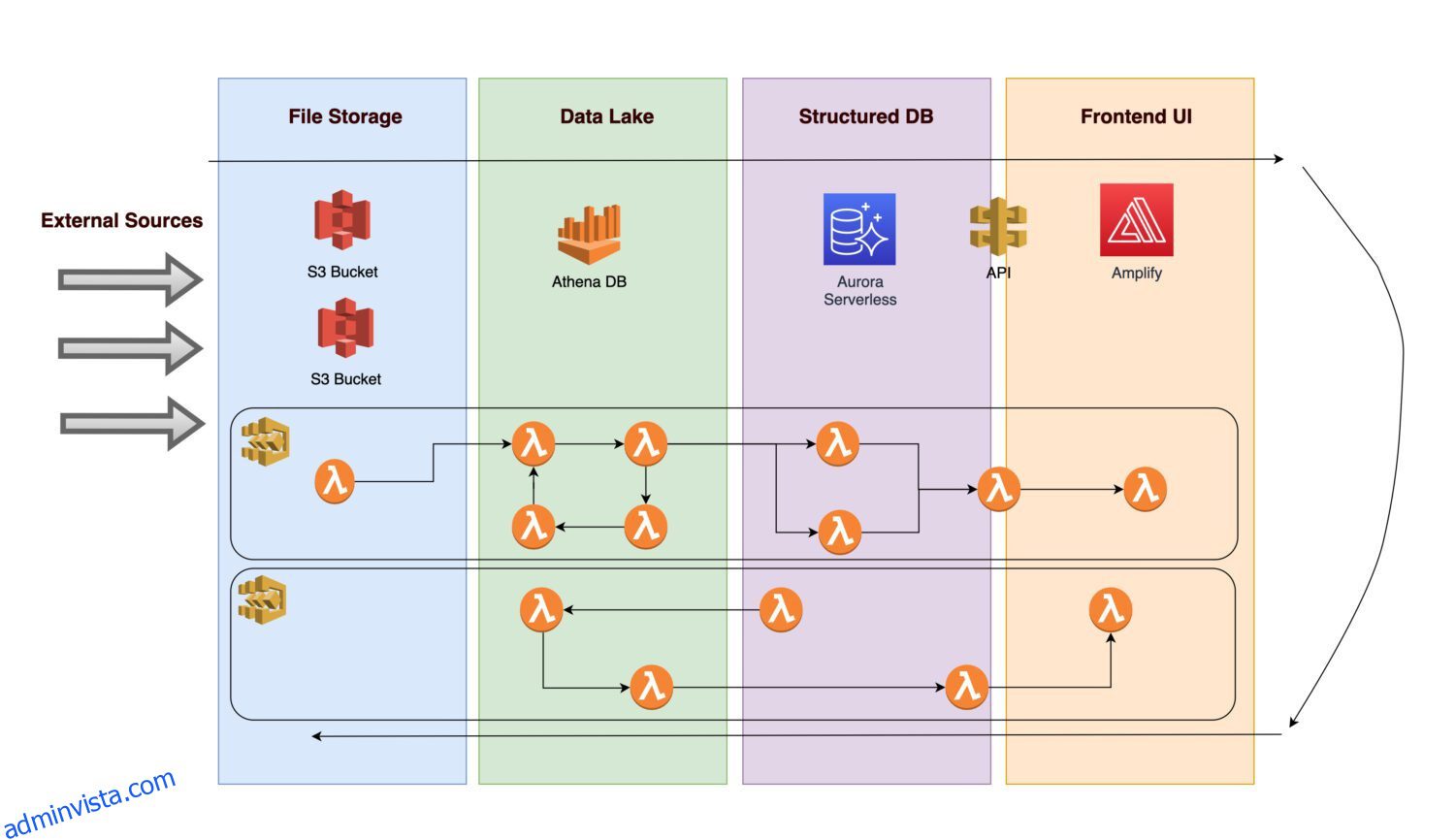
Föreställ dig att du skulle vilja skapa en plattform för att samla olika data och bilder (eller foton) av vissa konkreta tillgångars infrastruktur (detta kan vara vilken tillverknings- eller nyttotillgång som helst).
- För att göra framtida analyser möjlig är det nödvändigt att den inkommande datan först tas in.
- Efter tillämpning av affärsregler sparar en back-end-procedur de beräknade utdata som normaliserad information i en relationsdatabas.
- Ett applikationsgränssnitt som visar normaliserade rena data låter användare se resultaten.
Låt oss undersöka vilka komponenter arkitektur kan innehålla.
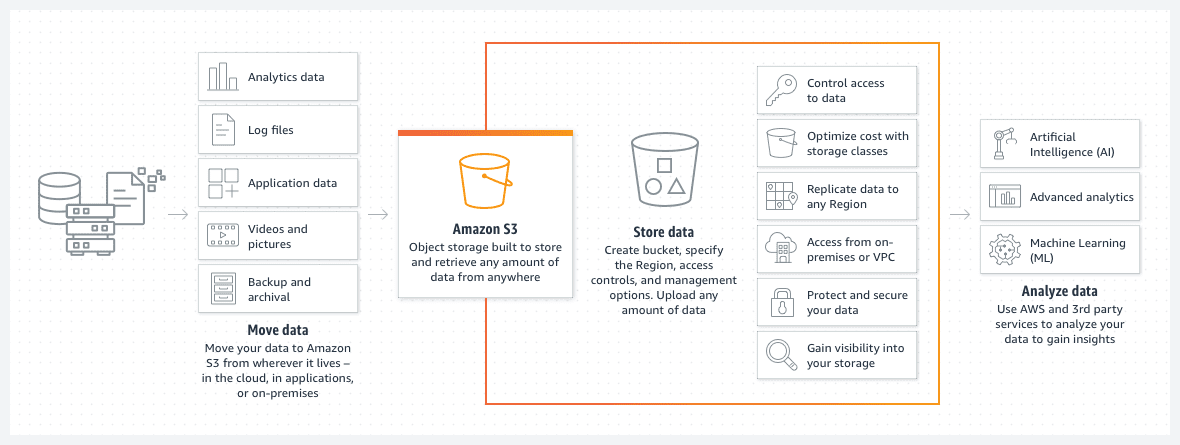
AWS S3 skopor
 Källa: aws.amazon.com
Källa: aws.amazon.com
Amazon S3-hinkar är ett utmärkt sätt att lagra filer eller bilder i AWS-molnet. Priset på förvaringen på S3-skopan är anmärkningsvärt lågt. Dessutom sänker introduktionen av en livscykelpolicy för S3-skopan detta pris ytterligare.
En sådan policy kommer automatiskt att flytta äldre filer till olika klasser av S3-segment, till exempel ett arkiv eller djup arkivåtkomst. Klasserna skiljer sig då också med hastigheten på åtkomsttiden, men för gammal data kommer detta att vara ett mindre problem. Det tjänar främst till att komma åt arkiverade data i händelse av en brådskande händelse snarare än för standarddriftbehov.
- Du kan organisera dina data i undermappar.
- Du bör ställa in lämpliga behörighetsbegränsningar.
- Lägg till taggar i segment för att göra dem enkla att identifiera och för möjlig användning inom dynamiska S3-segmentpolicyer.
- Skopan är serverlös till sin design. Det är helt enkelt ett lagringsutrymme för dina data.
En S3-skopa är serverlös till sin design. Det är helt enkelt ett lagringsutrymme för dina data.
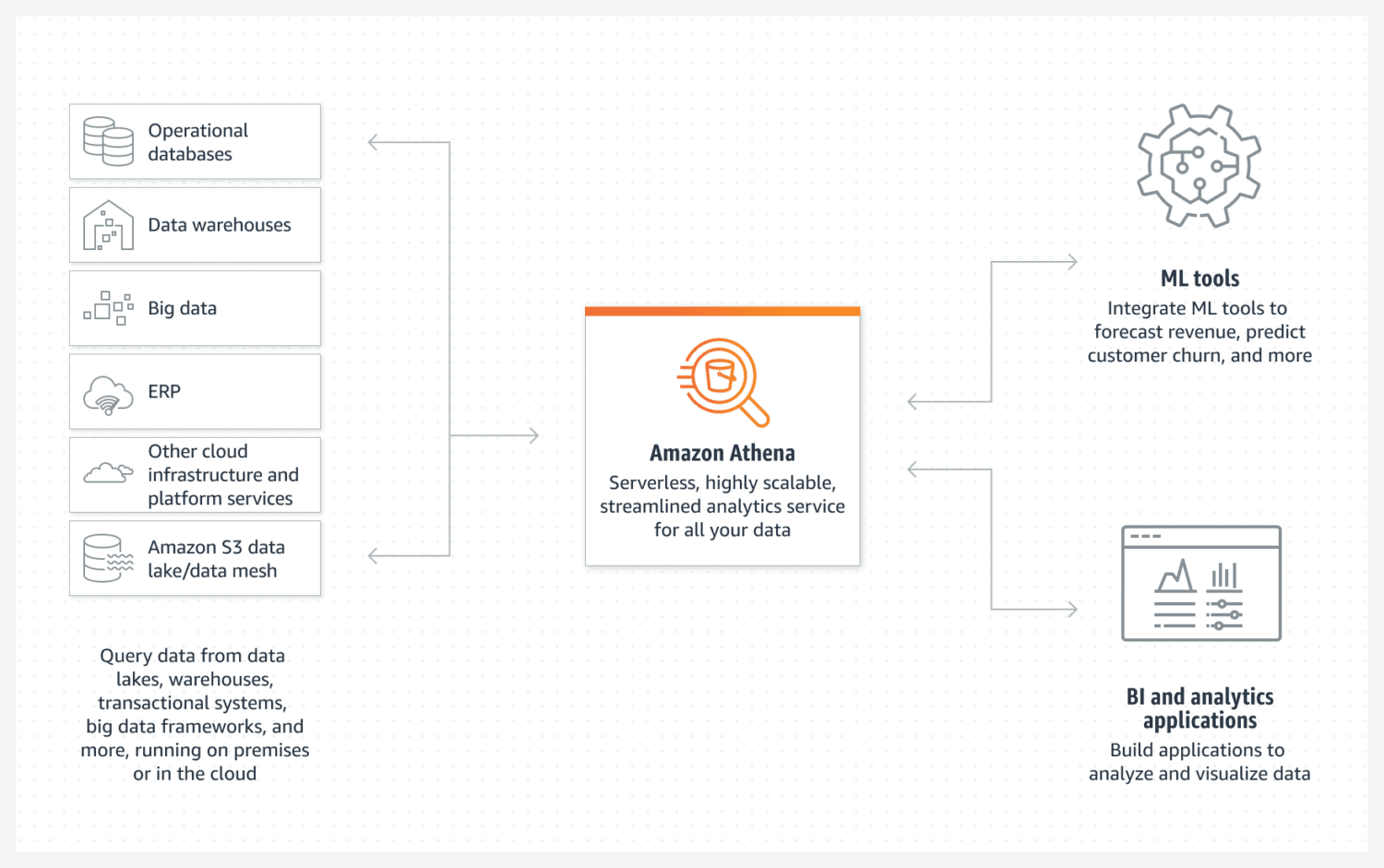
AWS Athena-databas
 Källa: aws.amazon.com
Källa: aws.amazon.com
Athena gör det enkelt att skapa en AWS-basdatasjö. Det är en databas utan servrar som använder en S3-hink för att lagra sina data. Dataorganisationen upprätthålls av strukturerade filformat som parkett eller CSV-filer (comma-separated value). S3-hinken innehåller filerna och Athena hänvisar till dem när processer väljer data från databasen.
Tänk bara på att Athena inte stöder olika funktioner som annars anses vara standard, till exempel uppdateringssatser. Det är därför du måste se Athena som ett mycket enkelt alternativ.
Det stöder dock indexering och partitionering. Det kan också skalas horisontellt mycket enkelt, eftersom detta är lika komplicerat som att lägga till nya skopor till infrastrukturen. För enkel men ändå funktionell datasjö kan detta ändå räcka i de flesta fall.
För bra prestanda är det viktigt att välja den bästa datadesignen med fokus på framtida användning. Det är viktigt att vara mycket tydlig med hur du vill välja data. Att återskapa tabeller senare när de redan finns och fyllda med massor av data är svårt.
Athena DB är ett utmärkt val och en bra passform för ditt mål om du vill skapa en enkel och oföränderlig datapool som är lätt att skala horisontellt över tid.
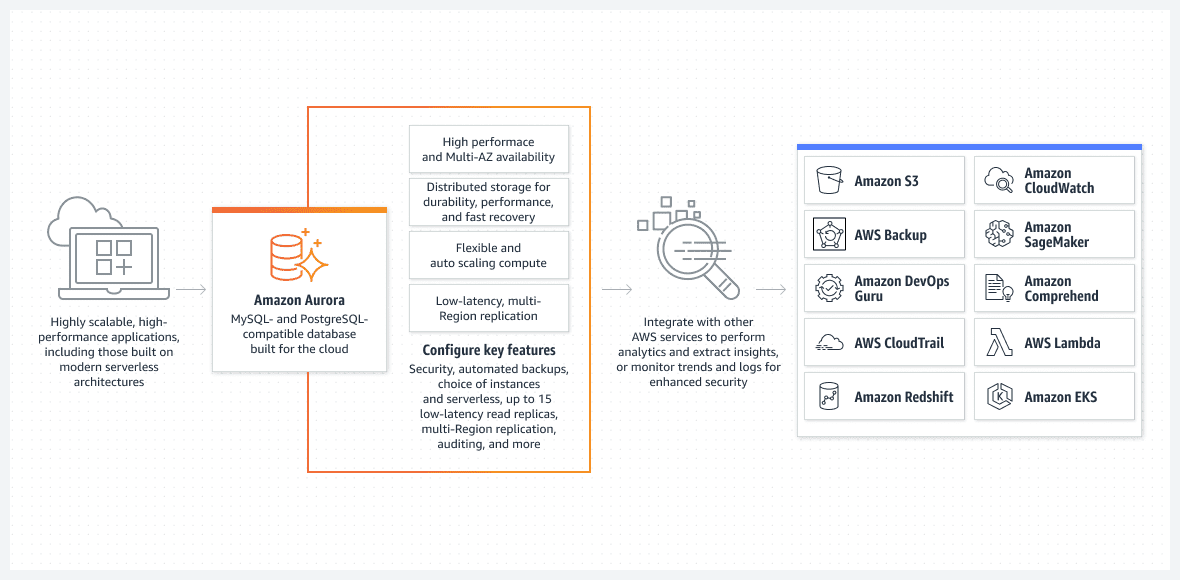
AWS Aurora Database
 Källa: aws.amazon.com
Källa: aws.amazon.com
Athena DB utmärker sig på att lagra okurerade data. Det är så här du vill lagra ditt ursprungliga innehåll för att maximera dess framtida återanvändning, trots allt. Det är dock långsamt att ge utvalda resultat till en front-end-app.
Ett av de bästa alternativen, främst ur ett perspektiv av lättkörda installationer, är Aurora-databasen som körs i serverlöst läge.
Aurora är långt ifrån en grundläggande databas. Det är en av de mest avancerade inbyggda relationsdatabaslösningarna i AWS. Det är också en mycket komplex inbyggd relationsdatabaslösning som förbättras med varje utgåva.
Aurora är unik eftersom den kan köras i serverlöst läge, vilket gör att den sticker ut från andra relationstjänster. Så här fungerar läget:
- För att konfigurera Aurora-klustret, använd AWS-konsolen. Du måste ange standardnivåerna för CPU och RAM samt det maximala intervallet för automatisk skalningsfunktion. Detta kommer att påverka prestandan som Aurora-klustret dynamiskt kan lägga till eller ta bort. Baserat på den aktuella användningen av databasen beslutar AWS sig för att skala upp eller ner.
- Aurora-klustret kommer inte att starta om inte användaren eller processen initierar en riktig begäran. Till exempel när den schemalagda batchbearbetningen startar. Eller om applikationen utför ett back-end API-anrop för att hämta data från en databas. Databasen öppnas automatiskt och kommer att förbli aktiv under en förutbestämd tid efter att förfrågningsprocesserna har slutförts.
- Aurora-klustret kommer automatiskt att stängas av om det inte finns mer arbete i databasen.
För att betona det en gång till, serverlösa Aurora DB körs bara när den måste göra riktigt arbete. Det automatiskt startade klustret kommer att stängas av igen om det inte bearbetar något arbete. Det faktiska arbetet är vad du betalar för och inte din lediga tid.
Den serverlösa Aurora hanteras helt av AWS och kräver ingen administratör.
AWS Amplify
Amplify erbjuder en serverlös plattform för snabb distribution av front-end-applikationer gjorda med JavaScript och React-bibliotek. Det finns inget behov av att konfigurera klusterservrar. Använd AWS-konsolen för att distribuera koden direkt, eller använd en automatiserad DevOps-pipeline.
Du kan anropa back-end API:er för att nå data som lagras i databaser. Dessa samtal låter dig komma åt de faktiska uppgifterna i front-end-applikationen. Den huvudsakliga optimeringen av prestanda på back-end bör göras av teamet. Du kan till och med minska möjligheten för långsam respons i användargränssnittet om du designar effektiva urvalssatser direkt i API-anropen.
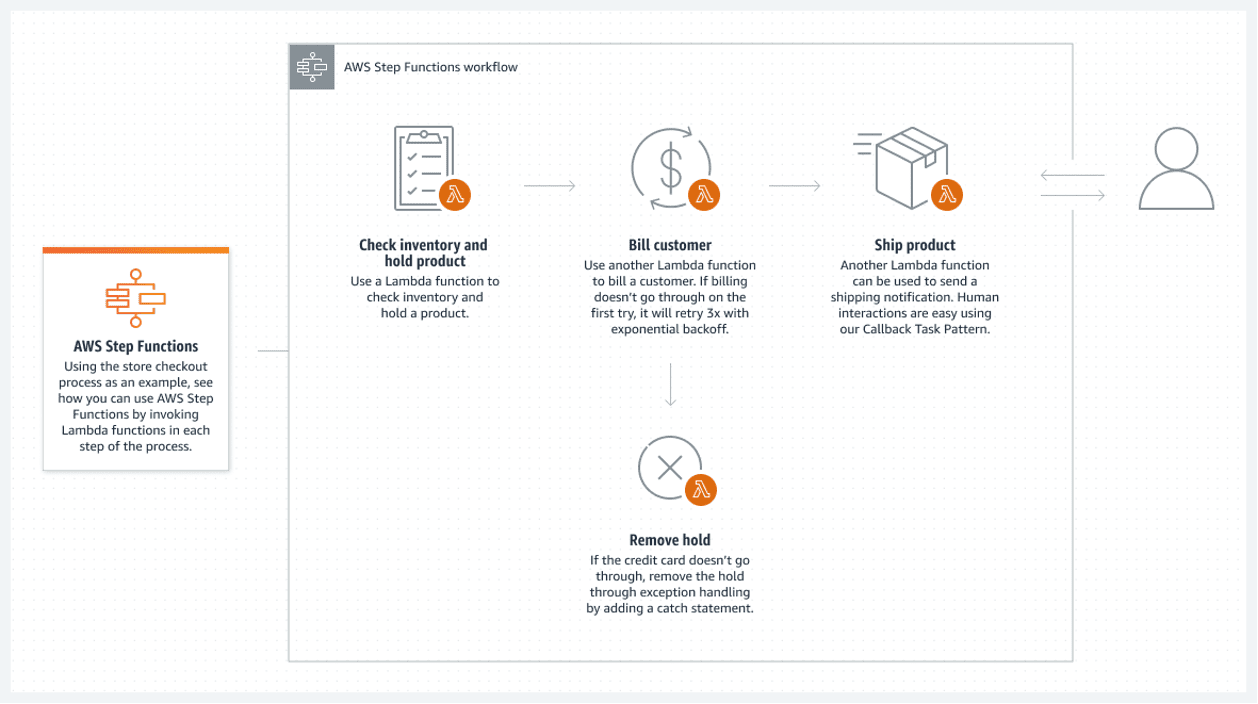
AWS stegfunktioner
 Källa: aws.amazon.com
Källa: aws.amazon.com
Även om alla huvudkomponenter i ett system är serverlösa, garanterar detta inte en helt serverlös arkitektur. Detta är endast möjligt om alla batchprocesser mellan komponenterna är serverlösa.
AWS Step-funktioner ger den bästa lösningen på AWS-molnet. En ansluten lista över AWS Lambda-funktioner utgör stegfunktionen. Dessa funktioner skapar ett flödesschema som har tydliga start- och sluttillstånd. En lambda-funktion, vanligtvis skriven i Python- eller Node JS-språk, är en körbar kodbit som bearbetar allt som behövs.
Följande är ett exempel på hur du kan utföra en stegfunktion:
Detta serverlösa flöde har en stor nackdel: varje lambdafunktion kan endast köras i 15 minuter som max. Att dela upp flödet i mindre lambdafunktioner kan därför göra detta mindre problematiskt.
Det är möjligt att anropa flera lambdafunktioner samtidigt i ett steg, vilket i princip innebär att parallellisera ett steg med flera lambda som körs samtidigt. Vänta bara tills all parallell lambdabehandling är klar innan du fortsätter. Fortsätt sedan till nästa lambdabehandling.
Slutord
Serverlös arkitektur erbjuder en unik möjlighet att skapa en molnplattform som täcker hela systemlandskapet. Denna plattform är horisontellt skalbar och har låga driftskostnader samtidigt som den gör det.
Det är den perfekta lösningen för projekt med begränsad budget. Det är ett utmärkt prospekteringsalternativ, vanligtvis när ingen känner till verkligheten av produktionsbelastningen. Detta är särskilt viktigt efter att du framgångsrikt har tagit med alla användare. Det är möjligt för projektgrupper att ändå få en helhetsbild av hur systemet fungerar. Du kan ha alla dessa fördelar och fortfarande inte behöva acceptera kompromisser.
Denna täckning kommer inte att vara tillräcklig för alla fall, särskilt de som involverar hög CPU-användning. AWS-molnet utvecklas dock ständigt när det gäller serverlösa användningsfall. Det är vanligtvis en bra idé att göra en grundlig forskning innan du bestämmer dig för det serverlösa alternativet för ditt nästa AWS-molnprojekt.
Kolla sedan in de bästa serverlösa databaserna för moderna applikationer.